Bitcoin Core integration/staging tree
https://bitcoincore.org
For an immediately usable, binary version of the Bitcoin Core software, see https://bitcoincore.org/en/download/.
What is Bitcoin Core?
Bitcoin Core connects to the Bitcoin peer-to-peer network to download and fully validate blocks and transactions. It also includes a wallet and graphical user interface, which can be optionally built.
Further information about Bitcoin Core is available in the doc folder.
License
Bitcoin Core is released under the terms of the MIT license. See COPYING for more information or see https://opensource.org/licenses/MIT.
Development Process
The master branch is regularly built (see doc/build-*.md for instructions) and tested, but it is not guaranteed to be
completely stable. Tags are created
regularly from release branches to indicate new official, stable release versions of Bitcoin Core.
The https://github.com/bitcoin-core/gui repository is used exclusively for the development of the GUI. Its master branch is identical in all monotree repositories. Release branches and tags do not exist, so please do not fork that repository unless it is for development reasons.
The contribution workflow is described in CONTRIBUTING.md and useful hints for developers can be found in doc/developer-notes.md.
Testing
Testing and code review is the bottleneck for development; we get more pull requests than we can review and test on short notice. Please be patient and help out by testing other people's pull requests, and remember this is a security-critical project where any mistake might cost people lots of money.
Automated Testing
Developers are strongly encouraged to write unit tests for new code, and to
submit new unit tests for old code. Unit tests can be compiled and run
(assuming they weren't disabled during the generation of the build system) with: ctest. Further details on running
and extending unit tests can be found in /src/test/README.md.
There are also regression and integration tests, written
in Python.
These tests can be run (if the test dependencies are installed) with: build/test/functional/test_runner.py
(assuming build is your build directory).
The CI (Continuous Integration) systems make sure that every pull request is built for Windows, Linux, and macOS, and that unit/sanity tests are run automatically.
Manual Quality Assurance (QA) Testing
Changes should be tested by somebody other than the developer who wrote the code. This is especially important for large or high-risk changes. It is useful to add a test plan to the pull request description if testing the changes is not straightforward.
Translations
Changes to translations as well as new translations can be submitted to Bitcoin Core's Transifex page.
Translations are periodically pulled from Transifex and merged into the git repository. See the translation process for details on how this works.
Important: We do not accept translation changes as GitHub pull requests because the next pull from Transifex would automatically overwrite them again.
Contributing to Bitcoin Core
The Bitcoin Core project operates an open contributor model where anyone is welcome to contribute towards development in the form of peer review, testing and patches. This document explains the practical process and guidelines for contributing.
First, in terms of structure, there is no particular concept of "Bitcoin Core developers" in the sense of privileged people. Open source often naturally revolves around a meritocracy where contributors earn trust from the developer community over time. Nevertheless, some hierarchy is necessary for practical purposes. As such, there are repository maintainers who are responsible for merging pull requests, the release cycle, and moderation.
Getting Started
New contributors are very welcome and needed.
Reviewing and testing is highly valued and the most effective way you can contribute as a new contributor. It also will teach you much more about the code and process than opening pull requests. Please refer to the peer review section below.
Before you start contributing, familiarize yourself with the Bitcoin Core build system and tests. Refer to the documentation in the repository on how to build Bitcoin Core and how to run the unit tests, functional tests, and fuzz tests.
There are many open issues of varying difficulty waiting to be fixed. If you're looking for somewhere to start contributing, check out the good first issue list or changes that are up for grabs. Some of them might no longer be applicable. So if you are interested, but unsure, you might want to leave a comment on the issue first.
You may also participate in the weekly Bitcoin Core PR Review Club meeting.
Good First Issue Label
The purpose of the good first issue label is to highlight which issues are
suitable for a new contributor without a deep understanding of the codebase.
However, good first issues can be solved by anyone. If they remain unsolved for a longer time, a frequent contributor might address them.
You do not need to request permission to start working on an issue. However, you are encouraged to leave a comment if you are planning to work on it. This will help other contributors monitor which issues are actively being addressed and is also an effective way to request assistance if and when you need it.
Communication Channels
Most communication about Bitcoin Core development happens on IRC, in the
#bitcoin-core-dev channel on Libera Chat. The easiest way to participate on IRC is
with the web client, web.libera.chat. Chat
history logs can be found
on https://www.erisian.com.au/bitcoin-core-dev/
and https://gnusha.org/bitcoin-core-dev/.
Discussion about codebase improvements happens in GitHub issues and pull requests.
The developer mailing list should be used to discuss complicated or controversial consensus or P2P protocol changes before working on a patch set. Archives can be found on https://gnusha.org/pi/bitcoindev/.
Contributor Workflow
The codebase is maintained using the "contributor workflow" where everyone without exception contributes patch proposals using "pull requests" (PRs). This facilitates social contribution, easy testing and peer review.
To contribute a patch, the workflow is as follows:
- Fork repository (only for the first time)
- Create topic branch
- Commit patches
For GUI-related issues or pull requests, the https://github.com/bitcoin-core/gui repository should be used. For all other issues and pull requests, the https://github.com/bitcoin/bitcoin node repository should be used.
The master branch for all monotree repositories is identical.
As a rule of thumb, everything that only modifies src/qt is a GUI-only pull
request. However:
- For global refactoring or other transversal changes the node repository should be used.
- For GUI-related build system changes, the node repository should be used because the change needs review by the build systems reviewers.
- Changes in
src/interfacesneed to go to the node repository because they might affect other components like the wallet.
For large GUI changes that include build system and interface changes, it is recommended to first open a pull request against the GUI repository. When there is agreement to proceed with the changes, a pull request with the build system and interfaces changes can be submitted to the node repository.
The project coding conventions in the developer notes must be followed.
Committing Patches
In general, commits should be atomic and diffs should be easy to read. For this reason, do not mix any formatting fixes or code moves with actual code changes.
Make sure each individual commit is hygienic: that it builds successfully on its own without warnings, errors, regressions, or test failures.
Commit messages should be verbose by default consisting of a short subject line (50 chars max), a blank line and detailed explanatory text as separate paragraph(s), unless the title alone is self-explanatory (like "Correct typo in init.cpp") in which case a single title line is sufficient. Commit messages should be helpful to people reading your code in the future, so explain the reasoning for your decisions. Further explanation here.
If a particular commit references another issue, please add the reference. For
example: refs #1234 or fixes #4321. Using the fixes or closes keywords
will cause the corresponding issue to be closed when the pull request is merged.
Commit messages should never contain any @ mentions (usernames prefixed with "@").
Please refer to the Git manual for more information about Git.
- Push changes to your fork
- Create pull request
Creating the Pull Request
The title of the pull request should be prefixed by the component or area that the pull request affects. Valid areas as:
consensusfor changes to consensus critical codedocfor changes to the documentationqtorguifor changes to bitcoin-qtlogfor changes to log messagesminingfor changes to the mining codenetorp2pfor changes to the peer-to-peer network coderefactorfor structural changes that do not change behaviorrpc,restorzmqfor changes to the RPC, REST or ZMQ APIscontriborclifor changes to the scripts and toolstest,qaorcifor changes to the unit tests, QA tests or CI codeutilorlibfor changes to the utils or librarieswalletfor changes to the wallet codebuildfor changes to CMakeguixfor changes to the GUIX reproducible builds
Examples:
consensus: Add new opcode for BIP-XXXX OP_CHECKAWESOMESIG
net: Automatically create onion service, listen on Tor
qt: Add feed bump button
log: Fix typo in log message
The body of the pull request should contain sufficient description of what the patch does, and even more importantly, why, with justification and reasoning. You should include references to any discussions (for example, other issues or mailing list discussions).
The description for a new pull request should not contain any @ mentions. The
PR description will be included in the commit message when the PR is merged and
any users mentioned in the description will be annoyingly notified each time a
fork of Bitcoin Core copies the merge. Instead, make any username mentions in a
subsequent comment to the PR.
Translation changes
Note that translations should not be submitted as pull requests. Please see Translation Process for more information on helping with translations.
Work in Progress Changes and Requests for Comments
If a pull request is not to be considered for merging (yet), please prefix the title with [WIP] or use Tasks Lists in the body of the pull request to indicate tasks are pending.
Address Feedback
At this stage, one should expect comments and review from other contributors. You can add more commits to your pull request by committing them locally and pushing to your fork.
You are expected to reply to any review comments before your pull request is merged. You may update the code or reject the feedback if you do not agree with it, but you should express so in a reply. If there is outstanding feedback and you are not actively working on it, your pull request may be closed.
Please refer to the peer review section below for more details.
Squashing Commits
If your pull request contains fixup commits (commits that change the same line of code repeatedly) or too fine-grained commits, you may be asked to squash your commits before it will be reviewed. The basic squashing workflow is shown below.
git checkout your_branch_name
git rebase -i HEAD~n
# n is normally the number of commits in the pull request.
# Set commits (except the one in the first line) from 'pick' to 'squash', save and quit.
# On the next screen, edit/refine commit messages.
# Save and quit.
git push -f # (force push to GitHub)
Please update the resulting commit message, if needed. It should read as a coherent message. In most cases, this means not just listing the interim commits.
If your change contains a merge commit, the above workflow may not work and you will need to remove the merge commit first. See the next section for details on how to rebase.
Please refrain from creating several pull requests for the same change. Use the pull request that is already open (or was created earlier) to amend changes. This preserves the discussion and review that happened earlier for the respective change set.
The length of time required for peer review is unpredictable and will vary from pull request to pull request.
Rebasing Changes
When a pull request conflicts with the target branch, you may be asked to rebase it on top of the current target branch.
git fetch https://github.com/bitcoin/bitcoin # Fetch the latest upstream commit
git rebase FETCH_HEAD # Rebuild commits on top of the new base
This project aims to have a clean git history, where code changes are only made in non-merge commits. This simplifies auditability because merge commits can be assumed to not contain arbitrary code changes. Merge commits should be signed, and the resulting git tree hash must be deterministic and reproducible. The script in /contrib/verify-commits checks that.
After a rebase, reviewers are encouraged to sign off on the force push. This should be relatively straightforward with
the git range-diff tool explained in the productivity
notes. To avoid needless review churn, maintainers will
generally merge pull requests that received the most review attention first.
Pull Request Philosophy
Patchsets should always be focused. For example, a pull request could add a feature, fix a bug, or refactor code; but not a mixture. Please also avoid super pull requests which attempt to do too much, are overly large, or overly complex as this makes review difficult.
Features
When adding a new feature, thought must be given to the long term technical debt and maintenance that feature may require after inclusion. Before proposing a new feature that will require maintenance, please consider if you are willing to maintain it (including bug fixing). If features get orphaned with no maintainer in the future, they may be removed by the Repository Maintainer.
Refactoring
Refactoring is a necessary part of any software project's evolution. The following guidelines cover refactoring pull requests for the project.
There are three categories of refactoring: code-only moves, code style fixes, and code refactoring. In general, refactoring pull requests should not mix these three kinds of activities in order to make refactoring pull requests easy to review and uncontroversial. In all cases, refactoring PRs must not change the behaviour of code within the pull request (bugs must be preserved as is).
Project maintainers aim for a quick turnaround on refactoring pull requests, so where possible keep them short, uncomplex and easy to verify.
Pull requests that refactor the code should not be made by new contributors. It requires a certain level of experience to know where the code belongs to and to understand the full ramification (including rebase effort of open pull requests).
Trivial pull requests or pull requests that refactor the code with no clear benefits may be immediately closed by the maintainers to reduce unnecessary workload on reviewing.
"Decision Making" Process
The following applies to code changes to the Bitcoin Core project (and related projects such as libsecp256k1), and is not to be confused with overall Bitcoin Network Protocol consensus changes.
Whether a pull request is merged into Bitcoin Core rests with the project merge maintainers.
Maintainers will take into consideration if a patch is in line with the general principles of the project; meets the minimum standards for inclusion; and will judge the general consensus of contributors.
In general, all pull requests must:
- Have a clear use case, fix a demonstrable bug or serve the greater good of the project (for example refactoring for modularisation);
- Be well peer-reviewed;
- Have unit tests, functional tests, and fuzz tests, where appropriate;
- Follow code style guidelines (C++, functional tests);
- Not break the existing test suite;
- Where bugs are fixed, where possible, there should be unit tests demonstrating the bug and also proving the fix. This helps prevent regression.
- Change relevant comments and documentation when behaviour of code changes.
Patches that change Bitcoin consensus rules are considerably more involved than normal because they affect the entire ecosystem and so must be preceded by extensive mailing list discussions and have a numbered BIP. While each case will be different, one should be prepared to expend more time and effort than for other kinds of patches because of increased peer review and consensus building requirements.
Peer Review
Anyone may participate in peer review which is expressed by comments in the pull request. Typically reviewers will review the code for obvious errors, as well as test out the patch set and opine on the technical merits of the patch. Project maintainers take into account the peer review when determining if there is consensus to merge a pull request (remember that discussions may have been spread out over GitHub, mailing list and IRC discussions).
Code review is a burdensome but important part of the development process, and as such, certain types of pull requests are rejected. In general, if the improvements do not warrant the review effort required, the PR has a high chance of being rejected. It is up to the PR author to convince the reviewers that the changes warrant the review effort, and if reviewers are "Concept NACK'ing" the PR, the author may need to present arguments and/or do research backing their suggested changes.
Conceptual Review
A review can be a conceptual review, where the reviewer leaves a comment
Concept (N)ACK, meaning "I do (not) agree with the general goal of this pull request",Approach (N)ACK, meaningConcept ACK, but "I do (not) agree with the approach of this change".
A NACK needs to include a rationale why the change is not worthwhile.
NACKs without accompanying reasoning may be disregarded.
Code Review
After conceptual agreement on the change, code review can be provided. A review
begins with ACK BRANCH_COMMIT, where BRANCH_COMMIT is the top of the PR
branch, followed by a description of how the reviewer did the review. The
following language is used within pull request comments:
- "I have tested the code", involving change-specific manual testing in addition to running the unit, functional, or fuzz tests, and in case it is not obvious how the manual testing was done, it should be described;
- "I have not tested the code, but I have reviewed it and it looks OK, I agree it can be merged";
- A "nit" refers to a trivial, often non-blocking issue.
Project maintainers reserve the right to weigh the opinions of peer reviewers using common sense judgement and may also weigh based on merit. Reviewers that have demonstrated a deeper commitment and understanding of the project over time or who have clear domain expertise may naturally have more weight, as one would expect in all walks of life.
Where a patch set affects consensus-critical code, the bar will be much higher in terms of discussion and peer review requirements, keeping in mind that mistakes could be very costly to the wider community. This includes refactoring of consensus-critical code.
Where a patch set proposes to change the Bitcoin consensus, it must have been discussed extensively on the mailing list and IRC, be accompanied by a widely discussed BIP and have a generally widely perceived technical consensus of being a worthwhile change based on the judgement of the maintainers.
Finding Reviewers
As most reviewers are themselves developers with their own projects, the review process can be quite lengthy, and some amount of patience is required. If you find that you've been waiting for a pull request to be given attention for several months, there may be a number of reasons for this, some of which you can do something about:
- It may be because of a feature freeze due to an upcoming release. During this time, only bug fixes are taken into consideration. If your pull request is a new feature, it will not be prioritized until after the release. Wait for the release.
- It may be because the changes you are suggesting do not appeal to people. Rather than nits and critique, which require effort and means they care enough to spend time on your contribution, thundering silence is a good sign of widespread (mild) dislike of a given change (because people don't assume others won't actually like the proposal). Don't take that personally, though! Instead, take another critical look at what you are suggesting and see if it: changes too much, is too broad, doesn't adhere to the developer notes, is dangerous or insecure, is messily written, etc. Identify and address any of the issues you find. Then ask e.g. on IRC if someone could give their opinion on the concept itself.
- It may be because your code is too complex for all but a few people, and those people may not have realized your pull request even exists. A great way to find people who are qualified and care about the code you are touching is the Git Blame feature. Simply look up who last modified the code you are changing and see if you can find them and give them a nudge. Don't be incessant about the nudging, though.
- Finally, if all else fails, ask on IRC or elsewhere for someone to give your pull request a look. If you think you've been waiting for an unreasonably long time (say, more than a month) for no particular reason (a few lines changed, etc.), this is totally fine. Try to return the favor when someone else is asking for feedback on their code, and the universe balances out.
- Remember that the best thing you can do while waiting is give review to others!
Backporting
Security and bug fixes can be backported from master to release
branches.
Maintainers will do backports in batches and
use the proper Needs backport (...) labels
when needed (the original author does not need to worry about it).
A backport should contain the following metadata in the commit body:
Github-Pull: #<PR number>
Rebased-From: <commit hash of the original commit>
Have a look at an example backport PR.
Also see the backport.py script.
Copyright
By contributing to this repository, you agree to license your work under the
MIT license unless specified otherwise in contrib/debian/copyright or at
the top of the file itself. Any work contributed where you are not the original
author must contain its license header with the original author(s) and source.
See doc/build-*.md
Security Policy
Supported Versions
See our website for versions of Bitcoin Core that are currently supported with security updates: https://bitcoincore.org/en/lifecycle/#schedule
Reporting a Vulnerability
To report security issues send an email to security@bitcoincore.org (not for support).
The following keys may be used to communicate sensitive information to developers:
| Name | Fingerprint |
|---|---|
| Pieter Wuille | 133E AC17 9436 F14A 5CF1 B794 860F EB80 4E66 9320 |
| Michael Ford | E777 299F C265 DD04 7930 70EB 944D 35F9 AC3D B76A |
| Ava Chow | 1528 1230 0785 C964 44D3 334D 1756 5732 E08E 5E41 |
You can import a key by running the following command with that individual’s fingerprint: gpg --keyserver hkps://keys.openpgp.org --recv-keys "<fingerprint>" Ensure that you put quotes around fingerprints containing spaces.
CI Scripts
This directory contains scripts for each build step in each build stage.
Running a Stage Locally
Be aware that the tests will be built and run in-place, so please run at your own risk. If the repository is not a fresh git clone, you might have to clean files from previous builds or test runs first.
The ci needs to perform various sysadmin tasks such as installing packages or writing to the user's home directory. While it should be fine to run the ci system locally on you development box, the ci scripts can generally be assumed to have received less review and testing compared to other parts of the codebase. If you want to keep the work tree clean, you might want to run the ci system in a virtual machine with a Linux operating system of your choice.
To allow for a wide range of tested environments, but also ensure reproducibility to some extent, the test stage
requires bash, docker, and python3 to be installed. To run on different architectures than the host qemu is also required. To install all requirements on Ubuntu, run
sudo apt install bash docker.io python3 qemu-user-static
It is recommended to run the ci system in a clean env. To run the test stage with a specific configuration,
env -i HOME="$HOME" PATH="$PATH" USER="$USER" bash -c 'FILE_ENV="./ci/test/00_setup_env_arm.sh" ./ci/test_run_all.sh'
Configurations
The test files (FILE_ENV) are constructed to test a wide range of
configurations, rather than a single pass/fail. This helps to catch build
failures and logic errors that present on platforms other than the ones the
author has tested.
Some builders use the dependency-generator in ./depends, rather than using
the system package manager to install build dependencies. This guarantees that
the tester is using the same versions as the release builds, which also use
./depends.
It is also possible to force a specific configuration without modifying the file. For example,
env -i HOME="$HOME" PATH="$PATH" USER="$USER" bash -c 'MAKEJOBS="-j1" FILE_ENV="./ci/test/00_setup_env_arm.sh" ./ci/test_run_all.sh'
The files starting with 0n (n greater than 0) are the scripts that are run
in order.
Cache
In order to avoid rebuilding all dependencies for each build, the binaries are cached and reused when possible. Changes in the dependency-generator will trigger cache-invalidation and rebuilds as necessary.
retry - The command line retry tool
Retry any shell command with exponential backoff or constant delay.
Instructions
Install:
retry is a shell script, so drop it somewhere and make sure it's added to your $PATH. Or you can use the following one-liner:
sudo sh -c "curl https://raw.githubusercontent.com/kadwanev/retry/master/retry -o /usr/local/bin/retry && chmod +x /usr/local/bin/retry"
If you're on OS X, retry is also on Homebrew:
brew pull 27283
brew install retry
Not popular enough for homebrew-core. Please star this project to help.
Usage
Help:
retry -?
Usage: retry [options] -- execute command
-h, -?, --help
-v, --verbose Verbose output
-t, --tries=# Set max retries: Default 10
-s, --sleep=secs Constant sleep amount (seconds)
-m, --min=secs Exponential Backoff: minimum sleep amount (seconds): Default 0.3
-x, --max=secs Exponential Backoff: maximum sleep amount (seconds): Default 60
-f, --fail="script +cmds" Fail Script: run in case of final failure
Examples
No problem:
retry echo u work good
u work good
Test functionality:
retry 'echo "y u no work"; false'
y u no work
Before retry #1: sleeping 0.3 seconds
y u no work
Before retry #2: sleeping 0.6 seconds
y u no work
Before retry #3: sleeping 1.2 seconds
y u no work
Before retry #4: sleeping 2.4 seconds
y u no work
Before retry #5: sleeping 4.8 seconds
y u no work
Before retry #6: sleeping 9.6 seconds
y u no work
Before retry #7: sleeping 19.2 seconds
y u no work
Before retry #8: sleeping 38.4 seconds
y u no work
Before retry #9: sleeping 60.0 seconds
y u no work
Before retry #10: sleeping 60.0 seconds
y u no work
etc..
Limit retries:
retry -t 4 'echo "y u no work"; false'
y u no work
Before retry #1: sleeping 0.3 seconds
y u no work
Before retry #2: sleeping 0.6 seconds
y u no work
Before retry #3: sleeping 1.2 seconds
y u no work
Before retry #4: sleeping 2.4 seconds
y u no work
Retries exhausted
Bad command:
retry poop
bash: poop: command not found
Fail command:
retry -t 3 -f 'echo "oh poopsickles"' 'echo "y u no work"; false'
y u no work
Before retry #1: sleeping 0.3 seconds
y u no work
Before retry #2: sleeping 0.6 seconds
y u no work
Before retry #3: sleeping 1.2 seconds
y u no work
Retries exhausted, running fail script
oh poopsickles
Last attempt passed:
retry -t 3 -- 'if [ $RETRY_ATTEMPT -eq 3 ]; then echo Passed at attempt $RETRY_ATTEMPT; true; else echo Failed at attempt $RETRY_ATTEMPT; false; fi;'
Failed at attempt 0
Before retry #1: sleeping 0.3 seconds
Failed at attempt 1
Before retry #2: sleeping 0.6 seconds
Failed at attempt 2
Before retry #3: sleeping 1.2 seconds
Passed at attempt 3
License
Apache 2.0 - go nuts
Repository Tools
Developer tools
Specific tools for developers working on this repository.
Additional tools, including the github-merge.py script, are available in the maintainer-tools repository.
Verify-Commits
Tool to verify that every merge commit was signed by a developer using the github-merge.py script.
Linearize
Construct a linear, no-fork, best version of the blockchain.
Qos
A Linux bash script that will set up traffic control (tc) to limit the outgoing bandwidth for connections to the Bitcoin network. This means one can have an always-on bitcoind instance running, and another local bitcoind/bitcoin-qt instance which connects to this node and receives blocks from it.
Seeds
Utility to generate the pnSeed[] array that is compiled into the client.
Build Tools and Keys
Packaging
The Debian subfolder contains the copyright file.
All other packaging related files can be found in the bitcoin-core/packaging repository.
MacDeploy
Scripts and notes for Mac builds.
Test and Verify Tools
TestGen
Utilities to generate test vectors for the data-driven Bitcoin tests.
Verify-Binaries
This script attempts to download and verify the signature file SHA256SUMS.asc from bitcoin.org.
Command Line Tools
Completions
Shell completions for bash and fish.
ASMap Tool
Tool for performing various operations on textual and binary asmap files,
particularly encoding/compressing the raw data to the binary format that can
be used in Bitcoin Core with the -asmap option.
Example usage:
python3 asmap-tool.py encode /path/to/input.file /path/to/output.file
python3 asmap-tool.py decode /path/to/input.file /path/to/output.file
python3 asmap-tool.py diff /path/to/first.file /path/to/second.file
Contents
This directory contains tools for developers working on this repository.
clang-format-diff.py
A script to format unified git diffs according to .clang-format.
Requires clang-format, installed e.g. via brew install clang-format on macOS,
or sudo apt install clang-format on Debian/Ubuntu.
For instance, to format the last commit with 0 lines of context, the script should be called from the git root folder as follows.
git diff -U0 HEAD~1.. | ./contrib/devtools/clang-format-diff.py -p1 -i -v
copyright_header.py
Provides utilities for managing copyright headers of The Bitcoin Core developers in repository source files. It has three subcommands:
$ ./copyright_header.py report <base_directory> [verbose]
$ ./copyright_header.py update <base_directory>
$ ./copyright_header.py insert <file>
Running these subcommands without arguments displays a usage string.
copyright_header.py report <base_directory> [verbose]
Produces a report of all copyright header notices found inside the source files
of a repository. Useful to quickly visualize the state of the headers.
Specifying verbose will list the full filenames of files of each category.
copyright_header.py update <base_directory> [verbose]
Updates all the copyright headers of The Bitcoin Core developers which were
changed in a year more recent than is listed. For example:
// Copyright (c) <firstYear>-<lastYear> The Bitcoin Core developers
will be updated to:
// Copyright (c) <firstYear>-<lastModifiedYear> The Bitcoin Core developers
where <lastModifiedYear> is obtained from the git log history.
This subcommand also handles copyright headers that have only a single year. In those cases:
// Copyright (c) <year> The Bitcoin Core developers
will be updated to:
// Copyright (c) <year>-<lastModifiedYear> The Bitcoin Core developers
where the update is appropriate.
copyright_header.py insert <file>
Inserts a copyright header for The Bitcoin Core developers at the top of the
file in either Python or C++ style as determined by the file extension. If the
file is a Python file and it has #! starting the first line, the header is
inserted in the line below it.
The copyright dates will be set to be <year_introduced>-<current_year> where
<year_introduced> is according to the git log history. If
<year_introduced> is equal to <current_year>, it will be set as a single
year rather than two hyphenated years.
If the file already has a copyright for The Bitcoin Core developers, the
script will exit.
gen-manpages.py
A small script to automatically create manpages in ../../doc/man by running the release binaries with the -help option. This requires help2man which can be found at: https://www.gnu.org/software/help2man/
With in-tree builds this tool can be run from any directory within the
repository. To use this tool with out-of-tree builds set BUILDDIR. For
example:
BUILDDIR=$PWD/build contrib/devtools/gen-manpages.py
headerssync-params.py
A script to generate optimal parameters for the headerssync module (src/headerssync.cpp). It takes no command-line options, as all its configuration is set at the top of the file. It runs many times faster inside PyPy. Invocation:
pypy3 contrib/devtools/headerssync-params.py
gen-bitcoin-conf.sh
Generates a bitcoin.conf file in share/examples/ by parsing the output from bitcoind --help. This script is run during the
release process to include a bitcoin.conf with the release binaries and can also be run by users to generate a file locally.
When generating a file as part of the release process, make sure to commit the changes after running the script.
With in-tree builds this tool can be run from any directory within the
repository. To use this tool with out-of-tree builds set BUILDDIR. For
example:
BUILDDIR=$PWD/build contrib/devtools/gen-bitcoin-conf.sh
security-check.py and test-security-check.py
Perform basic security checks on a series of executables.
symbol-check.py
A script to check that release executables only contain certain symbols and are only linked against allowed libraries.
For Linux this means checking for allowed gcc, glibc and libstdc++ version symbols. This makes sure they are still compatible with the minimum supported distribution versions.
For macOS and Windows we check that the executables are only linked against libraries we allow.
Example usage:
find ../path/to/executables -type f -executable | xargs python3 contrib/devtools/symbol-check.py
If no errors occur the return value will be 0 and the output will be empty.
If there are any errors the return value will be 1 and output like this will be printed:
.../64/test_bitcoin: symbol memcpy from unsupported version GLIBC_2.14
.../64/test_bitcoin: symbol __fdelt_chk from unsupported version GLIBC_2.15
.../64/test_bitcoin: symbol std::out_of_range::~out_of_range() from unsupported version GLIBCXX_3.4.15
.../64/test_bitcoin: symbol _ZNSt8__detail15_List_nod from unsupported version GLIBCXX_3.4.15
circular-dependencies.py
Run this script from the root of the source tree (src/) to find circular dependencies in the source code.
This looks only at which files include other files, treating the .cpp and .h file as one unit.
Example usage:
cd .../src
../contrib/devtools/circular-dependencies.py {*,*/*,*/*/*}.{h,cpp}
Bitcoin Tidy
Example Usage:
cmake -S . -B build -DLLVM_DIR=$(llvm-config --cmakedir) -DCMAKE_BUILD_TYPE=Release
cmake --build build -j$(nproc)
cmake --build build --target bitcoin-tidy-tests -j$(nproc)
Bootstrappable Bitcoin Core Builds
This directory contains the files necessary to perform bootstrappable Bitcoin Core builds.
Bootstrappability furthers our binary security guarantees by allowing us to audit and reproduce our toolchain instead of blindly trusting binary downloads.
We achieve bootstrappability by using Guix as a functional package manager.
Requirements
Conservatively, you will need:
- 16GB of free disk space on the partition that /gnu/store will reside in
- 8GB of free disk space per platform triple you're planning on building
(see the
HOSTSenvironment variable description)
Installation and Setup
If you don't have Guix installed and set up, please follow the instructions in INSTALL.md
Usage
If you haven't considered your security model yet, please read the relevant section before proceeding to perform a build.
Making the Xcode SDK available for macOS cross-compilation
In order to perform a build for macOS (which is included in the default set of
platform triples to build), you'll need to extract the macOS SDK tarball using
tools found in the macdeploy directory.
You can then either point to the SDK using the SDK_PATH environment variable:
# Extract the SDK tarball to /path/to/parent/dir/of/extracted/SDK/Xcode-<foo>-<bar>-extracted-SDK-with-libcxx-headers
tar -C /path/to/parent/dir/of/extracted/SDK -xaf /path/to/Xcode-<foo>-<bar>-extracted-SDK-with-libcxx-headers.tar.gz
# Indicate where to locate the SDK tarball
export SDK_PATH=/path/to/parent/dir/of/extracted/SDK
or extract it into depends/SDKs:
mkdir -p depends/SDKs
tar -C depends/SDKs -xaf /path/to/SDK/tarball
Building
The author highly recommends at least reading over the common usage patterns and examples section below before starting a build. For a full list of customization options, see the recognized environment variables section.
To build Bitcoin Core reproducibly with all default options, invoke the following from the top of a clean repository:
./contrib/guix/guix-build
Codesigning build outputs
The guix-codesign command attaches codesignatures (produced by codesigners) to
existing non-codesigned outputs. Please see the release process
documentation for more context.
It respects many of the same environment variable flags as guix-build, with 2
crucial differences:
- Since only Windows and macOS build outputs require codesigning, the
HOSTSenvironment variable will have a sane default value ofx86_64-w64-mingw32 x86_64-apple-darwin arm64-apple-darwininstead of all the platforms. - The
guix-codesigncommand requires aDETACHED_SIGS_REPOflag.-
DETACHED_SIGS_REPO
Set the directory where detached codesignatures can be found for the current Bitcoin Core version being built.
REQUIRED environment variable
-
An invocation with all default options would look like:
env DETACHED_SIGS_REPO=<path/to/bitcoin-detached-sigs> ./contrib/guix/guix-codesign
Cleaning intermediate work directories
By default, guix-build leaves all intermediate files or "work directories"
(e.g. depends/work, guix-build-*/distsrc-*) intact at the end of a build so
that they are available to the user (to aid in debugging, etc.). However, these
directories usually take up a large amount of disk space. Therefore, a
guix-clean convenience script is provided which cleans the current git
worktree to save disk space:
./contrib/guix/guix-clean
Attesting to build outputs
Much like how Gitian build outputs are attested to in a gitian.sigs
repository, Guix build outputs are attested to in the guix.sigs
repository.
After you've cloned the guix.sigs repository, to attest to the current
worktree's commit/tag:
env GUIX_SIGS_REPO=<path/to/guix.sigs> SIGNER=<gpg-key-name> ./contrib/guix/guix-attest
See ./contrib/guix/guix-attest --help for more information on the various ways
guix-attest can be invoked.
Verifying build output attestations
After at least one other signer has uploaded their signatures to the guix.sigs
repository:
git -C <path/to/guix.sigs> pull
env GUIX_SIGS_REPO=<path/to/guix.sigs> ./contrib/guix/guix-verify
Common guix-build invocation patterns and examples
Keeping caches and SDKs outside of the worktree
If you perform a lot of builds and have a bunch of worktrees, you may find it
more efficient to keep the depends tree's download cache, build cache, and SDKs
outside of the worktrees to avoid duplicate downloads and unnecessary builds. To
help with this situation, the guix-build script honours the SOURCES_PATH,
BASE_CACHE, and SDK_PATH environment variables and will pass them on to the
depends tree so that you can do something like:
env SOURCES_PATH="$HOME/depends-SOURCES_PATH" BASE_CACHE="$HOME/depends-BASE_CACHE" SDK_PATH="$HOME/macOS-SDKs" ./contrib/guix/guix-build
Note that the paths that these environment variables point to must be directories, and NOT symlinks to directories.
See the recognized environment variables section for more details.
Building a subset of platform triples
Sometimes you only want to build a subset of the supported platform triples, in
which case you can override the default list by setting the space-separated
HOSTS environment variable:
env HOSTS='x86_64-w64-mingw32 x86_64-apple-darwin' ./contrib/guix/guix-build
See the recognized environment variables section for more details.
Controlling the number of threads used by guix build commands
Depending on your system's RAM capacity, you may want to decrease the number of threads used to decrease RAM usage or vice versa.
By default, the scripts under ./contrib/guix will invoke all guix build
commands with --cores="$JOBS". Note that $JOBS defaults to $(nproc) if not
specified. However, astute manual readers will also notice that guix build
commands also accept a --max-jobs= flag (which defaults to 1 if unspecified).
Here is the difference between --cores= and --max-jobs=:
Note: When I say "derivation," think "package"
--cores=
- controls the number of CPU cores to build each derivation. This is the value
passed to
make's--jobs=flag.
--max-jobs=
- controls how many derivations can be built in parallel
- defaults to 1
Therefore, the default is for guix build commands to build one derivation at a
time, utilizing $JOBS threads.
Specifying the $JOBS environment variable will only modify --cores=, but you
can also modify the value for --max-jobs= by specifying
$ADDITIONAL_GUIX_COMMON_FLAGS. For example, if you have a LOT of memory, you
may want to set:
export ADDITIONAL_GUIX_COMMON_FLAGS='--max-jobs=8'
Which allows for a maximum of 8 derivations to be built at the same time, each
utilizing $JOBS threads.
Or, if you'd like to avoid spurious build failures caused by issues with parallelism within a single package, but would still like to build multiple packages when the dependency graph allows for it, you may want to try:
export JOBS=1 ADDITIONAL_GUIX_COMMON_FLAGS='--max-jobs=8'
See the recognized environment variables section for more details.
Recognized environment variables
-
HOSTS
Override the space-separated list of platform triples for which to perform a bootstrappable build.
(defaults to "x86_64-linux-gnu arm-linux-gnueabihf aarch64-linux-gnu riscv64-linux-gnu powerpc64-linux-gnu powerpc64le-linux-gnu x86_64-w64-mingw32 x86_64-apple-darwin arm64-apple-darwin")
-
SOURCES_PATH
Set the depends tree download cache for sources. This is passed through to the depends tree. Setting this to the same directory across multiple builds of the depends tree can eliminate unnecessary redownloading of package sources.
The path that this environment variable points to must be a directory, and NOT a symlink to a directory.
-
BASE_CACHE
Set the depends tree cache for built packages. This is passed through to the depends tree. Setting this to the same directory across multiple builds of the depends tree can eliminate unnecessary building of packages.
The path that this environment variable points to must be a directory, and NOT a symlink to a directory.
-
SDK_PATH
Set the path where extracted SDKs can be found. This is passed through to the depends tree. Note that this is should be set to the parent directory of the actual SDK (e.g.
SDK_PATH=$HOME/Downloads/macOS-SDKsinstead of$HOME/Downloads/macOS-SDKs/Xcode-12.2-12B45b-extracted-SDK-with-libcxx-headers).The path that this environment variable points to must be a directory, and NOT a symlink to a directory.
-
JOBS
Override the number of jobs to run simultaneously, you might want to do so on a memory-limited machine. This may be passed to:
guixbuild commands as inguix shell --cores="$JOBS"makeas inmake --jobs="$JOBS"cmakeas incmake --build build -j "$JOBS"xargsas inxargs -P"$JOBS"
See here for more details.
(defaults to the value of
nprocoutside the container) -
SOURCE_DATE_EPOCH
Override the reference UNIX timestamp used for bit-for-bit reproducibility, the variable name conforms to standard.
(defaults to the output of
$(git log --format=%at -1)) -
V
If non-empty, will pass
V=1to allmakeinvocations, makingmakeoutput verbose.Note that any given value is ignored. The variable is only checked for emptiness. More concretely, this means that
V=(settingVto the empty string) is interpreted the same way as not settingVat all, and thatV=0has the same effect asV=1. -
SUBSTITUTE_URLS
A whitespace-delimited list of URLs from which to download pre-built packages. A URL is only used if its signing key is authorized (refer to the substitute servers section for more details).
-
ADDITIONAL_GUIX_COMMON_FLAGS
Additional flags to be passed to all
guixcommands. -
ADDITIONAL_GUIX_TIMEMACHINE_FLAGS
Additional flags to be passed to
guix time-machine. -
ADDITIONAL_GUIX_ENVIRONMENT_FLAGS
Additional flags to be passed to the invocation of
guix shellinsideguix time-machine.
Choosing your security model
No matter how you installed Guix, you need to decide on your security model for building packages with Guix.
Guix allows us to achieve better binary security by using our CPU time to build everything from scratch. However, it doesn't sacrifice user choice in pursuit of this: users can decide whether or not to use substitutes (pre-built packages).
Option 1: Building with substitutes
Step 1: Authorize the signing keys
Depending on the installation procedure you followed, you may have already authorized the Guix build farm key. In particular, the official shell installer script asks you if you want the key installed, and the debian distribution package authorized the key during installation.
You can check the current list of authorized keys at /etc/guix/acl.
At the time of writing, a /etc/guix/acl with just the Guix build farm key
authorized looks something like:
(acl
(entry
(public-key
(ecc
(curve Ed25519)
(q #8D156F295D24B0D9A86FA5741A840FF2D24F60F7B6C4134814AD55625971B394#)
)
)
(tag
(guix import)
)
)
)
If you've determined that the official Guix build farm key hasn't been authorized, and you would like to authorize it, run the following as root:
guix archive --authorize < /var/guix/profiles/per-user/root/current-guix/share/guix/ci.guix.gnu.org.pub
If
/var/guix/profiles/per-user/root/current-guix/share/guix/ci.guix.gnu.org.pub
doesn't exist, try:
guix archive --authorize < <PREFIX>/share/guix/ci.guix.gnu.org.pub
Where <PREFIX> is likely:
/usrif you installed from a distribution package/usr/localif you installed Guix from source and didn't supply any prefix-modifying flags to Guix's./configure
For dongcarl's substitute server at https://guix.carldong.io, run as root:
wget -qO- 'https://guix.carldong.io/signing-key.pub' | guix archive --authorize
Removing authorized keys
To remove previously authorized keys, simply edit /etc/guix/acl and remove the
(entry (public-key ...)) entry.
Step 2: Specify the substitute servers
Once its key is authorized, the official Guix build farm at
https://ci.guix.gnu.org is automatically used unless the --no-substitutes flag
is supplied. This default list of substitute servers is overridable both on a
guix-daemon level and when you invoke guix commands. See examples below for
the various ways of adding dongcarl's substitute server after having authorized
his signing key.
Change the default list of substitute servers by starting guix-daemon with
the --substitute-urls option (you will likely need to edit your init script):
guix-daemon <cmd> --substitute-urls='https://guix.carldong.io https://ci.guix.gnu.org'
Override the default list of substitute servers by passing the
--substitute-urls option for invocations of guix commands:
guix <cmd> --substitute-urls='https://guix.carldong.io https://ci.guix.gnu.org'
For scripts under ./contrib/guix, set the SUBSTITUTE_URLS environment
variable:
export SUBSTITUTE_URLS='https://guix.carldong.io https://ci.guix.gnu.org'
Option 2: Disabling substitutes on an ad-hoc basis
If you prefer not to use any substitutes, make sure to supply --no-substitutes
like in the following snippet. The first build will take a while, but the
resulting packages will be cached for future builds.
For direct invocations of guix:
guix <cmd> --no-substitutes
For the scripts under ./contrib/guix/:
export ADDITIONAL_GUIX_COMMON_FLAGS='--no-substitutes'
Option 3: Disabling substitutes by default
guix-daemon accepts a --no-substitutes flag, which will make sure that,
unless otherwise overridden by a command line invocation, no substitutes will be
used.
If you start guix-daemon using an init script, you can edit said script to
supply this flag.
Guix Installation and Setup
This only needs to be done once per machine. If you have already completed the installation and setup, please proceed to perform a build.
Otherwise, you may choose from one of the following options to install Guix:
- Using the official shell installer script ⤓ skip to section
- Maintained by Guix developers
- Easiest (automatically performs most setup)
- Works on nearly all Linux distributions
- Only installs latest release
- Binary installation only, requires high level of trust
- Note: The script needs to be run as root, so it should be inspected before it's run
- Using the official binary tarball ⤓ skip to section
- Maintained by Guix developers
- Normal difficulty (full manual setup required)
- Works on nearly all Linux distributions
- Installs any release
- Binary installation only, requires high level of trust
- Using fanquake's Docker image ↗︎ external instructions
- Maintained by fanquake
- Easy (automatically performs some setup)
- Works wherever Docker images work
- Installs any release
- Binary installation only, requires high level of trust
- Using a distribution-maintained package ⤓ skip to section
- Maintained by distribution's Guix package maintainer
- Normal difficulty (manual setup required)
- Works only on distributions with Guix packaged, see: https://repology.org/project/guix/versions
- Installs a release decided on by package maintainer
- Source or binary installation depending on the distribution
- Building from source ⤓ skip to section
- Maintained by you
- Hard, but rewarding
- Can be made to work on most Linux distributions
- Installs any commit (more granular)
- Source installation, requires lower level of trust
Options 1 and 2: Using the official shell installer script or binary tarball
The installation instructions for both the official shell installer script and the binary tarballs can be found in the GNU Guix Manual's Binary Installation section.
Note that running through the binary tarball installation steps is largely equivalent to manually performing what the shell installer script does.
Note that at the time of writing (July 5th, 2021), the shell installer script
automatically creates an /etc/profile.d entry which the binary tarball
installation instructions do not ask you to create. However, you will likely
need this entry for better desktop integration. Please see this
section for instructions on how to add a
/etc/profile.d/guix.sh entry.
Regardless of which installation option you chose, the changes to
/etc/profile.d will not take effect until the next shell or desktop session,
so you should log out and log back in.
Option 3: Using fanquake's Docker image
Please refer to fanquake's instructions here.
Option 4: Using a distribution-maintained package
Note that this section is based on the distro packaging situation at the time of writing (July 2021). Guix is expected to be more widely packaged over time. For an up-to-date view on Guix's package status/version across distros, please see: https://repology.org/project/guix/versions
Debian / Ubuntu
Guix is available as a distribution package in Debian and Ubuntu .
To install:
sudo apt install guix
Arch Linux
Guix is available in the AUR as
guix, please follow the
installation instructions in the Arch Linux Wiki (live
link,
2021/03/30
permalink)
to install Guix.
At the time of writing (2021/03/30), the check phase will fail if the path to
guix's build directory is longer than 36 characters due to an anachronistic
character limit on the shebang line. Since the check phase happens after the
build phase, which may take quite a long time, it is recommended that users
either:
- Skip the
checkphase- For
makepkg:makepkg --nocheck ... - For
yay:yay --mflags="--nocheck" ... - For
paru:paru --nocheck ...
- For
- Or, check their build directory's length beforehand
- For those building with
makepkg:pwd | wc -c
- For those building with
Option 5: Building from source
Building Guix from source is a rather involved process but a rewarding one for those looking to minimize trust and maximize customizability (e.g. building a particular commit of Guix). Previous experience with using autotools-style build systems to build packages from source will be helpful. hic sunt dracones.
I strongly urge you to at least skim through the entire section once before you start issuing commands, as it will save you a lot of unnecessary pain and anguish.
Installing common build tools
There are a few basic build tools that are required for most things we'll build, so let's install them now:
Text transformation/i18n:
autopoint(sometimes packaged ingettext)help2manpo4atexinfo
Build system tools:
g++w/ C++11 supportlibtoolautoconfautomakepkg-config(sometimes packaged aspkgconf)makecmake
Miscellaneous:
gitgnupgpython3
Building and Installing Guix's dependencies
In order to build Guix itself from source, we need to first make sure that the necessary dependencies are installed and discoverable. The most up-to-date list of Guix's dependencies is kept in the "Requirements" section of the Guix Reference Manual.
Depending on your distribution, most or all of these dependencies may already be packaged and installable without manually building and installing.
For reference, the graphic below outlines Guix v1.3.0's dependency graph:
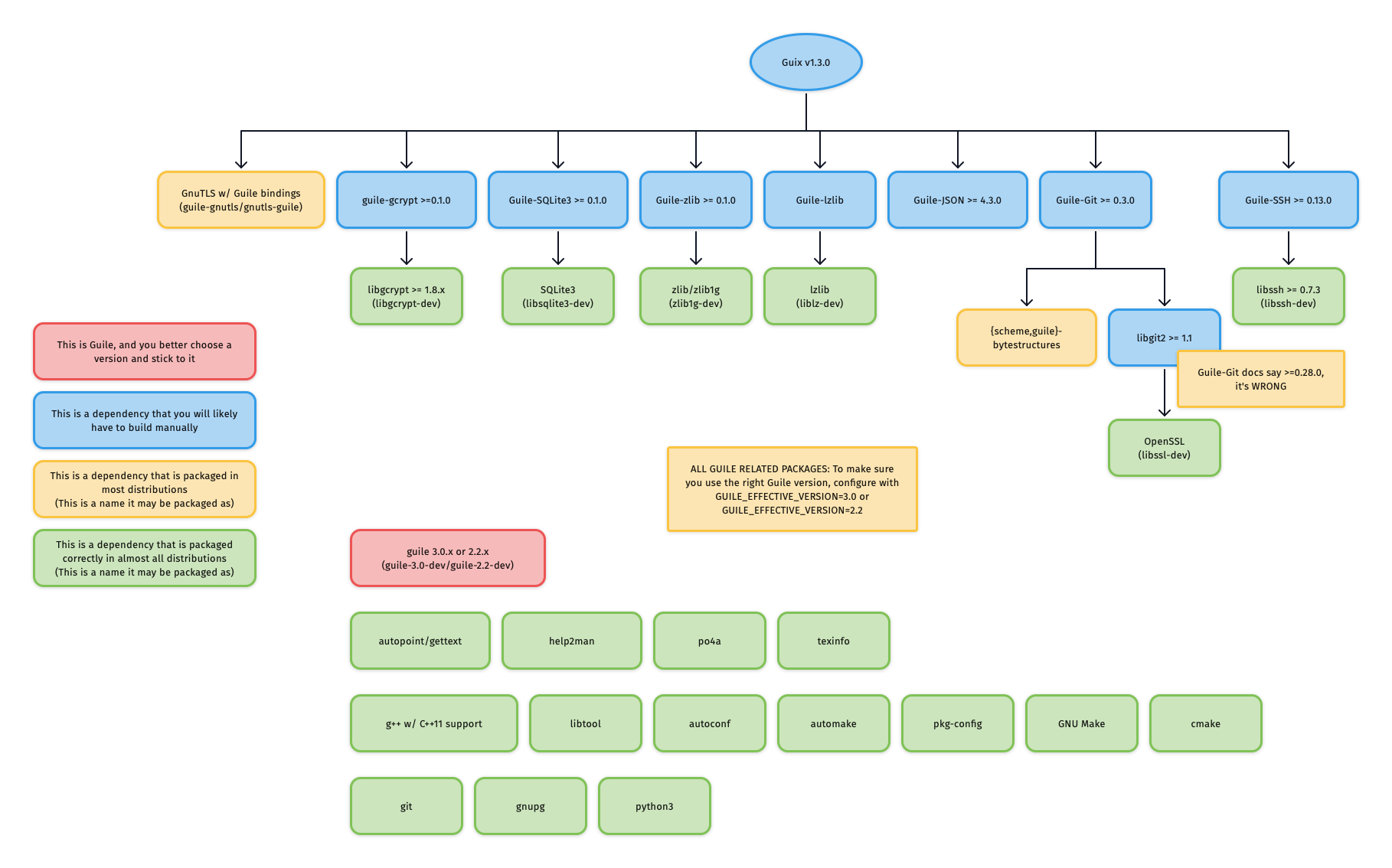
If you do not care about building each dependency from source, and Guix is already packaged for your distribution, you can easily install only the build dependencies of Guix. For example, to enable deb-src and install the Guix build dependencies on Ubuntu/Debian:
sed -i 's|# deb-src|deb-src|g' /etc/apt/sources.list
apt update
apt-get build-dep -y guix
If this succeeded, you can likely skip to section "Building and Installing Guix itself".
Guile
Corner case: Multiple versions of Guile on one system
It is recommended to only install the required version of Guile, so that build systems do not get confused about which Guile to use.
However, if you insist on having more versions of Guile installed on
your system, then you need to consistently specify
GUILE_EFFECTIVE_VERSION=3.0 to all
./configure invocations for Guix and its dependencies.
Installing Guile
If your distribution splits packages into -dev-suffixed and
non--dev-suffixed sub-packages (as is the case for Debian-derived
distributions), please make sure to install both. For example, to install Guile
v3.0 on Debian/Ubuntu:
apt install guile-3.0 guile-3.0-dev
Mixing distribution packages and source-built packages
At the time of writing, most distributions have some of Guix's dependencies packaged, but not all. This means that you may want to install the distribution package for some dependencies, and manually build-from-source for others.
Distribution packages usually install to /usr, which is different from the
default ./configure prefix of source-built packages: /usr/local.
This means that if you mix-and-match distribution packages and source-built
packages and do not specify exactly --prefix=/usr to ./configure for
source-built packages, you will need to augment the GUILE_LOAD_PATH and
GUILE_LOAD_COMPILED_PATH environment variables so that Guile will look
under the right prefix and find your source-built packages.
For example, if you are using Guile v3.0, and have Guile packages in the
/usr/local prefix, either add the following lines to your .profile or
.bash_profile so that the environment variable is properly set for all future
shell logins, or paste the lines into a POSIX-style shell to temporarily modify
the environment variables of your current shell session.
# Help Guile v3.0.x find packages in /usr/local
export GUILE_LOAD_PATH="/usr/local/share/guile/site/3.0${GUILE_LOAD_PATH:+:}$GUILE_LOAD_PATH"
export GUILE_LOAD_COMPILED_PATH="/usr/local/lib/guile/3.0/site-ccache${GUILE_LOAD_COMPILED_PATH:+:}$GUILE_COMPILED_LOAD_PATH"
Note that these environment variables are used to check for packages during
./configure, so they should be set as soon as possible should you want to use
a prefix other than /usr.
Building and installing source-built packages
IMPORTANT: A few dependencies have non-obvious quirks/errata which are documented in the sub-sections immediately below. Please read these sections before proceeding to build and install these packages.
Although you should always refer to the README or INSTALL files for the most
accurate information, most of these dependencies use autoconf-style build
systems (check if there's a configure.ac file), and will likely do the right
thing with the following:
Clone the repository and check out the latest release:
git clone <git-repo-of-dependency>/<dependency>.git
cd <dependency>
git tag -l # check for the latest release
git checkout <latest-release>
For autoconf-based build systems (if ./autogen.sh or configure.ac exists at
the root of the repository):
./autogen.sh || autoreconf -vfi
./configure --prefix=<prefix>
make
sudo make install
For CMake-based build systems (if CMakeLists.txt exists at the root of the
repository):
mkdir build && cd build
cmake .. -DCMAKE_INSTALL_PREFIX=<prefix>
sudo cmake --build . --target install
If you choose not to specify exactly --prefix=/usr to ./configure, please
make sure you've carefully read the [previous section] on mixing distribution
packages and source-built packages.
Binding packages require -dev-suffixed packages
Relevant for:
- Everyone
When building bindings, the -dev-suffixed version of the original package
needs to be installed. For example, building Guile-zlib on Debian-derived
distributions requires that zlib1g-dev is installed.
When using bindings, the -dev-suffixed version of the original package still
needs to be installed. This is particularly problematic when distribution
packages are mispackaged like guile-sqlite3 is in Ubuntu Focal such that
installing guile-sqlite3 does not automatically install libsqlite3-dev as a
dependency.
Below is a list of relevant Guile bindings and their corresponding -dev
packages in Debian at the time of writing.
| Guile binding package | -dev Debian package |
|---|---|
| guile-gcrypt | libgcrypt-dev |
| guile-git | libgit2-dev |
| guile-gnutls | (none) |
| guile-json | (none) |
| guile-lzlib | liblz-dev |
| guile-ssh | libssh-dev |
| guile-sqlite3 | libsqlite3-dev |
| guile-zlib | zlib1g-dev |
guile-git actually depends on libgit2 >= 1.1
Relevant for:
- Those building
guile-gitfrom source againstlibgit2 < 1.1 - Those installing
guile-gitfrom their distribution whereguile-gitis built againstlibgit2 < 1.1
As of v0.5.2, guile-git claims to only require libgit2 >= 0.28.0, however,
it actually requires libgit2 >= 1.1, otherwise, it will be confused by a
reference of origin/keyring: instead of interpreting the reference as "the
'keyring' branch of the 'origin' remote", the reference is interpreted as "the
branch literally named 'origin/keyring'"
This is especially notable because Ubuntu Focal packages libgit2 v0.28.4, and
guile-git is built against it.
Should you be in this situation, you need to build both libgit2 v1.1.x and
guile-git from source.
Source: https://logs.guix.gnu.org/guix/2020-11-12.log#232527
Building and Installing Guix itself
Start by cloning Guix:
git clone https://git.savannah.gnu.org/git/guix.git
cd guix
You will likely want to build the latest release.
At the time of writing (November 2023), the latest release was v1.4.0.
git branch -a -l 'origin/version-*' # check for the latest release
git checkout <latest-release>
Bootstrap the build system:
./bootstrap
Configure with the recommended --localstatedir flag:
./configure --localstatedir=/var
Note: If you intend to hack on Guix in the future, you will need to supply the
same --localstatedir= flag for all future Guix ./configure invocations. See
the last paragraph of this
section for more
details.
Build Guix (this will take a while):
make -j$(nproc)
Install Guix:
sudo make install
Post-"build from source" Setup
Creating and starting a guix-daemon-original service with a fixed argv[0]
At this point, guix will be installed to ${bindir}, which is likely
/usr/local/bin if you did not override directory variables at
./configure-time. More information on standard Automake directory variables
can be found
here.
However, the Guix init scripts and service configurations for Upstart, systemd,
SysV, and OpenRC are installed (in ${libdir}) to launch
${localstatedir}/guix/profiles/per-user/root/current-guix/bin/guix-daemon,
which does not yet exist, and will only exist after root performs their first
guix pull.
We need to create a -original version of these init scripts that's pointed to
the binaries we just built and make install'ed in ${bindir} (normally,
/usr/local/bin).
Example for systemd, run as root:
# Create guix-daemon-original.service by modifying guix-daemon.service
libdir=# set according to your PREFIX (default is /usr/local/lib)
bindir="$(dirname $(command -v guix-daemon))"
sed -E -e "s|/\S*/guix/profiles/per-user/root/current-guix/bin/guix-daemon|${bindir}/guix-daemon|" "${libdir}"/systemd/system/guix-daemon.service > /etc/systemd/system/guix-daemon-original.service
chmod 664 /etc/systemd/system/guix-daemon-original.service
# Make systemd recognize the new service
systemctl daemon-reload
# Make sure that the non-working guix-daemon.service is stopped and disabled
systemctl stop guix-daemon
systemctl disable guix-daemon
# Make sure that the working guix-daemon-original.service is started and enabled
systemctl enable guix-daemon-original
systemctl start guix-daemon-original
Creating guix-daemon users / groups
Please see the relevant section in the Guix Reference Manual for more details.
Optional setup
At this point, you are set up to use Guix to build Bitcoin Core. However, if you want to polish your setup a bit and make it "what Guix intended", then read the next few subsections.
Add an /etc/profile.d entry
This section definitely does not apply to you if you installed Guix using:
- The shell installer script
- fanquake's Docker image
- Debian's
guixpackage
Background
Although Guix knows how to update itself and its packages, it does so in a
non-invasive way (it does not modify /usr/local/bin/guix).
Instead, it does the following:
-
After a
guix pull, it updates/var/guix/profiles/per-user/$USER/current-guix, and creates a symlink targeting this directory at$HOME/.config/guix/current -
After a
guix install, it updates/var/guix/profiles/per-user/$USER/guix-profile, and creates a symlink targeting this directory at$HOME/.guix-profile
Therefore, in order for these operations to affect your shell/desktop sessions
(and for the principle of least astonishment to hold), their corresponding
directories have to be added to well-known environment variables like $PATH,
$INFOPATH, $XDG_DATA_DIRS, etc.
In other words, if $HOME/.config/guix/current/bin does not exist in your
$PATH, a guix pull will have no effect on what guix you are using. Same
goes for $HOME/.guix-profile/bin, guix install, and installed packages.
Helpfully, after a guix pull or guix install, a message will be printed like
so:
hint: Consider setting the necessary environment variables by running:
GUIX_PROFILE="$HOME/.guix-profile"
. "$GUIX_PROFILE/etc/profile"
Alternately, see `guix package --search-paths -p "$HOME/.guix-profile"'.
However, this is somewhat tedious to do for both guix pull and guix install
for each user on the system that wants to properly use guix. I recommend that
you instead add an entry to /etc/profile.d instead. This is done by default
when installing the Debian package later than 1.2.0-4 and when using the shell
script installer.
Instructions
Create /etc/profile.d/guix.sh with the following content:
# _GUIX_PROFILE: `guix pull` profile
_GUIX_PROFILE="$HOME/.config/guix/current"
if [ -L $_GUIX_PROFILE ]; then
export PATH="$_GUIX_PROFILE/bin${PATH:+:}$PATH"
# Export INFOPATH so that the updated info pages can be found
# and read by both /usr/bin/info and/or $GUIX_PROFILE/bin/info
# When INFOPATH is unset, add a trailing colon so that Emacs
# searches 'Info-default-directory-list'.
export INFOPATH="$_GUIX_PROFILE/share/info:$INFOPATH"
fi
# GUIX_PROFILE: User's default profile
GUIX_PROFILE="$HOME/.guix-profile"
[ -L $GUIX_PROFILE ] || return
GUIX_LOCPATH="$GUIX_PROFILE/lib/locale"
export GUIX_PROFILE GUIX_LOCPATH
[ -f "$GUIX_PROFILE/etc/profile" ] && . "$GUIX_PROFILE/etc/profile"
# set XDG_DATA_DIRS to include Guix installations
export XDG_DATA_DIRS="$GUIX_PROFILE/share:${XDG_DATA_DIRS:-/usr/local/share/:/usr/share/}"
Please note that this will not take effect until the next shell or desktop session (log out and log back in).
guix pull as root
Before you do this, you need to read the section on choosing your security
model and adjust guix and guix-daemon flags according to
your choice, as invoking guix pull may pull substitutes from substitute
servers (which you may not want).
As mentioned in a previous section, Guix expects
${localstatedir}/guix/profiles/per-user/root/current-guix to be populated with
root's Guix profile, guix pull-ed and built by some former version of Guix.
However, this is not the case when we build from source. Therefore, we need to
perform a guix pull as root:
sudo --login guix pull --branch=version-<latest-release-version>
# or
sudo --login guix pull --commit=<particular-commit>
guix pull is quite a long process (especially if you're using
--no-substitutes). If you encounter build problems, please refer to the
troubleshooting section.
Note that running a bare guix pull with no commit or branch specified will
pull the latest commit on Guix's master branch, which is likely fine, but not
recommended.
If you installed Guix from source, you may get an error like the following:
error: while creating symlink '/root/.config/guix/current' No such file or directory
To resolve this, simply:
sudo mkdir -p /root/.config/guix
Then try the guix pull command again.
After the guix pull finishes successfully,
${localstatedir}/guix/profiles/per-user/root/current-guix should be populated.
Using the newly-pulled guix by restarting the daemon
Depending on how you installed Guix, you should now make sure that your init
scripts and service configurations point to the newly-pulled guix-daemon.
If you built Guix from source
If you followed the instructions for fixing argv[0], you can now do the following:
systemctl stop guix-daemon-original
systemctl disable guix-daemon-original
systemctl enable guix-daemon
systemctl start guix-daemon
Remember to set --no-substitutes in $libdir/systemd/system/guix-daemon.service and other customizations if you used them for guix-daemon-original.service.
If you installed Guix via the Debian/Ubuntu distribution packages
You will need to create a guix-daemon-latest service which points to the new
guix rather than a pinned one.
# Create guix-daemon-latest.service by modifying guix-daemon.service
sed -E -e "s|/usr/bin/guix-daemon|/var/guix/profiles/per-user/root/current-guix/bin/guix-daemon|" /etc/systemd/system/guix-daemon.service > /lib/systemd/system/guix-daemon-latest.service
chmod 664 /lib/systemd/system/guix-daemon-latest.service
# Make systemd recognize the new service
systemctl daemon-reload
# Make sure that the old guix-daemon.service is stopped and disabled
systemctl stop guix-daemon
systemctl disable guix-daemon
# Make sure that the new guix-daemon-latest.service is started and enabled
systemctl enable guix-daemon-latest
systemctl start guix-daemon-latest
If you installed Guix via lantw44's Arch Linux AUR package
At the time of writing (July 5th, 2021) the systemd unit for "updated Guix" is
guix-daemon-latest.service, therefore, you should do the following:
systemctl stop guix-daemon
systemctl disable guix-daemon
systemctl enable guix-daemon-latest
systemctl start guix-daemon-latest
Otherwise...
Simply do:
systemctl restart guix-daemon
Checking everything
If you followed all the steps above to make your Guix setup "prim and proper," you can check that you did everything properly by running through this checklist.
-
/etc/profile.d/guix.shshould exist and be sourced at each shell login -
guix describeshould not printguix describe: error: failed to determine origin, but rather something like:Generation 38 Feb 22 2021 16:39:31 (current) guix f350df4 repository URL: https://git.savannah.gnu.org/git/guix.git branch: version-1.2.0 commit: f350df405fbcd5b9e27e6b6aa500da7f101f41e7 -
guix-daemonshould be running from${localstatedir}/guix/profiles/per-user/root/current-guix
Troubleshooting
Derivation failed to build
When you see a build failure like below:
building /gnu/store/...-foo-3.6.12.drv...
/ 'check' phasenote: keeping build directory `/tmp/guix-build-foo-3.6.12.drv-0'
builder for `/gnu/store/...-foo-3.6.12.drv' failed with exit code 1
build of /gnu/store/...-foo-3.6.12.drv failed
View build log at '/var/log/guix/drvs/../...-foo-3.6.12.drv.bz2'.
cannot build derivation `/gnu/store/...-qux-7.69.1.drv': 1 dependencies couldn't be built
cannot build derivation `/gnu/store/...-bar-3.16.5.drv': 1 dependencies couldn't be built
cannot build derivation `/gnu/store/...-baz-2.0.5.drv': 1 dependencies couldn't be built
guix time-machine: error: build of `/gnu/store/...-baz-2.0.5.drv' failed
It means that guix failed to build a package named foo, which was a
dependency of qux, bar, and baz. Importantly, note that the last "failed"
line is not necessarily the root cause, the first "failed" line is.
Most of the time, the build failure is due to a spurious test failure or the
package's build system/test suite breaking when running multi-threaded. To
rebuild just this derivation in a single-threaded fashion (please don't forget
to add other guix flags like --no-substitutes as appropriate):
$ guix build --cores=1 /gnu/store/...-foo-3.6.12.drv
If the single-threaded rebuild did not succeed, you may need to dig deeper.
You may view foo's build logs in less like so (please replace paths with the
path you see in the build failure output):
$ bzcat /var/log/guix/drvs/../...-foo-3.6.12.drv.bz2 | less
foo's build directory is also preserved and available at
/tmp/guix-build-foo-3.6.12.drv-0. However, if you fail to build foo multiple
times, it may be /tmp/...drv-1 or /tmp/...drv-2. Always consult the build
failure output for the most accurate, up-to-date information.
python(-minimal): [Errno 84] Invalid or incomplete multibyte or wide character
This error occurs when your $TMPDIR (default: /tmp) exists on a filesystem
which rejects characters not present in the UTF-8 character code set. An example
is ZFS with the utf8only=on option set.
More information: https://github.com/python/cpython/issues/81765
openssl-1.1.1l and openssl-1.1.1n
OpenSSL includes tests that will fail once some certificate has expired. The workarounds from the GnuTLS section immediately below can be used.
For openssl-1.1.1l use 2022-05-01 as the date.
GnuTLS: test-suite FAIL: status-request-revoked
The derivation is likely identified by: /gnu/store/vhphki5sg9xkdhh2pbc8gi6vhpfzryf0-gnutls-3.6.12.drv
This unfortunate error is most common for non-substitute builders who installed Guix v1.2.0. The problem stems from the fact that one of GnuTLS's tests uses a hardcoded certificate which expired on 2020-10-24.
What's more unfortunate is that this GnuTLS derivation is somewhat special in
Guix's dependency graph and is not affected by the package transformation flags
like --without-tests=.
The easiest solution for those encountering this problem is to install a newer version of Guix. However, there are ways to work around this issue:
Workaround 1: Using substitutes for this single derivation
If you've authorized the official Guix build farm's key (more info here), then you can use substitutes just for this single derivation by invoking the following:
guix build --substitute-urls="https://ci.guix.gnu.org" /gnu/store/vhphki5sg9xkdhh2pbc8gi6vhpfzryf0-gnutls-3.6.12.drv
See this section for instructions on how to remove authorized keys if you don't want to keep the build farm's key authorized.
Workaround 2: Temporarily setting the system clock back
This workaround was described here.
Basically:
- Turn off NTP
- Set system time to 2020-10-01
- guix build --no-substitutes /gnu/store/vhphki5sg9xkdhh2pbc8gi6vhpfzryf0-gnutls-3.6.12.drv
- Set system time back to accurate current time
- Turn NTP back on
For example,
sudo timedatectl set-ntp no
sudo date --set "01 oct 2020 15:00:00"
guix build /gnu/store/vhphki5sg9xkdhh2pbc8gi6vhpfzryf0-gnutls-3.6.12.drv
sudo timedatectl set-ntp yes
Workaround 3: Disable the tests in the Guix source code for this single derivation
If all of the above workarounds fail, you can also disable the tests phase of
the derivation via the arguments option, as described in the official
package
reference.
For example, to disable the openssl-1.1 check phase:
diff --git a/gnu/packages/tls.scm b/gnu/packages/tls.scm
index f1e844b..1077c4b 100644
--- a/gnu/packages/tls.scm
+++ b/gnu/packages/tls.scm
@@ -494,4 +494,5 @@ (define-public openssl-1.1
(arguments
`(#:parallel-tests? #f
+ #:tests? #f
#:test-target "test"
coreutils: FAIL: tests/tail-2/inotify-dir-recreate
The inotify-dir-create test fails on "remote" filesystems such as overlayfs (Docker's default filesystem) due to the filesystem being mistakenly recognized as non-remote.
A relatively easy workaround to this is to make sure that a somewhat traditional
filesystem is mounted at /tmp (where guix-daemon performs its builds). For
Docker users, this might mean using a volume, binding
mounting from host, or (for those with enough RAM and swap)
mounting a tmpfs using the --tmpfs flag.
Please see the following links for more details:
- An upstream coreutils bug has been filed: debbugs#47940
- A Guix bug detailing the underlying problem has been filed: guix-issues#47935, guix-issues#49985
- A commit to skip this test in Guix has been merged into the core-updates branch: savannah/guix@6ba1058
Purging/Uninstalling Guix
In the extraordinarily rare case where you messed up your Guix installation in an irreversible way, you may want to completely purge Guix from your system and start over.
-
Uninstall Guix itself according to the way you installed it (e.g.
sudo apt purge guixfor Ubuntu packaging,sudo make uninstallfor a build from source). -
Remove all build users and groups
You may check for relevant users and groups using:
getent passwd | grep guix getent group | grep guixThen, you may remove users and groups using:
sudo userdel <user> sudo groupdel <group> -
Remove all possible Guix-related directories
/var/guix//var/log/guix//gnu//etc/guix//home/*/.config/guix//home/*/.cache/guix//home/*/.guix-profile//root/.config/guix//root/.cache/guix//root/.guix-profile/
Sample configuration files for:
systemd: bitcoind.service
Upstart: bitcoind.conf
OpenRC: bitcoind.openrc
bitcoind.openrcconf
CentOS: bitcoind.init
macOS: org.bitcoin.bitcoind.plist
have been made available to assist packagers in creating node packages here.
See doc/init.md for more information.
Linearize
Construct a linear, no-fork, best version of the Bitcoin blockchain.
Step 1: Download hash list
$ ./linearize-hashes.py linearize.cfg > hashlist.txt
Required configuration file settings for linearize-hashes:
- RPC:
datadir(Required ifrpcuserandrpcpasswordare not specified) - RPC:
rpcuser,rpcpassword(Required ifdatadiris not specified)
Optional config file setting for linearize-hashes:
- RPC:
host(Default:127.0.0.1) - RPC:
port(Default:8332) - Blockchain:
min_height,max_height rev_hash_bytes: If true, the written block hash list will be byte-reversed. (In other words, the hash returned by getblockhash will have its bytes reversed.) False by default. Intended for generation of standalone hash lists but safe to use with linearize-data.py, which will output the same data no matter which byte format is chosen.
The linearize-hashes script requires a connection, local or remote, to a
JSON-RPC server. Running bitcoind or bitcoin-qt -server will be sufficient.
Step 2: Copy local block data
$ ./linearize-data.py linearize.cfg
Required configuration file settings:
output_file: The file that will contain the final blockchain. oroutput: Output directory for linearizedblocks/blkNNNNN.datoutput.
Optional config file setting for linearize-data:
debug_output: Some printouts may not always be desired. If true, such output will be printed.file_timestamp: Set each file's last-accessed and last-modified times, respectively, to the current time and to the timestamp of the most recent block written to the script's blockchain.genesis: The hash of the genesis block in the blockchain.input: bitcoind blocks/ directory containing blkNNNNN.dathashlist: text file containing list of block hashes created by linearize-hashes.py.max_out_sz: Maximum size for files created by theoutput_fileoption. (Default:1000*1000*1000 bytes)netmagic: Network magic number.out_of_order_cache_sz: If out-of-order blocks are being read, the block can be written to a cache so that the blockchain doesn't have to be sought again. This option specifies the cache size. (Default:100*1000*1000 bytes)rev_hash_bytes: If true, the block hash list written by linearize-hashes.py will be byte-reversed when read by linearize-data.py. See the linearize-hashes entry for more information.split_timestamp: Split blockchain files when a new month is first seen, in addition to reaching a maximum file size (max_out_sz).
MacOS Deployment
The macdeployqtplus script should not be run manually. Instead, after building as usual:
make deploy
When complete, it will have produced Bitcoin-Core.zip.
SDK Extraction
Step 1: Obtaining Xcode.app
A free Apple Developer Account is required to proceed.
Our macOS SDK can be extracted from Xcode_15.xip.
Alternatively, after logging in to your account go to 'Downloads', then 'More'
and search for Xcode 15.
An Apple ID and cookies enabled for the hostname are needed to download this.
The sha256sum of the downloaded XIP archive should be 4daaed2ef2253c9661779fa40bfff50655dc7ec45801aba5a39653e7bcdde48e.
To extract the .xip on Linux:
# Install/clone tools needed for extracting Xcode.app
apt install cpio
git clone https://github.com/bitcoin-core/apple-sdk-tools.git
# Unpack the .xip and place the resulting Xcode.app in your current
# working directory
python3 apple-sdk-tools/extract_xcode.py -f Xcode_15.xip | cpio -d -i
On macOS:
xip -x Xcode_15.xip
Step 2: Generating the SDK tarball from Xcode.app
To generate the SDK, run the script gen-sdk with the
path to Xcode.app (extracted in the previous stage) as the first argument.
./contrib/macdeploy/gen-sdk '/path/to/Xcode.app'
The generated archive should be: Xcode-15.0-15A240d-extracted-SDK-with-libcxx-headers.tar.gz.
The sha256sum should be c0c2e7bb92c1fee0c4e9f3a485e4530786732d6c6dd9e9f418c282aa6892f55d.
Deterministic macOS App Notes
macOS Applications are created on Linux using a recent LLVM.
All builds must target an Apple SDK. These SDKs are free to download, but not redistributable. See the SDK Extraction notes above for how to obtain it.
The Guix build process has been designed to avoid including the SDK's files in Guix's outputs. All interim tarballs are fully deterministic and may be freely redistributed.
Using an Apple-blessed key to sign binaries is a requirement to produce (distributable) macOS binaries. Because this private key cannot be shared, we'll have to be a bit creative in order for the build process to remain somewhat deterministic. Here's how it works:
- Builders use Guix to create an unsigned release. This outputs an unsigned ZIP which users may choose to bless, self-codesign, and run. It also outputs an unsigned app structure in the form of a tarball.
- The Apple keyholder uses this unsigned app to create a detached signature, using the included script. Detached signatures are available from this repository.
- Builders feed the unsigned app + detached signature back into Guix, which combines the pieces into a deterministic ZIP.
This Page Intentionally Left Blank
Per-Peer Message Capture
Purpose
This feature allows for message capture on a per-peer basis. It answers the simple question: "Can I see what messages my node is sending and receiving?"
Usage and Functionality
- Run
bitcoindwith the-capturemessagesoption. - Look in the
message_capturefolder in your datadir.- Typically this will be
~/.bitcoin/message_capture. - See that there are many folders inside, one for each peer names with its IP address and port.
- Inside each peer's folder there are two
.datfiles: one is for received messages (msgs_recv.dat) and the other is for sent messages (msgs_sent.dat).
- Typically this will be
- Run
contrib/message-capture/message-capture-parser.pywith the proper arguments.- See the
-hoption for help. - To see all messages, both sent and received, for all peers use:
./contrib/message-capture/message-capture-parser.py -o out.json \ ~/.bitcoin/message_capture/**/*.dat - Note: The messages in the given
.datfiles will be interleaved in chronological order. So, giving both received and sent.datfiles (as above with*.dat) will result in all messages being interleaved in chronological order. - If an output file is not provided (i.e. the
-ooption is not used), then the output prints tostdout.
- See the
- View the resulting output.
- The output file is
JSONformatted. - Suggestion: use
jqto view the output, withjq . out.json
- The output file is
QoS (Quality of service)
This is a Linux bash script that will set up tc to limit the outgoing bandwidth for connections to the Bitcoin network. It limits outbound TCP traffic with a source or destination port of 8333, but not if the destination IP is within a LAN.
This means one can have an always-on bitcoind instance running, and another local bitcoind/bitcoin-qt instance which connects to this node and receives blocks from it.
Seeds
Utility to generate the seeds.txt list that is compiled into the client (see src/chainparamsseeds.h and other utilities in contrib/seeds).
Be sure to update PATTERN_AGENT in makeseeds.py to include the current version,
and remove old versions as necessary (at a minimum when SeedsServiceFlags()
changes its default return value, as those are the services which seeds are added
to addrman with).
The seeds compiled into the release are created from sipa's, achow101's and luke-jr's
DNS seed, virtu's crawler, and asmap community AS map data. Run the following commands
from the /contrib/seeds directory:
curl https://bitcoin.sipa.be/seeds.txt.gz | gzip -dc > seeds_main.txt
curl https://mainnet.achownodes.xyz/seeds.txt.gz | gzip -dc >> seeds_main.txt
curl https://21.ninja/seeds.txt.gz | gzip -dc >> seeds_main.txt
curl https://luke.dashjr.org/programs/bitcoin/files/charts/seeds.txt >> seeds_main.txt
curl https://testnet.achownodes.xyz/seeds.txt.gz | gzip -dc > seeds_test.txt
curl https://raw.githubusercontent.com/asmap/asmap-data/main/latest_asmap.dat > asmap-filled.dat
python3 makeseeds.py -a asmap-filled.dat -s seeds_main.txt > nodes_main.txt
python3 makeseeds.py -a asmap-filled.dat -s seeds_test.txt > nodes_test.txt
# TODO: Uncomment when a seeder publishes seeds.txt.gz for testnet4
# python3 makeseeds.py -a asmap-filled.dat -s seeds_testnet4.txt -m 30000 > nodes_testnet4.txt
python3 generate-seeds.py . > ../../src/chainparamsseeds.h
Contents
This directory contains tools related to Signet, both for running a Signet yourself and for using one.
getcoins.py
A script to call a faucet to get Signet coins.
Syntax: getcoins.py [-h|--help] [-c|--cmd=<bitcoin-cli path>] [-f|--faucet=<faucet URL>] [-a|--addr=<signet bech32 address>] [-p|--password=<faucet password>] [--] [<bitcoin-cli args>]
--cmdlets you customize the bitcoin-cli path. By default it will look for it in the PATH--faucetlets you specify which faucet to use; the faucet is assumed to be compatible with https://github.com/kallewoof/bitcoin-faucet--addrlets you specify a Signet address; by default, the address must be a bech32 address. This and--cmdabove complement each other (i.e. you do not needbitcoin-cliif you use--addr)--passwordlets you specify a faucet password; this is handy if you are in a classroom and set up your own faucet for your students; (above faucet does not limit by IP when password is enabled)
If using the default network, invoking the script with no arguments should be sufficient under normal
circumstances, but if multiple people are behind the same IP address, the faucet will by default only
accept one claim per day. See --password above.
miner
You will first need to pick a difficulty target. Since signet chains are primarily protected by a signature rather than proof of work, there is no need to spend as much energy as possible mining, however you may wish to choose to spend more time than the absolute minimum. The calibrate subcommand can be used to pick a target appropriate for your hardware, eg:
MINER="./contrib/signet/miner"
GRIND="./build/src/bitcoin-util grind"
$MINER calibrate --grind-cmd="$GRIND"
nbits=1e00f403 for 25s average mining time
It defaults to estimating an nbits value resulting in 25s average time to find a block, but the --seconds parameter can be used to pick a different target, or the --nbits parameter can be used to estimate how long it will take for a given difficulty.
To mine the first block in your custom chain, you can run:
CLI="./build/src/bitcoin-cli -conf=mysignet.conf"
ADDR=$($CLI -signet getnewaddress)
NBITS=1e00f403
$MINER --cli="$CLI" generate --grind-cmd="$GRIND" --address="$ADDR" --nbits=$NBITS
This will mine a single block with a backdated timestamp designed to allow 100 blocks to be mined as quickly as possible, so that it is possible to do transactions.
Adding the --ongoing parameter will then cause the signet miner to create blocks indefinitely. It will pick the time between blocks so that difficulty is adjusted to match the provided --nbits value.
$MINER --cli="$CLI" generate --grind-cmd="$GRIND" --address="$ADDR" --nbits=$NBITS --ongoing
Other options
The --debug and --quiet options are available to control how noisy the signet miner's output is. Note that the --debug, --quiet and --cli parameters must all appear before the subcommand (generate, calibrate, etc) if used.
Instead of specifying --ongoing, you can specify --max-blocks=N to mine N blocks and stop.
The --set-block-time option is available to manually move timestamps forward or backward (subject to the rules that blocktime must be greater than mediantime, and dates can't be more than two hours in the future). It can only be used when mining a single block (ie, not when using --ongoing or --max-blocks greater than 1).
Instead of using a single address, a ranged descriptor may be provided via the --descriptor parameter, with the reward for the block at height H being sent to the H'th address generated from the descriptor.
Instead of calculating a specific nbits value, --min-nbits can be specified instead, in which case the minimum signet difficulty will be targeted. Signet's minimum difficulty corresponds to --nbits=1e0377ae.
By default, the signet miner mines blocks at fixed intervals with minimal variation. If you want blocks to appear more randomly, as they do in mainnet, specify the --poisson option.
Using the --multiminer parameter allows mining to be distributed amongst multiple miners. For example, if you have 3 miners and want to share blocks between them, specify --multiminer=1/3 on one, --multiminer=2/3 on another, and --multiminer=3/3 on the last one. If you want one to do 10% of blocks and two others to do 45% each, --multiminer=1-10/100 on the first, and --multiminer=11-55 and --multiminer=56-100 on the others. Note that which miner mines which block is determined by the previous block hash, so occasional runs of one miner doing many blocks in a row is to be expected.
When --multiminer is used, if a miner is down and does not mine a block within five minutes of when it is due, the other miners will automatically act as redundant backups ensuring the chain does not halt. The --backup-delay parameter can be used to change how long a given miner waits, allowing one to be the primary backup (after five minutes) and another to be the secondary backup (after six minutes, eg).
The --standby-delay parameter can be used to make a backup miner that only mines if a block doesn't arrive on time. This can be combined with --multiminer if desired. Setting --standby-delay also prevents the first block from being mined immediately.
Advanced usage
The process generate follows internally is to get a block template, convert that into a PSBT, sign the PSBT, move the signature from the signed PSBT into the block template's coinbase, grind proof of work for the block, and then submit the block to the network.
These steps can instead be done explicitly:
$CLI -signet getblocktemplate '{"rules": ["signet","segwit"]}' |
$MINER --cli="$CLI" genpsbt --address="$ADDR" |
$CLI -signet -stdin walletprocesspsbt |
jq -r .psbt |
$MINER --cli="$CLI" solvepsbt --grind-cmd="$GRIND" |
$CLI -signet -stdin submitblock
This is intended to allow you to replace part of the pipeline for further experimentation (eg, to sign the block with a hardware wallet).
TestGen
Utilities to generate test vectors for the data-driven Bitcoin tests.
To use inside a scripted-diff (or just execute directly):
./gen_key_io_test_vectors.py valid 70 > ../../src/test/data/key_io_valid.json
./gen_key_io_test_vectors.py invalid 70 > ../../src/test/data/key_io_invalid.json
Example scripts for User-space, Statically Defined Tracing (USDT)
This directory contains scripts showcasing User-space, Statically Defined Tracing (USDT) support for Bitcoin Core on Linux using. For more information on USDT support in Bitcoin Core see the USDT documentation.
Examples for the two main eBPF front-ends, bpftrace and
BPF Compiler Collection (BCC), with support for USDT, are listed. BCC is used
for complex tools and daemons and bpftrace is preferred for one-liners and
shorter scripts.
To develop and run bpftrace and BCC scripts you need to install the corresponding packages. See installing bpftrace and installing BCC for more information. For development there exist a bpftrace Reference Guide, a BCC Reference Guide, and a bcc Python Developer Tutorial.
Examples
The bpftrace examples contain a relative path to the bitcoind binary. By
default, the scripts should be run from the repository-root and assume a
self-compiled bitcoind binary. The paths in the examples can be changed, for
example, to point to release builds if needed. See the
Bitcoin Core USDT documentation on how to list available tracepoints in your
bitcoind binary.
WARNING: eBPF programs require root privileges to be loaded into a Linux kernel VM. This means the bpftrace and BCC examples must be executed with root privileges. Make sure to carefully review any scripts that you run with root privileges first!
log_p2p_traffic.bt
A bpftrace script logging information about inbound and outbound P2P network
messages. Based on the net:inbound_message and net:outbound_message
tracepoints.
By default, bpftrace limits strings to 64 bytes due to the limited stack size
in the eBPF VM. For example, Tor v3 addresses exceed the string size limit which
results in the port being cut off during logging. The string size limit can be
increased with the BPFTRACE_STRLEN environment variable (BPFTRACE_STRLEN=70
works fine).
$ bpftrace contrib/tracing/log_p2p_traffic.bt
Output
outbound 'ping' msg to peer 11 (outbound-full-relay, [2a02:b10c:f747:1:ef:fake:ipv6:addr]:8333) with 8 bytes
inbound 'pong' msg from peer 11 (outbound-full-relay, [2a02:b10c:f747:1:ef:fake:ipv6:addr]:8333) with 8 bytes
inbound 'inv' msg from peer 16 (outbound-full-relay, XX.XX.XXX.121:8333) with 37 bytes
outbound 'getdata' msg to peer 16 (outbound-full-relay, XX.XX.XXX.121:8333) with 37 bytes
inbound 'tx' msg from peer 16 (outbound-full-relay, XX.XX.XXX.121:8333) with 222 bytes
outbound 'inv' msg to peer 9 (outbound-full-relay, faketorv3addressa2ufa6odvoi3s77j4uegey0xb10csyfyve2t33curbyd.onion:8333) with 37 bytes
outbound 'inv' msg to peer 7 (outbound-full-relay, XX.XX.XXX.242:8333) with 37 bytes
…
p2p_monitor.py
A BCC Python script using curses for an interactive P2P message monitor. Based
on the net:inbound_message and net:outbound_message tracepoints.
Inbound and outbound traffic is listed for each peer together with information about the connection. Peers can be selected individually to view recent P2P messages.
$ python3 contrib/tracing/p2p_monitor.py $(pidof bitcoind)
Lists selectable peers and traffic and connection information.
P2P Message Monitor
Navigate with UP/DOWN or J/K and select a peer with ENTER or SPACE to see individual P2P messages
PEER OUTBOUND INBOUND TYPE ADDR
0 46 398 byte 61 1407590 byte block-relay-only XX.XX.XXX.196:8333
11 1156 253570 byte 3431 2394924 byte outbound-full-relay XXX.X.XX.179:8333
13 3425 1809620 byte 1236 305458 byte inbound XXX.X.X.X:60380
16 1046 241633 byte 1589 1199220 byte outbound-full-relay 4faketorv2pbfu7x.onion:8333
19 577 181679 byte 390 148951 byte outbound-full-relay kfake4vctorjv2o2.onion:8333
20 11 1248 byte 13 1283 byte block-relay-only [2600:fake:64d9:b10c:4436:aaaa:fe:bb]:8333
21 11 1248 byte 13 1299 byte block-relay-only XX.XXX.X.155:8333
22 5 103 byte 1 102 byte feeler XX.XX.XXX.173:8333
23 11 1248 byte 12 1255 byte block-relay-only XX.XXX.XXX.220:8333
24 3 103 byte 1 102 byte feeler XXX.XXX.XXX.64:8333
…
Showing recent P2P messages between our node and a selected peer.
----------------------------------------------------------------------
| PEER 16 (4faketorv2pbfu7x.onion:8333) |
| OUR NODE outbound-full-relay PEER |
| <--- sendcmpct (9 bytes) |
| inv (37 byte) ---> |
| <--- ping (8 bytes) |
| pong (8 byte) ---> |
| inv (37 byte) ---> |
| <--- addr (31 bytes) |
| inv (37 byte) ---> |
| <--- getheaders (1029 bytes) |
| headers (1 byte) ---> |
| <--- feefilter (8 bytes) |
| <--- pong (8 bytes) |
| <--- headers (82 bytes) |
| <--- addr (30003 bytes) |
| inv (1261 byte) ---> |
| … |
log_raw_p2p_msgs.py
A BCC Python script showcasing eBPF and USDT limitations when passing data
larger than about 32kb. Based on the net:inbound_message and
net:outbound_message tracepoints.
Bitcoin P2P messages can be larger than 32kb (e.g. tx, block, ...). The
eBPF VM's stack is limited to 512 bytes, and we can't allocate more than about
32kb for a P2P message in the eBPF VM. The message data is cut off when the
message is larger than MAX_MSG_DATA_LENGTH (see script). This can be detected
in user-space by comparing the data length to the message length variable. The
message is cut off when the data length is smaller than the message length.
A warning is included with the printed message data.
Data is submitted to user-space (i.e. to this script) via a ring buffer. The
throughput of the ring buffer is limited. Each p2p_message is about 32kb in
size. In- or outbound messages submitted to the ring buffer in rapid
succession fill the ring buffer faster than it can be read. Some messages are
lost. BCC prints: Possibly lost 2 samples on lost messages.
$ python3 contrib/tracing/log_raw_p2p_msgs.py $(pidof bitcoind)
Logging raw P2P messages.
Messages larger that about 32kb will be cut off!
Some messages might be lost!
outbound msg 'inv' from peer 4 (outbound-full-relay, XX.XXX.XX.4:8333) with 253 bytes: 0705000000be2245c8f844c9f763748e1a7…
…
Warning: incomplete message (only 32568 out of 53552 bytes)! inbound msg 'tx' from peer 32 (outbound-full-relay, XX.XXX.XXX.43:8333) with 53552 bytes: 020000000001fd3c01939c85ad6756ed9fc…
…
Possibly lost 2 samples
connectblock_benchmark.bt
A bpftrace script to benchmark the ConnectBlock() function during, for
example, a blockchain re-index. Based on the validation:block_connected USDT
tracepoint.
The script takes three positional arguments. The first two arguments, the start,
and end height indicate between which blocks the benchmark should be run. The
third acts as a duration threshold in milliseconds. When the ConnectBlock()
function takes longer than the threshold, information about the block, is
printed. For more details, see the header comment in the script.
The following command can be used to benchmark, for example, ConnectBlock()
between height 20000 and 38000 on SigNet while logging all blocks that take
longer than 25ms to connect.
$ bpftrace contrib/tracing/connectblock_benchmark.bt 20000 38000 25
In a different terminal, starting Bitcoin Core in SigNet mode and with re-indexing enabled.
$ ./build/src/bitcoind -signet -reindex
This produces the following output.
Attaching 5 probes...
ConnectBlock Benchmark between height 20000 and 38000 inclusive
Logging blocks taking longer than 25 ms to connect.
Starting Connect Block Benchmark between height 20000 and 38000.
BENCH 39 blk/s 59 tx/s 59 inputs/s 20 sigops/s (height 20038)
Block 20492 (000000f555653bb05e2f3c6e79925e01a20dd57033f4dc7c354b46e34735d32b) 20 tx 2319 ins 2318 sigops took 38 ms
BENCH 1840 blk/s 2117 tx/s 4478 inputs/s 2471 sigops/s (height 21879)
BENCH 1816 blk/s 4972 tx/s 4982 inputs/s 125 sigops/s (height 23695)
BENCH 2095 blk/s 2890 tx/s 2910 inputs/s 152 sigops/s (height 25790)
BENCH 1684 blk/s 3979 tx/s 4053 inputs/s 288 sigops/s (height 27474)
BENCH 1155 blk/s 3216 tx/s 3252 inputs/s 115 sigops/s (height 28629)
BENCH 1797 blk/s 2488 tx/s 2503 inputs/s 111 sigops/s (height 30426)
BENCH 1849 blk/s 6318 tx/s 6569 inputs/s 12189 sigops/s (height 32275)
BENCH 946 blk/s 20209 tx/s 20775 inputs/s 83809 sigops/s (height 33221)
Block 33406 (0000002adfe4a15cfcd53bd890a89bbae836e5bb7f38bac566f61ad4548c87f6) 25 tx 2045 ins 2090 sigops took 29 ms
Block 33687 (00000073231307a9828e5607ceb8156b402efe56747271a4442e75eb5b77cd36) 52 tx 1797 ins 1826 sigops took 26 ms
BENCH 582 blk/s 21581 tx/s 27673 inputs/s 60345 sigops/s (height 33803)
BENCH 1035 blk/s 19735 tx/s 19776 inputs/s 51355 sigops/s (height 34838)
Block 35625 (0000006b00b347390c4768ea9df2655e9ff4b120f29d78594a2a702f8a02c997) 20 tx 3374 ins 3371 sigops took 49 ms
BENCH 887 blk/s 17857 tx/s 22191 inputs/s 24404 sigops/s (height 35725)
Block 35937 (000000d816d13d6e39b471cd4368db60463a764ba1f29168606b04a22b81ea57) 75 tx 3943 ins 3940 sigops took 61 ms
BENCH 823 blk/s 16298 tx/s 21031 inputs/s 18440 sigops/s (height 36548)
Block 36583 (000000c3e260556dbf42968aae3f904dba8b8c1ff96a6f6e3aa5365d2e3ad317) 24 tx 2198 ins 2194 sigops took 34 ms
Block 36700 (000000b3b173de9e65a3cfa738d976af6347aaf83fa17ab3f2a4d2ede3ddfac4) 73 tx 1615 ins 1611 sigops took 31 ms
Block 36832 (0000007859578c02c1ac37dabd1b9ec19b98f350b56935f5dd3a41e9f79f836e) 34 tx 1440 ins 1436 sigops took 26 ms
BENCH 613 blk/s 16718 tx/s 25074 inputs/s 23022 sigops/s (height 37161)
Block 37870 (000000f5c1086291ba2d943fb0c3bc82e71c5ee341ee117681d1456fbf6c6c38) 25 tx 1517 ins 1514 sigops took 29 ms
BENCH 811 blk/s 16031 tx/s 20921 inputs/s 18696 sigops/s (height 37972)
Took 14055 ms to connect the blocks between height 20000 and 38000.
Histogram of block connection times in milliseconds (ms).
@durations:
[0] 16838 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[1] 882 |@@ |
[2, 4) 236 | |
[4, 8) 23 | |
[8, 16) 9 | |
[16, 32) 9 | |
[32, 64) 4 | |
log_utxocache_flush.py
A BCC Python script to log the UTXO cache flushes. Based on the
utxocache:flush tracepoint.
$ python3 contrib/tracing/log_utxocache_flush.py $(pidof bitcoind)
Logging utxocache flushes. Ctrl-C to end...
Duration (µs) Mode Coins Count Memory Usage Prune
730451 IF_NEEDED 22990 3323.54 kB True
637657 ALWAYS 122320 17124.80 kB False
81349 ALWAYS 0 1383.49 kB False
log_utxos.bt
A bpftrace script to log information about the coins that are added, spent, or
uncached from the UTXO set. Based on the utxocache:add, utxocache:spend and
utxocache:uncache tracepoints.
$ bpftrace contrib/tracing/log_utxos.bt
This should produce an output similar to the following. If you see bpftrace
warnings like Lost 24 events, the eBPF perf ring-buffer is filled faster
than it is being read. You can increase the ring-buffer size by setting the
ENV variable BPFTRACE_PERF_RB_PAGES (default 64) at a cost of higher
memory usage. See the bpftrace reference guide for more information.
Attaching 4 probes...
OP Outpoint Value Height Coinbase
Added 6ba9ad857e1ef2eb2a2c94f06813c414c7ab273e3d6bd7ad64e000315a887e7c:1 10000 2094512 No
Spent fa7dc4db56637a151f6649d8f26732956d1c5424c82aae400a83d02b2cc2c87b:0 182264897 2094512 No
Added eeb2f099b1af6a2a12e6ddd2eeb16fc5968582241d7f08ba202d28b60ac264c7:0 10000 2094512 No
Added eeb2f099b1af6a2a12e6ddd2eeb16fc5968582241d7f08ba202d28b60ac264c7:1 182254756 2094512 No
Added a0c7f4ec9cccef2d89672a624a4e6c8237a17572efdd4679eea9e9ee70d2db04:0 10072679 2094513 Yes
Spent 25e0df5cc1aeb1b78e6056bf403e5e8b7e41f138060ca0a50a50134df0549a5e:2 540 2094508 No
Spent 42f383c04e09c26a2378272ec33aa0c1bf4883ca5ab739e8b7e06be5a5787d61:1 3848399 2007724 No
Added f85e3b4b89270863a389395cc9a4123e417ab19384cef96533c6649abd6b0561:0 3788399 2094513 No
Added f85e3b4b89270863a389395cc9a4123e417ab19384cef96533c6649abd6b0561:2 540 2094513 No
Spent a05880b8c77971ed0b9f73062c7c4cdb0ff3856ab14cbf8bc481ed571cd34b83:1 5591281046 2094511 No
Added eb689865f7d957938978d6207918748f74e6aa074f47874724327089445b0960:0 5589696005 2094513 No
Added eb689865f7d957938978d6207918748f74e6aa074f47874724327089445b0960:1 1565556 2094513 No
mempool_monitor.py
A BCC Python script producing mempool statistics and an event log. Based on the
mempool:added, mempool:removed, mempool:replaced, and mempool:rejected
tracepoints.
Statistics include incidence and rate for each event type since the script was
started (total) as well as during the last minute (1 min) and ten minutes
(10 min). The event log shows mempool events in real time, each entry
comprising a timestamp along with all event data available via the event's
tracepoint.
$ python3 contrib/tracing/mempool_monitor.py $(pidof bitcoind)
Mempool Monitor
Press CTRL-C to stop.
┌─Event count───────────────────────┐ ┌─Event rate──────────────────────────┐
│ Event total 1 min 10 min │ │ Event total 1 min 10 min │
│ added 1425tx 201tx 1425tx │ │ added 4.7tx/s 3.4tx/s 4.7tx/s │
│ removed 35tx 4tx 35tx │ │ removed 0.1tx/s 0.1tx/s 0.1tx/s │
│ replaced 35tx 4tx 35tx │ │ replaced 0.1tx/s 0.1tx/s 0.1tx/s │
│ rejected 0tx 0tx 0tx │ │ rejected 0.0tx/s 0.0tx/s 0.0tx/s │
└───────────────────────────────────┘ └─────────────────────────────────────┘
┌─Event log────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ 13:10:30Z added f9064ca5bfc87cdd191faa42bf697217cd920b2b94838c1f1192e4f06c4fd217 with feerate 8.92 sat/vB (981 sat, 110 vbytes) │
│ 13:10:30Z added 53ffa3afbe57b1bfe423e1755ca2b52c5b6cb4aa91b8b7ee9cb694953f47f234 with feerate 5.00 sat/vB (550 sat, 110 vbytes) │
│ 13:10:30Z added 4177df5e19465eb5e53c3f8b6830a293f57474921bc6c2ae89375e0986e1f0f9 with feerate 2.98 sat/vB (429 sat, 144 vbytes) │
│ 13:10:30Z added 931a10d83f0a268768da75dc4b9e199f2f055f12979ae5491cc304ee10f890ea with feerate 3.55 sat/vB (500 sat, 141 vbytes) │
│ 13:10:30Z added 4cf32b295723cc4ab73f2a2e51d4bb276c0042760a4c00a3eb9595b8ebb24721 with feerate 89.21 sat/vB (12668 sat, 142 vbytes) │
│ 13:10:31Z replaced d1eecf9d662121322f4f31f0c2267a752d14bb3956e6016ba96e87f47890e1db with feerate 27.12 sat/vB received 23.3 seconds ago (7213 sat, 266 vbytes) with c412db908│
│ 9b7ed53f3e5e36d2819dd291278b59ccaabaeb17fd37c3d87fdcd57 with feerate 28.12 sat/vB (8351 sat, 297 vbytes) │
│ 13:10:31Z added c412db9089b7ed53f3e5e36d2819dd291278b59ccaabaeb17fd37c3d87fdcd57 with feerate 28.12 sat/vB (8351 sat, 297 vbytes) │
│ 13:10:31Z added b8388a5bdc421b11460bdf477d5a85a1a39c2784e7dd7bffabe688740424ea57 with feerate 25.21 sat/vB (3554 sat, 141 vbytes) │
│ 13:10:31Z added 4ddb88bc90a122cd9eae8a664e73bdf5bebe75f3ef901241b4a251245854a98e with feerate 24.15 sat/vB (5072 sat, 210 vbytes) │
│ 13:10:31Z added 19101e4161bca5271ad5d03e7747f2faec7793b274dc2f3c4cf516b7cef1aac3 with feerate 7.06 sat/vB (1080 sat, 153 vbytes) │
│ 13:10:31Z removed d1eecf9d662121322f4f31f0c2267a752d14bb3956e6016ba96e87f47890e1db with feerate 27.12 sat/vB (7213 sat, 266 vbytes): replaced │
│ 13:10:31Z added 6c511c60d9b95b9eff81df6ecba5c86780f513fe62ce3ad6be2c5340d957025a with feerate 4.00 sat/vB (440 sat, 110 vbytes) │
│ 13:10:31Z added 44d66f7f004bd52c46be4dff3067cab700e51c7866a84282bd8aab560a5bfb79 with feerate 3.15 sat/vB (448 sat, 142 vbytes) │
│ 13:10:31Z added b17b7c9ec5acfbbf12f0eeef8e29826fad3105bb95eef7a47d2f1f22b4784643 with feerate 4.10 sat/vB (1348 sat, 329 vbytes) │
│ 13:10:31Z added b7a4ad93554e57454e8a8049bfc0bd803fa962bd3f0a08926aa72e7cb23e2276 with feerate 1.01 sat/vB (205 sat, 202 vbytes) │
│ 13:10:32Z added c78e87be86c828137a6e7e00a177c03b52202ce4c39029b99904c2a094b9da87 with feerate 11.00 sat/vB (1562 sat, 142 vbytes) │
│ │
└──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
Verify Binaries
Preparation
As of Bitcoin Core v22.0, releases are signed by a number of public keys on the basis of the guix.sigs repository. When verifying binary downloads, you (the end user) decide which of these public keys you trust and then use that trust model to evaluate the signature on a file that contains hashes of the release binaries. The downloaded binaries are then hashed and compared to the signed checksum file.
First, you have to figure out which public keys to recognize. Browse the list of frequent builder-keys and decide which of these keys you would like to trust. For each key you want to trust, you must obtain that key for your local GPG installation.
You can obtain these keys by
- through a browser using a key server (e.g. keyserver.ubuntu.com),
- manually using the
gpg --keyserver <url> --recv-keys <key>command, or - you can run the packaged
verify.py --import-keys ...script to have it automatically retrieve unrecognized keys.
Usage
This script attempts to download the checksum file (SHA256SUMS) and corresponding
signature file SHA256SUMS.asc from https://bitcoincore.org and https://bitcoin.org.
It first checks if the checksum file is valid based upon a plurality of signatures, and then downloads the release files specified in the checksum file, and checks if the hashes of the release files are as expected.
If we encounter pubkeys in the signature file that we do not recognize, the script
can prompt the user as to whether they'd like to download the pubkeys. To enable
this behavior, use the --import-keys flag.
The script returns 0 if everything passes the checks. It returns 1 if either the signature check or the hash check doesn't pass. An exit code of >2 indicates an error.
See the Config object for various options.
Examples
Validate releases with default settings:
./contrib/verify-binaries/verify.py pub 22.0
./contrib/verify-binaries/verify.py pub 22.0-rc3
Get JSON output and don't prompt for user input (no auto key import):
./contrib/verify-binaries/verify.py --json pub 22.0-x86
./contrib/verify-binaries/verify.py --json pub 23.0-rc5-linux-gnu
Rely only on local GPG state and manually specified keys, while requiring a threshold of at least 10 trusted signatures:
./contrib/verify-binaries/verify.py \
--trusted-keys 74E2DEF5D77260B98BC19438099BAD163C70FBFA,9D3CC86A72F8494342EA5FD10A41BDC3F4FAFF1C \
--min-good-sigs 10 pub 22.0-linux
If you only want to download the binaries for a certain architecture and/or platform, add the corresponding suffix, e.g.:
./contrib/verify-binaries/verify.py pub 25.2-x86_64-linux
./contrib/verify-binaries/verify.py pub 24.1-rc1-darwin
./contrib/verify-binaries/verify.py pub 27.0-win64-setup.exe
If you do not want to keep the downloaded binaries, specify the cleanup option.
./contrib/verify-binaries/verify.py pub --cleanup 22.0
Use the bin subcommand to verify all files listed in a local checksum file
./contrib/verify-binaries/verify.py bin SHA256SUMS
Verify only a subset of the files listed in a local checksum file
./contrib/verify-binaries/verify.py bin ~/Downloads/SHA256SUMS \
~/Downloads/bitcoin-24.0.1-x86_64-linux-gnu.tar.gz \
~/Downloads/bitcoin-24.0.1-arm-linux-gnueabihf.tar.gz
Tooling for verification of PGP signed commits
This is an incomplete work in progress, but currently includes a pre-push hook
script (pre-push-hook.sh) for maintainers to ensure that their own commits
are PGP signed (nearly always merge commits), as well as a Python 3 script to verify
commits against a trusted keys list.
Using verify-commits.py safely
Remember that you can't use an untrusted script to verify itself. This means
that checking out code, then running verify-commits.py against HEAD is
not safe, because the version of verify-commits.py that you just ran could
be backdoored. Instead, you need to use a trusted version of verify-commits
prior to checkout to make sure you're checking out only code signed by trusted
keys:
git fetch origin && \
./contrib/verify-commits/verify-commits.py origin/master && \
git checkout origin/master
Note that the above isn't a good UI/UX yet, and needs significant improvements to make it more convenient and reduce the chance of errors; pull-reqs improving this process would be much appreciated.
Unless --clean-merge 0 is specified, verify-commits.py will attempt to verify that
each merge commit applies cleanly (with some exceptions). This requires using at least
git v2.38.0.
Configuration files
trusted-git-root: This file should contain a single git commit hash which is the first unsigned git commit (hence it is the "root of trust").trusted-sha512-root-commit: This file should contain a single git commit hash which is the first commit without a SHA512 root commitment.trusted-keys: This file should contain a \n-delimited list of all PGP fingerprints of authorized commit signers (primary, not subkeys).allow-revsig-commits: This file should contain a \n-delimited list of git commit hashes. See next section for more info.
Import trusted keys
In order to check the commit signatures, you must add the trusted PGP keys to your machine. GnuPG may be used to import the trusted keys by running the following command:
gpg --keyserver hkps://keys.openpgp.org --recv-keys $(<contrib/verify-commits/trusted-keys)
Key expiry/revocation
When a key (or subkey) which has signed old commits expires or is revoked,
verify-commits will start failing to verify all commits which were signed by
said key. In order to avoid bumping the root-of-trust trusted-git-root
file, individual commits which were signed by such a key can be added to the
allow-revsig-commits file. That way, the PGP signatures are still verified
but no new commits can be signed by any expired/revoked key. To easily build a
list of commits which need to be added, verify-commits.py can be edited to test
each commit with BITCOIN_VERIFY_COMMITS_ALLOW_REVSIG set to both 1 and 0, and
those which need it set to 1 printed.
Usage
To build dependencies for the current arch+OS:
make
To build for another arch/OS:
make HOST=host-platform-triplet
For example:
make HOST=x86_64-w64-mingw32 -j4
When configuring Bitcoin Core, CMake by default will ignore the depends output. In
order for it to pick up libraries, tools, and settings from the depends build,
you must specify the toolchain file.
In the above example, a file named depends/x86_64-w64-mingw32/toolchain.cmake will be
created. To use it during configuring Bitcoin Core:
cmake -B build --toolchain depends/x86_64-w64-mingw32/toolchain.cmake
Common host-platform-triplets for cross compilation are:
i686-pc-linux-gnufor Linux x86 32 bitx86_64-pc-linux-gnufor Linux x86 64 bitx86_64-w64-mingw32for Win64x86_64-apple-darwinfor macOSarm64-apple-darwinfor ARM macOSarm-linux-gnueabihffor Linux ARM 32 bitaarch64-linux-gnufor Linux ARM 64 bitpowerpc64-linux-gnufor Linux POWER 64 bit (big endian)powerpc64le-linux-gnufor Linux POWER 64 bit (little endian)riscv32-linux-gnufor Linux RISC-V 32 bitriscv64-linux-gnufor Linux RISC-V 64 bits390x-linux-gnufor Linux S390X
The paths are automatically configured and no other options are needed.
Install the required dependencies: Ubuntu & Debian
Common
apt install cmake curl make patch
GUI
Skip the following packages if you don't intend to use the GUI and will build with NO_QT=1:
apt install bison g++ pkg-config python3 xz-utils
For macOS cross compilation
apt install clang lld llvm zip
Clang 18 or later is required. You must also obtain the macOS SDK before
proceeding with a cross-compile. Under the depends directory, create a
subdirectory named SDKs. Then, place the extracted SDK under this new directory.
For more information, see SDK Extraction.
For Win64 cross compilation
apt install g++-mingw-w64-x86-64-posix
For linux (including i386, ARM) cross compilation
Common linux dependencies:
sudo apt-get install g++-multilib binutils
For linux ARM cross compilation:
sudo apt-get install g++-arm-linux-gnueabihf binutils-arm-linux-gnueabihf
For linux AARCH64 cross compilation:
sudo apt-get install g++-aarch64-linux-gnu binutils-aarch64-linux-gnu
For linux POWER 64-bit cross compilation (there are no packages for 32-bit):
sudo apt-get install g++-powerpc64-linux-gnu binutils-powerpc64-linux-gnu g++-powerpc64le-linux-gnu binutils-powerpc64le-linux-gnu
For linux RISC-V 64-bit cross compilation (there are no packages for 32-bit):
sudo apt-get install g++-riscv64-linux-gnu binutils-riscv64-linux-gnu
For linux S390X cross compilation:
sudo apt-get install g++-s390x-linux-gnu binutils-s390x-linux-gnu
Install the required dependencies: FreeBSD
pkg install bash
Install the required dependencies: NetBSD
pkgin install bash gmake
Install the required dependencies: OpenBSD
pkg_add bash gmake gtar
Dependency Options
The following can be set when running make: make FOO=bar
SOURCES_PATH: Downloaded sources will be placed hereBASE_CACHE: Built packages will be placed hereSDK_PATH: Path where SDKs can be found (used by macOS)FALLBACK_DOWNLOAD_PATH: If a source file can't be fetched, try here before giving upC_STANDARD: Set the C standard version used. Defaults toc11.CXX_STANDARD: Set the C++ standard version used. Defaults toc++20.NO_BOOST: Don't download/build/cache BoostNO_LIBEVENT: Don't download/build/cache LibeventNO_QT: Don't download/build/cache Qt and its dependenciesNO_QR: Don't download/build/cache packages needed for enabling qrencodeNO_ZMQ: Don't download/build/cache packages needed for enabling ZeroMQNO_WALLET: Don't download/build/cache libs needed to enable the walletNO_BDB: Don't download/build/cache BerkeleyDBNO_SQLITE: Don't download/build/cache SQLiteNO_USDT: Don't download/build/cache packages needed for enabling USDT tracepointsMULTIPROCESS: Build libmultiprocess (experimental)DEBUG: Disable some optimizations and enable more runtime checkingHOST_ID_SALT: Optional salt to use when generating host package idsBUILD_ID_SALT: Optional salt to use when generating build package idsLOG: Use file-based logging for individual packages. During a package build its log file resides in thedependsdirectory, and the log file is printed out automatically in case of build error. After successful build log files are moved along with package archivesLTO: Enable options needed for LTO. Does not add-fltorelated options to *FLAGS.NO_HARDEN=1: Don't use hardening options when building packages
If some packages are not built, for example make NO_WALLET=1, the appropriate CMake cache
variables will be set when generating the Bitcoin Core buildsystem. In this case, -DENABLE_WALLET=OFF.
Additional targets
download: run 'make download' to fetch all sources without building them
download-osx: run 'make download-osx' to fetch all sources needed for macOS builds
download-win: run 'make download-win' to fetch all sources needed for win builds
download-linux: run 'make download-linux' to fetch all sources needed for linux builds
Other documentation
- description.md: General description of the depends system
- packages.md: Steps for adding packages
This is a system of building and caching dependencies necessary for building Bitcoin. There are several features that make it different from most similar systems:
It is designed to be builder and host agnostic
In theory, binaries for any target OS/architecture can be created, from a builder running any OS/architecture. In practice, build-side tools must be specified when the defaults don't fit, and packages must be amended to work on new hosts.
No reliance on timestamps
File presence is used to determine what needs to be built. This makes the results distributable and easily digestible by automated builders.
Each build only has its specified dependencies available at build-time.
For each build, the sysroot is wiped and the (recursive) dependencies are installed. This makes each build deterministic, since there will never be any unknown files available to cause side-effects.
Each package is cached and only rebuilt as needed.
Before building, a unique build-id is generated for each package. This id consists of a hash of all files used to build the package (Makefiles, packages, etc), and as well as a hash of the same data for each recursive dependency. If any portion of a package's build recipe changes, it will be rebuilt as well as any other package that depends on it. If any of the main makefiles (Makefile, funcs.mk, etc) are changed, all packages will be rebuilt. After building, the results are cached into a tarball that can be reused and distributed.
Package build results are (relatively) deterministic.
Each package is configured and patched so that it will yield the same build-results with each consequent build, within a reasonable set of constraints. Some things like timestamp insertion are unavoidable, and are beyond the scope of this system. Additionally, the toolchain itself must be capable of deterministic results. When revisions are properly bumped, a cached build should represent an exact single payload.
Sources are fetched and verified automatically
Each package must define its source location and checksum. The build will fail if the fetched source does not match. Sources may be pre-seeded and/or cached as desired.
Self-cleaning
Build and staging dirs are wiped after use, and any previous version of a cached result is removed following a successful build. Automated builders should be able to build each revision and store the results with no further intervention.
Each recipe consists of 3 main parts: defining identifiers, setting build variables, and defining build commands.
The package "mylib" will be used here as an example
General tips:
- mylib_foo is written as $(package)_foo in order to make recipes more similar.
- Secondary dependency packages relative to the bitcoin binaries/libraries (i.e.
those not in
ALLOWED_LIBRARIESincontrib/devtools/symbol-check.py) don't need to be shared and should be built statically whenever possible. See below for more details.
Identifiers
Each package is required to define at least these variables:
$(package)_version:
Version of the upstream library or program. If there is no version, a
placeholder such as 1.0 can be used.
$(package)_download_path:
Location of the upstream source, without the file-name. Usually http, https
or ftp. Secure transmission options like https should be preferred if
available.
$(package)_file_name:
The upstream source filename available at the download path.
$(package)_sha256_hash:
The sha256 hash of the upstream file
These variables are optional:
$(package)_build_subdir:
cd to this dir before running configure/build/stage commands.
$(package)_download_file:
The file-name of the upstream source if it differs from how it should be
stored locally. This can be used to avoid storing file-names with strange
characters.
$(package)_dependencies:
Names of any other packages that this one depends on.
$(package)_patches:
Filenames of any patches needed to build the package
$(package)_extra_sources:
Any extra files that will be fetched via $(package)_fetch_cmds. These are
specified so that they can be fetched and verified via 'make download'.
Build Variables:
After defining the main identifiers, build variables may be added or customized before running the build commands. They should be added to a function called $(package)_set_vars. For example:
define $(package)_set_vars
...
endef
Most variables can be prefixed with the host, architecture, or both, to make the modifications specific to that case. For example:
Universal: $(package)_cc=gcc
Linux only: $(package)_linux_cc=gcc
x86_64 only: $(package)_x86_64_cc = gcc
x86_64 linux only: $(package)_x86_64_linux_cc = gcc
These variables may be set to override or append their default values.
$(package)_cc
$(package)_cxx
$(package)_objc
$(package)_objcxx
$(package)_ar
$(package)_ranlib
$(package)_nm
$(package)_cflags
$(package)_cxxflags
$(package)_ldflags
$(package)_cppflags
$(package)_config_env
$(package)_build_env
$(package)_stage_env
$(package)_build_opts
$(package)_config_opts
The *_env variables are used to add environment variables to the respective commands.
Many variables respect a debug/release suffix as well, in order to use them for only the appropriate build config. For example:
$(package)_cflags_release = -O3
$(package)_cflags_i686_debug = -g
$(package)_config_opts_release = --disable-debug
These will be used in addition to the options that do not specify debug/release. All builds are considered to be release unless DEBUG=1 is set by the user. Other variables may be defined as needed.
Build commands:
For each build, a unique build dir and staging dir are created. For example,
work/build/mylib/1.0-1adac830f6e and work/staging/mylib/1.0-1adac830f6e.
The following build commands are available for each recipe:
$(package)_fetch_cmds:
Runs from: build dir
Fetch the source file. If undefined, it will be fetched and verified
against its hash.
$(package)_extract_cmds:
Runs from: build dir
Verify the source file against its hash and extract it. If undefined, the
source is assumed to be a tarball.
$(package)_preprocess_cmds:
Runs from: build dir/$(package)_build_subdir
Preprocess the source as necessary. If undefined, does nothing.
$(package)_config_cmds:
Runs from: build dir/$(package)_build_subdir
Configure the source. If undefined, does nothing.
$(package)_build_cmds:
Runs from: build dir/$(package)_build_subdir
Build the source. If undefined, does nothing.
$(package)_stage_cmds:
Runs from: build dir/$(package)_build_subdir
Stage the build results. If undefined, does nothing.
The following variables are available for each recipe:
$(1)_staging_dir: package's destination sysroot path
$(1)_staging_prefix_dir: prefix path inside of the package's staging dir
$(1)_extract_dir: path to the package's extracted sources
$(1)_build_dir: path where configure/build/stage commands will be run
$(1)_patch_dir: path where the package's patches (if any) are found
Notes on build commands:
For packages built with autotools, $($(package)_autoconf) can be used in the configure step to (usually) correctly configure automatically. Any $($(package)_config_opts) will be appended.
Most autotools projects can be properly staged using:
$(MAKE) DESTDIR=$($(package)_staging_dir) install
Build outputs:
In general, the output of a depends package should not contain any libtool
archives. Instead, the package should output .pc (pkg-config) files where
possible.
From the Gentoo Wiki entry:
Libtool pulls in all direct and indirect dependencies into the .la files it creates. This leads to massive overlinking, which is toxic to the Gentoo ecosystem, as it leads to a massive number of unnecessary rebuilds.
Where possible, packages are built with Position Independent Code. Either using
the Autotools --with-pic flag, or CMAKE_POSITION_INDEPENDENT_CODE with CMake.
Secondary dependencies:
Secondary dependency packages relative to the bitcoin binaries/libraries (i.e.
those not in ALLOWED_LIBRARIES in contrib/devtools/symbol-check.py) don't
need to be shared and should be built statically whenever possible. This
improves general build reliability as illustrated by the following example:
When linking an executable against a shared library libprimary that has its
own shared dependency libsecondary, we may need to specify the path to
libsecondary on the link command using the -rpath/-rpath-link options, it is
not sufficient to just say libprimary.
For us, it's much easier to just link a static libsecondary into a shared
libprimary. Especially because in our case, we are linking against a dummy
libprimary anyway that we'll throw away. We don't care if the end-user has a
static or dynamic libsecondary, that's not our concern. With a static
libsecondary, when we need to link libprimary into our executable, there's no
dependency chain to worry about as libprimary has all the symbols.
Build targets:
To build an individual package (useful for debugging), following build targets are available.
make ${package}
make ${package}_fetched
make ${package}_extracted
make ${package}_preprocessed
make ${package}_configured
make ${package}_built
make ${package}_staged
make ${package}_postprocessed
make ${package}_cached
make ${package}_cached_checksum
Bitcoin Core
Setup
Bitcoin Core is the original Bitcoin client and it builds the backbone of the network. It downloads and, by default, stores the entire history of Bitcoin transactions, which requires several hundred gigabytes or more of disk space. Depending on the speed of your computer and network connection, the synchronization process can take anywhere from a few hours to several days or more.
To download Bitcoin Core, visit bitcoincore.org.
Running
The following are some helpful notes on how to run Bitcoin Core on your native platform.
Unix
Unpack the files into a directory and run:
bin/bitcoin-qt(GUI) orbin/bitcoind(headless)
Windows
Unpack the files into a directory, and then run bitcoin-qt.exe.
macOS
Drag Bitcoin Core to your applications folder, and then run Bitcoin Core.
Need Help?
- See the documentation at the Bitcoin Wiki for help and more information.
- Ask for help on Bitcoin StackExchange.
- Ask for help on #bitcoin on Libera Chat. If you don't have an IRC client, you can use web.libera.chat.
- Ask for help on the BitcoinTalk forums, in the Technical Support board.
Building
The following are developer notes on how to build Bitcoin Core on your native platform. They are not complete guides, but include notes on the necessary libraries, compile flags, etc.
- Dependencies
- macOS Build Notes
- Unix Build Notes
- Windows Build Notes
- FreeBSD Build Notes
- OpenBSD Build Notes
- NetBSD Build Notes
Development
The Bitcoin repo's root README contains relevant information on the development process and automated testing.
- Developer Notes
- Productivity Notes
- Release Process
- Source Code Documentation (External Link)
- Translation Process
- Translation Strings Policy
- JSON-RPC Interface
- Unauthenticated REST Interface
- BIPS
- Dnsseed Policy
- Benchmarking
- Internal Design Docs
Resources
- Discuss on the BitcoinTalk forums, in the Development & Technical Discussion board.
- Discuss project-specific development on #bitcoin-core-dev on Libera Chat. If you don't have an IRC client, you can use web.libera.chat.
Miscellaneous
- Assets Attribution
- bitcoin.conf Configuration File
- CJDNS Support
- Files
- Fuzz-testing
- I2P Support
- Init Scripts (systemd/upstart/openrc)
- Managing Wallets
- Multisig Tutorial
- Offline Signing Tutorial
- P2P bad ports definition and list
- PSBT support
- Reduce Memory
- Reduce Traffic
- Tor Support
- Transaction Relay Policy
- ZMQ
License
Distributed under the MIT software license.
JSON-RPC Interface
The headless daemon bitcoind has the JSON-RPC API enabled by default, the GUI
bitcoin-qt has it disabled by default. This can be changed with the -server
option. In the GUI it is possible to execute RPC methods in the Debug Console
Dialog.
Endpoints
There are two JSON-RPC endpoints on the server:
//wallet/<walletname>/
/ endpoint
This endpoint is always active. It can always service non-wallet requests and can service wallet requests when exactly one wallet is loaded.
/wallet/<walletname>/ endpoint
This endpoint is only activated when the wallet component has been compiled in. It can service both wallet and non-wallet requests. It MUST be used for wallet requests when two or more wallets are loaded.
This is the endpoint used by bitcoin-cli when a -rpcwallet= parameter is passed in.
Best practice would dictate using the /wallet/<walletname>/ endpoint for ALL
requests when multiple wallets are in use.
Examples
# Get block count from the / endpoint when rpcuser=alice and rpcport=38332
$ curl --user alice --data-binary '{"jsonrpc": "2.0", "id": "0", "method": "getblockcount", "params": []}' -H 'content-type: application/json' localhost:38332/
# Get balance from the /wallet/walletname endpoint when rpcuser=alice, rpcport=38332 and rpcwallet=desc-wallet
$ curl --user alice --data-binary '{"jsonrpc": "2.0", "id": "0", "method": "getbalance", "params": []}' -H 'content-type: application/json' localhost:38332/wallet/desc-wallet
Parameter passing
The JSON-RPC server supports both by-position and by-name parameter
structures
described in the JSON-RPC specification. For extra convenience, to avoid the
need to name every parameter value, all RPC methods accept a named parameter
called args, which can be set to an array of initial positional values that
are combined with named values.
Examples:
# "params": ["mywallet", false, false, "", false, false, true]
bitcoin-cli createwallet mywallet false false "" false false true
# "params": {"wallet_name": "mywallet", "load_on_startup": true}
bitcoin-cli -named createwallet wallet_name=mywallet load_on_startup=true
# "params": {"args": ["mywallet"], "load_on_startup": true}
bitcoin-cli -named createwallet mywallet load_on_startup=true
Versioning
The RPC interface might change from one major version of Bitcoin Core to the
next. This makes the RPC interface implicitly versioned on the major version.
The version tuple can be retrieved by e.g. the getnetworkinfo RPC in
version.
Usually deprecated features can be re-enabled during the grace-period of one
major version via the -deprecatedrpc= command line option. The release notes
of a new major release come with detailed instructions on what RPC features
were deprecated and how to re-enable them temporarily.
JSON-RPC 1.1 vs 2.0
The server recognizes JSON-RPC v2.0 requests
and responds accordingly. A 2.0 request is identified by the presence of
"jsonrpc": "2.0" in the request body. If that key + value is not present in a request,
the legacy JSON-RPC v1.1 protocol is followed instead, which was the only available
protocol in v27.0 and prior releases.
| 1.1 | 2.0 | |
|---|---|---|
| Request marker | "version": "1.1" (or none) | "jsonrpc": "2.0" |
| Response marker | (none) | "jsonrpc": "2.0" |
"error" and "result" fields in response | both present | only one is present |
| HTTP codes in response | 200 unless there is any kind of RPC error (invalid parameters, method not found, etc) | Always 200 unless there is an actual HTTP server error (request parsing error, endpoint not found, etc) |
| Notifications: requests that get no reply | (not supported) | Supported for requests that exclude the "id" field. Returns HTTP status 204 "No Content" |
Security
The RPC interface allows other programs to control Bitcoin Core, including the ability to spend funds from your wallets, affect consensus verification, read private data, and otherwise perform operations that can cause loss of money, data, or privacy. This section suggests how you should use and configure Bitcoin Core to reduce the risk that its RPC interface will be abused.
-
Securing the executable: Anyone with physical or remote access to the computer, container, or virtual machine running Bitcoin Core can compromise either the whole program or just the RPC interface. This includes being able to record any passphrases you enter for unlocking your encrypted wallets or changing settings so that your Bitcoin Core program tells you that certain transactions have multiple confirmations even when they aren't part of the best block chain. For this reason, you should not use Bitcoin Core for security sensitive operations on systems you do not exclusively control, such as shared computers or virtual private servers.
-
Securing local network access: By default, the RPC interface can only be accessed by a client running on the same computer and only after the client provides a valid authentication credential (username and passphrase). Any program on your computer with access to the file system and local network can obtain this level of access. Additionally, other programs on your computer can attempt to provide an RPC interface on the same port as used by Bitcoin Core in order to trick you into revealing your authentication credentials. For this reason, it is important to only use Bitcoin Core for security-sensitive operations on a computer whose other programs you trust.
-
Securing remote network access: You may optionally allow other computers to remotely control Bitcoin Core by setting the
rpcallowipandrpcbindconfiguration parameters. These settings are only meant for enabling connections over secure private networks or connections that have been otherwise secured (e.g. using a VPN or port forwarding with SSH or stunnel). Do not enable RPC connections over the public Internet. Although Bitcoin Core's RPC interface does use authentication, it does not use encryption, so your login credentials are sent as clear text that can be read by anyone on your network path. Additionally, the RPC interface has not been hardened to withstand arbitrary Internet traffic, so changing the above settings to expose it to the Internet (even using something like a Tor onion service) could expose you to unconsidered vulnerabilities. Seebitcoind -helpfor more information about these settings and other settings described in this document.Related, if you use Bitcoin Core inside a Docker container, you may need to expose the RPC port to the host system. The default way to do this in Docker also exposes the port to the public Internet. Instead, expose it only on the host system's localhost, for example:
-p 127.0.0.1:8332:8332 -
Secure authentication: By default, when no
rpcpasswordis specified, Bitcoin Core generates unique login credentials each time it restarts and puts them into a file readable only by the user that started Bitcoin Core, allowing any of that user's RPC clients with read access to the file to login automatically. The file is.cookiein the Bitcoin Core configuration directory, and using these credentials is the preferred RPC authentication method. If you need to generate static login credentials for your programs, you can use the script in theshare/rpcauthdirectory in the Bitcoin Core source tree. As a final fallback, you can directly use manually-chosenrpcuserandrpcpasswordconfiguration parameters---but you must ensure that you choose a strong and unique passphrase (and still don't use insecure networks, as mentioned above). -
Secure string handling: The RPC interface does not guarantee any escaping of data beyond what's necessary to encode it as JSON, although it does usually provide serialized data using a hex representation of the bytes. If you use RPC data in your programs or provide its data to other programs, you must ensure any problem strings are properly escaped. For example, the
createwalletRPC accepts arguments such aswallet_namewhich is a string and could be used for a path traversal attack without application level checks. Multiple websites have been manipulated because they displayed decoded hex strings that included HTML<script>tags. For this reason, and others, it is recommended to display all serialized data in hex form only.
RPC consistency guarantees
State that can be queried via RPCs is guaranteed to be at least up-to-date with the chain state immediately prior to the call's execution. However, the state returned by RPCs that reflect the mempool may not be up-to-date with the current mempool state.
Transaction Pool
The mempool state returned via an RPC is consistent with itself and with the chain state at the time of the call. Thus, the mempool state only encompasses transactions that are considered mine-able by the node at the time of the RPC.
The mempool state returned via an RPC reflects all effects of mempool and chain state related RPCs that returned prior to this call.
Wallet
The wallet state returned via an RPC is consistent with itself and with the chain state at the time of the call.
Wallet RPCs will return the latest chain state consistent with prior non-wallet RPCs. The effects of all blocks (and transactions in blocks) at the time of the call is reflected in the state of all wallet transactions. For example, if a block contains transactions that conflicted with mempool transactions, the wallet would reflect the removal of these mempool transactions in the state.
However, the wallet may not be up-to-date with the current state of the mempool or the state of the mempool by an RPC that returned before this RPC. For example, a wallet transaction that was BIP-125-replaced in the mempool prior to this RPC may not yet be reflected as such in this RPC response.
Limitations
There is a known issue in the JSON-RPC interface that can cause a node to crash if too many http connections are being opened at the same time because the system runs out of available file descriptors. To prevent this from happening you might want to increase the number of maximum allowed file descriptors in your system and try to prevent opening too many connections to your JSON-RPC interface at the same time if this is under your control. It is hard to give general advice since this depends on your system but if you make several hundred requests at once you are definitely at risk of encountering this issue.
\mainpage notitle
\section intro_sec Introduction
This is the developer documentation of the reference client for an experimental new digital currency called Bitcoin, which enables instant payments to anyone, anywhere in the world. Bitcoin uses peer-to-peer technology to operate with no central authority: managing transactions and issuing money are carried out collectively by the network.
The software is a community-driven open source project, released under the MIT license.
See https://github.com/bitcoin/bitcoin and https://bitcoincore.org/ for further information about the project.
\section Navigation
Use Modules, Namespaces, Classes, or Files at the top of the page to start navigating the code.
Unauthenticated REST Interface
The REST API can be enabled with the -rest option.
The interface runs on the same port as the JSON-RPC interface, by default port 8332 for mainnet, port 18332 for testnet, port 48332 for testnet4, port 38332 for signet, and port 18443 for regtest.
REST Interface consistency guarantees
The same guarantees as for the RPC Interface apply.
Limitations
There is a known issue in the REST interface that can cause a node to crash if too many http connections are being opened at the same time because the system runs out of available file descriptors. To prevent this from happening you might want to increase the number of maximum allowed file descriptors in your system and try to prevent opening too many connections to your rest interface at the same time if this is under your control. It is hard to give general advice since this depends on your system but if you make several hundred requests at once you are definitely at risk of encountering this issue.
Supported API
Transactions
GET /rest/tx/<TX-HASH>.<bin|hex|json>
Given a transaction hash: returns a transaction in binary, hex-encoded binary, or JSON formats. Responds with 404 if the transaction doesn't exist.
By default, this endpoint will only search the mempool. To query for a confirmed transaction, enable the transaction index via "txindex=1" command line / configuration option.
Blocks
GET /rest/block/<BLOCK-HASH>.<bin|hex|json>GET /rest/block/notxdetails/<BLOCK-HASH>.<bin|hex|json>
Given a block hash: returns a block, in binary, hex-encoded binary or JSON formats. Responds with 404 if the block doesn't exist.
The HTTP request and response are both handled entirely in-memory.
With the /notxdetails/ option JSON response will only contain the transaction hash instead of the complete transaction details. The option only affects the JSON response.
Blockheaders
GET /rest/headers/<BLOCK-HASH>.<bin|hex|json>?count=<COUNT=5>
Given a block hash: returns
Deprecated (but not removed) since 24.0:
GET /rest/headers/<COUNT>/<BLOCK-HASH>.<bin|hex|json>
Blockfilter Headers
GET /rest/blockfilterheaders/<FILTERTYPE>/<BLOCK-HASH>.<bin|hex|json>?count=<COUNT=5>
Given a block hash: returns
Deprecated (but not removed) since 24.0:
GET /rest/blockfilterheaders/<FILTERTYPE>/<COUNT>/<BLOCK-HASH>.<bin|hex|json>
Blockfilters
GET /rest/blockfilter/<FILTERTYPE>/<BLOCK-HASH>.<bin|hex|json>
Given a block hash: returns the block filter of the given block of type
Blockhash by height
GET /rest/blockhashbyheight/<HEIGHT>.<bin|hex|json>
Given a height: returns hash of block in best-block-chain at height provided. Responds with 404 if block not found.
Chaininfos
GET /rest/chaininfo.json
Returns various state info regarding block chain processing.
Only supports JSON as output format.
Refer to the getblockchaininfo RPC help for details.
Deployment info
GET /rest/deploymentinfo.json
GET /rest/deploymentinfo/<BLOCKHASH>.json
Returns an object containing various state info regarding deployments of
consensus changes at the current chain tip, or at getdeploymentinfo RPC help for details.
Query UTXO set
GET /rest/getutxos/<TXID>-<N>/<TXID>-<N>/.../<TXID>-<N>.<bin|hex|json>GET /rest/getutxos/checkmempool/<TXID>-<N>/<TXID>-<N>/.../<TXID>-<N>.<bin|hex|json>
The getutxos endpoint allows querying the UTXO set, given a set of outpoints.
With the /checkmempool/ option, the mempool is also taken into account.
See BIP64 for
input and output serialization (relevant for bin and hex output formats).
Example:
$ curl localhost:18332/rest/getutxos/checkmempool/b2cdfd7b89def827ff8af7cd9bff7627ff72e5e8b0f71210f92ea7a4000c5d75-0.json 2>/dev/null | json_pp
{
"chainHeight" : 325347,
"chaintipHash" : "00000000fb01a7f3745a717f8caebee056c484e6e0bfe4a9591c235bb70506fb",
"bitmap": "1",
"utxos" : [
{
"height" : 2147483647,
"value" : 8.8687,
"scriptPubKey" : {
"asm" : "OP_DUP OP_HASH160 1c7cebb529b86a04c683dfa87be49de35bcf589e OP_EQUALVERIFY OP_CHECKSIG",
"desc" : "addr(mi7as51dvLJsizWnTMurtRmrP8hG2m1XvD)#gj9tznmy",
"hex" : "76a9141c7cebb529b86a04c683dfa87be49de35bcf589e88ac",
"type" : "pubkeyhash",
"address" : "mi7as51dvLJsizWnTMurtRmrP8hG2m1XvD"
}
}
]
}
Memory pool
GET /rest/mempool/info.json
Returns various information about the transaction mempool.
Only supports JSON as output format.
Refer to the getmempoolinfo RPC help for details.
GET /rest/mempool/contents.json?verbose=<true|false>&mempool_sequence=<false|true>
Returns the transactions in the mempool.
Only supports JSON as output format.
Refer to the getrawmempool RPC help for details. Defaults to setting
verbose=true and mempool_sequence=false.
Query parameters for verbose and mempool_sequence available in 25.0 and up.
Risks
Running a web browser on the same node with a REST enabled bitcoind can be a risk. Accessing prepared XSS websites could read out tx/block data of your node by placing links like <script src="http://127.0.0.1:8332/rest/tx/1234567890.json"> which might break the nodes privacy.
The list of assets used in the bitcoin source and their attribution can now be found in contrib/debian/copyright.
Assumeutxo Usage
Assumeutxo is a feature that allows fast bootstrapping of a validating bitcoind instance.
For notes on the design of Assumeutxo, please refer to the design doc.
Loading a snapshot
There is currently no canonical source for snapshots, but any downloaded snapshot
will be checked against a hash that's been hardcoded in source code. If there is
no source for the snapshot you need, you can generate it yourself using
dumptxoutset on another node that is already synced (see
Generating a snapshot).
Once you've obtained the snapshot, you can use the RPC command loadtxoutset to
load it.
$ bitcoin-cli -rpcclienttimeout=0 loadtxoutset /path/to/input
After the snapshot has loaded, the syncing process of both the snapshot chain
and the background IBD chain can be monitored with the getchainstates RPC.
Pruning
A pruned node can load a snapshot. To save space, it's possible to delete the
snapshot file as soon as loadtxoutset finishes.
The minimum -prune setting is 550 MiB, but this functionality ignores that
minimum and uses at least 1100 MiB.
As the background sync continues there will be temporarily two chainstate directories, each multiple gigabytes in size (likely growing larger than the downloaded snapshot).
Indexes
Indexes work but don't take advantage of this feature. They always start building from the genesis block and can only apply blocks in order. Once the background validation reaches the snapshot block, indexes will continue to build all the way to the tip.
For indexes that support pruning, note that these indexes only allow blocks that were already indexed to be pruned. Blocks that are not indexed yet will also not be pruned.
This means that, if the snapshot is old, then a lot of blocks after the snapshot block will need to be downloaded, and these blocks can't be pruned until they are indexed, so they could consume a lot of disk space until indexing catches up to the snapshot block.
Generating a snapshot
The RPC command dumptxoutset can be used to generate a snapshot for the current
tip (using type "latest") or a recent height (using type "rollback"). A generated
snapshot from one node can then be loaded
on any other node. However, keep in mind that the snapshot hash needs to be
listed in the chainparams to make it usable. If there is no snapshot hash for
the height you have chosen already, you will need to change the code there and
re-compile.
Using the type parameter "rollback", dumptxoutset can also be used to verify the
hardcoded snapshot hash in the source code by regenerating the snapshot and
comparing the hash.
Example usage:
$ bitcoin-cli -rpcclienttimeout=0 dumptxoutset /path/to/output rollback
For most of the duration of dumptxoutset running the node is in a temporary
state that does not actually reflect reality, i.e. blocks are marked invalid
although we know they are not invalid. Because of this it is discouraged to
interact with the node in any other way during this time to avoid inconsistent
results and race conditions, particularly RPCs that interact with blockstorage.
This inconsistent state is also why network activity is temporarily disabled,
causing us to disconnect from all peers.
dumptxoutset takes some time to complete, independent of hardware and
what parameter is chosen. Because of that it is recommended to increase the RPC
client timeout value (use -rpcclienttimeout=0 for no timeout).
Benchmarking
Bitcoin Core has an internal benchmarking framework, with benchmarks for cryptographic algorithms (e.g. SHA1, SHA256, SHA512, RIPEMD160, Poly1305, ChaCha20), rolling bloom filter, coins selection, thread queue, wallet balance.
Running
For benchmarking, you only need to compile bench_bitcoin. The bench runner
warns if you configure with -DCMAKE_BUILD_TYPE=Debug, but consider if building without
it will impact the benchmark(s) you are interested in by unlatching log printers
and lock analysis.
cmake -B build -DBUILD_BENCH=ON
cmake --build build -t bench_bitcoin
After compiling bitcoin-core, the benchmarks can be run with:
build/src/bench/bench_bitcoin
The output will look similar to:
| ns/op | op/s | err% | total | benchmark
|--------------------:|--------------------:|--------:|----------:|:----------
| 57,927,463.00 | 17.26 | 3.6% | 0.66 | `AddrManAdd`
| 677,816.00 | 1,475.33 | 4.9% | 0.01 | `AddrManGetAddr`
...
| ns/byte | byte/s | err% | total | benchmark
|--------------------:|--------------------:|--------:|----------:|:----------
| 127.32 | 7,854,302.69 | 0.3% | 0.00 | `Base58CheckEncode`
| 31.95 | 31,303,226.99 | 0.2% | 0.00 | `Base58Decode`
...
Help
build/src/bench/bench_bitcoin -h
To print the various options, like listing the benchmarks without running them or using a regex filter to only run certain benchmarks.
Notes
More benchmarks are needed for, in no particular order:
- Script Validation
- Coins database
- Memory pool
- Cuckoo Cache
- P2P throughput
Going Further
To monitor Bitcoin Core performance more in depth (like reindex or IBD): https://github.com/chaincodelabs/bitcoinperf
To generate Flame Graphs for Bitcoin Core: https://github.com/eklitzke/bitcoin/blob/flamegraphs/doc/flamegraphs.md
BIPs that are implemented by Bitcoin Core:
BIP 9: The changes allowing multiple soft-forks to be deployed in parallel have been implemented since v0.12.1 (PR #7575)BIP 11: Multisig outputs are standard since v0.6.0 (PR #669).BIP 13: The address format for P2SH addresses has been implemented since v0.6.0 (PR #669).BIP 14: The subversion string is being used as User Agent since v0.6.0 (PR #669).BIP 16: The pay-to-script-hash evaluation rules have been implemented since v0.6.0, and took effect on April 1st 2012 (PR #748).BIP 21: The URI format for Bitcoin payments has been implemented since v0.6.0 (PR #176).BIP 22: The 'getblocktemplate' (GBT) RPC protocol for mining has been implemented since v0.7.0 (PR #936).BIP 23: Some extensions to GBT have been implemented since v0.10.0rc1, including longpolling and block proposals (PR #1816).BIP 30: The evaluation rules to forbid creating new transactions with the same txid as previous not-fully-spent transactions were implemented since v0.6.0, and the rule took effect on March 15th 2012 (PR #915).BIP 31: The 'pong' protocol message (and the protocol version bump to 60001) has been implemented since v0.6.1 (PR #1081).BIP 32: Hierarchical Deterministic Wallets has been implemented since v0.13.0 (PR #8035).BIP 34: The rule that requires blocks to contain their height (number) in the coinbase input, and the introduction of version 2 blocks has been implemented since v0.7.0. The rule took effect for version 2 blocks as of block 224413 (March 5th 2013), and version 1 blocks are no longer allowed since block 227931 (March 25th 2013) (PR #1526).BIP 35: The 'mempool' protocol message (and the protocol version bump to 60002) has been implemented since v0.7.0 (PR #1641). As of v0.13.0, this is only available forNODE_BLOOM(BIP 111) peers.BIP 37: The bloom filtering for transaction relaying, partial Merkle trees for blocks, and the protocol version bump to 70001 (enabling low-bandwidth SPV clients) has been implemented since v0.8.0 (PR #1795). Disabled by default since v0.19.0, can be enabled by the-peerbloomfiltersoption.BIP 42: The bug that would have caused the subsidy schedule to resume after block 13440000 was fixed in v0.9.2 (PR #3842).BIP 43: The experimental descriptor wallets introduced in v0.21.0 by default use the Hierarchical Deterministic Wallet derivation proposed by BIP 43. (PR #16528)BIP 44: The experimental descriptor wallets introduced in v0.21.0 by default use the Hierarchical Deterministic Wallet derivation proposed by BIP 44. (PR #16528)BIP 49: The experimental descriptor wallets introduced in v0.21.0 by default use the Hierarchical Deterministic Wallet derivation proposed by BIP 49. (PR #16528)BIP 61: The 'reject' protocol message (and the protocol version bump to 70002) was added in v0.9.0 (PR #3185). Starting v0.17.0, whether to send reject messages can be configured with the-enablebip61option, and support is deprecated (disabled by default) as of v0.18.0. Support was removed in v0.20.0 (PR #15437).BIP 65: The CHECKLOCKTIMEVERIFY softfork was merged in v0.12.0 (PR #6351), and backported to v0.11.2 and v0.10.4. Mempool-only CLTV was added in PR #6124.BIP 66: The strict DER rules and associated version 3 blocks have been implemented since v0.10.0 (PR #5713).BIP 68: Sequence locks have been implemented as of v0.12.1 (PR #7184), and have been buried since v0.19.0 (PR #16060).BIP 707172: Payment Protocol support has been available in Bitcoin Core GUI since v0.9.0 (PR #5216). Support can be optionally disabled at build time since v0.18.0 (PR 14451), and it is disabled by default at build time since v0.19.0 (PR #15584). It has been removed as of v0.20.0 (PR 17165).BIP 84: The experimental descriptor wallets introduced in v0.21.0 by default use the Hierarchical Deterministic Wallet derivation proposed by BIP 84. (PR #16528)BIP 86: Descriptor wallets by default use the Hierarchical Deterministic Wallet derivation proposed by BIP 86 since v23.0 (PR #22364).BIP 90: Trigger mechanism for activation of BIPs 34, 65, and 66 has been simplified to block height checks since v0.14.0 (PR #8391).BIP 94: Testnet 4 (-testnet4) supported as of v28.0 (PR #29775).BIP 111:NODE_BLOOMservice bit added, and enforced for all peer versions as of v0.13.0 (PR #6579 and PR #6641).BIP 112: The CHECKSEQUENCEVERIFY opcode has been implemented since v0.12.1 (PR #7524), and has been buried since v0.19.0 (PR #16060).BIP 113: Median time past lock-time calculations have been implemented since v0.12.1 (PR #6566), and has been buried since v0.19.0 (PR #16060).BIP 130: direct headers announcement is negotiated with peer versions>=70012as of v0.12.0 (PR 6494).BIP 133: feefilter messages are respected and sent for peer versions>=70013as of v0.13.0 (PR 7542).BIP 141: Segregated Witness (Consensus Layer) as of v0.13.0 (PR 8149), defined for mainnet as of v0.13.1 (PR 8937), and buried since v0.19.0 (PR #16060).BIP 143: Transaction Signature Verification for Version 0 Witness Program as of v0.13.0 (PR 8149), defined for mainnet as of v0.13.1 (PR 8937), and buried since v0.19.0 (PR #16060).BIP 144: Segregated Witness as of 0.13.0 (PR 8149).BIP 145: getblocktemplate updates for Segregated Witness as of v0.13.0 (PR 8149).BIP 147: NULLDUMMY softfork as of v0.13.1 (PR 8636 and PR 8937), buried since v0.19.0 (PR #16060).BIP 152: Compact block transfer and related optimizations are used as of v0.13.0 (PR 8068).BIP 155: The 'addrv2' and 'sendaddrv2' messages which enable relay of Tor V3 addresses (and other networks) are supported as of v0.21.0 (PR 19954).BIP 157158: Compact Block Filters for Light Clients can be indexed as of v0.19.0 (PR #14121) and served to peers on the P2P network as of v0.21.0 (PR #16442).BIP 159: TheNODE_NETWORK_LIMITEDservice bit is signalled as of v0.16.0 (PR 11740), and such nodes are connected to as of v0.17.0 (PR 10387).BIP 173: Bech32 addresses for native Segregated Witness outputs are supported as of v0.16.0 (PR 11167). Bech32 addresses are generated by default as of v0.20.0 (PR 16884).BIP 174: RPCs to operate on Partially Signed Bitcoin Transactions (PSBT) are present as of v0.17.0 (PR 13557).BIP 176: Bits Denomination [QT only] is supported as of v0.16.0 (PR 12035).BIP 324: The v2 transport protocol specified by BIP324 and the associatedNODE_P2P_V2service bit are supported as of v26.0, but off by default (PR 28331). On by default as of v27.0 (PR 29347).BIP 325: Signet test network is supported as of v0.21.0 (PR 18267).BIP 339: Relay of transactions by wtxid is supported as of v0.21.0 (PR 18044).BIP 340341342: Validation rules for Taproot (including Schnorr signatures and Tapscript leaves) are implemented as of v0.21.0 (PR 19953), with mainnet activation as of v0.21.1 (PR 21377, PR 21686).BIP 350: Addresses for native v1+ segregated Witness outputs use Bech32m instead of Bech32 as of v22.0 (PR 20861).BIP 371: Taproot fields for PSBT as of v24.0 (PR 22558).BIP 379: Miniscript was partially implemented in v24.0 (PR 24148), and fully implemented as of v26.0 (PR 27255).BIP 380381382383384385: Output Script Descriptors, and most of Script Expressions are implemented as of v0.17.0 (PR 13697).BIP 386: tr() Output Script Descriptors are implemented as of v22.0 (PR 22051).BIP 387: Tapscript Multisig Output Script Descriptors are implemented as of v24.0 (PR 24043).BIP 431: transactions with nVersion=3 are standard and treated as Topologically Restricted Until Confirmation as of v28.0 (PR 29496).
bitcoin.conf Configuration File
The configuration file is used by bitcoind, bitcoin-qt and bitcoin-cli.
All command-line options (except for -?, -help, -version and -conf) may be specified in a configuration file, and all configuration file options (except for includeconf) may also be specified on the command line. Command-line options override values set in the configuration file and configuration file options override values set in the GUI.
Changes to the configuration file while bitcoind or bitcoin-qt is running only take effect after restarting.
Users should never make any configuration changes which they do not understand. Furthermore, users should always be wary of accepting any configuration changes provided to them by another source (even if they believe that they do understand them).
Configuration File Format
The configuration file is a plain text file and consists of option=value entries, one per line. Leading and trailing whitespaces are removed.
In contrast to the command-line usage:
- an option must be specified without leading
-; - a value of the given option is mandatory; e.g.,
testnet=1(for chain selection options),noconnect=1(for negated options).
Blank lines
Blank lines are allowed and ignored by the parser.
Comments
A comment starts with a number sign (#) and extends to the end of the line. All comments are ignored by the parser.
Comments may appear in two ways:
- on their own on an otherwise empty line (preferable);
- after an
option=valueentry.
Network specific options
Network specific options can be:
- placed into sections with headers
[main](not[mainnet]),[test](not[testnet], for testnet3),[testnet4],[signet]or[regtest]; - prefixed with a chain name; e.g.,
regtest.maxmempool=100.
Network specific options take precedence over non-network specific options. If multiple values for the same option are found with the same precedence, the first one is generally chosen.
This means that given the following configuration, regtest.rpcport is set to 3000:
regtest=1
rpcport=2000
regtest.rpcport=3000
[regtest]
rpcport=4000
Configuration File Path
The configuration file is not automatically created; you can create it using your favorite text editor. By default, the configuration file name is bitcoin.conf and it is located in the Bitcoin data directory, but both the Bitcoin data directory and the configuration file path may be changed using the -datadir and -conf command-line options.
The includeconf=<file> option in the bitcoin.conf file can be used to include additional configuration files.
Default configuration file locations
| Operating System | Data Directory | Example Path |
|---|---|---|
| Windows | %LOCALAPPDATA%\Bitcoin\ | C:\Users\username\AppData\Local\Bitcoin\bitcoin.conf |
| Linux | $HOME/.bitcoin/ | /home/username/.bitcoin/bitcoin.conf |
| macOS | $HOME/Library/Application Support/Bitcoin/ | /Users/username/Library/Application Support/Bitcoin/bitcoin.conf |
An example configuration file can be generated by contrib/devtools/gen-bitcoin-conf.sh.
Run this script after compiling to generate an up-to-date configuration file.
The output is placed under share/examples/bitcoin.conf.
To use the generated configuration file, copy the example file into your data directory and edit it there, like so:
# example copy command for linux user
cp share/examples/bitcoin.conf ~/.bitcoin
FreeBSD Build Guide
Updated for FreeBSD 14.0
This guide describes how to build bitcoind, command-line utilities, and GUI on FreeBSD.
Preparation
1. Install Required Dependencies
Run the following as root to install the base dependencies for building.
pkg install boost-libs cmake git libevent pkgconf
See dependencies.md for a complete overview.
2. Clone Bitcoin Repo
Now that git and all the required dependencies are installed, let's clone the Bitcoin Core repository to a directory. All build scripts and commands will run from this directory.
git clone https://github.com/bitcoin/bitcoin.git
3. Install Optional Dependencies
Wallet Dependencies
It is not necessary to build wallet functionality to run either bitcoind or bitcoin-qt.
Descriptor Wallet Support
sqlite3 is required to support descriptor wallets.
Skip if you don't intend to use descriptor wallets.
pkg install sqlite3
Legacy Wallet Support
BerkeleyDB is only required if legacy wallet support is required.
It is required to use Berkeley DB 4.8. You cannot use the BerkeleyDB library from ports. However, you can build DB 4.8 yourself using depends.
pkg install gmake
gmake -C depends NO_BOOST=1 NO_LIBEVENT=1 NO_QT=1 NO_SQLITE=1 NO_ZMQ=1 NO_USDT=1
When the build is complete, the Berkeley DB installation location will be displayed:
to: /path/to/bitcoin/depends/x86_64-unknown-freebsd[release-number]
Finally, set BDB_PREFIX to this path according to your shell:
csh: setenv BDB_PREFIX [path displayed above]
sh/bash: export BDB_PREFIX=[path displayed above]
GUI Dependencies
Qt5
Bitcoin Core includes a GUI built with the cross-platform Qt Framework. To compile the GUI, we need to install
the necessary parts of Qt, the libqrencode and pass -DBUILD_GUI=ON. Skip if you don't intend to use the GUI.
pkg install qt5-buildtools qt5-core qt5-gui qt5-linguisttools qt5-testlib qt5-widgets
libqrencode
The GUI will be able to encode addresses in QR codes unless this feature is explicitly disabled. To install libqrencode, run:
pkg install libqrencode
Otherwise, if you don't need QR encoding support, use the -DWITH_QRENCODE=OFF option to disable this feature in order to compile the GUI.
Notifications
ZeroMQ
Bitcoin Core can provide notifications via ZeroMQ. If the package is installed, support will be compiled in.
pkg install libzmq4
Test Suite Dependencies
There is an included test suite that is useful for testing code changes when developing. To run the test suite (recommended), you will need to have Python 3 installed:
pkg install python3 databases/py-sqlite3
Building Bitcoin Core
1. Configuration
There are many ways to configure Bitcoin Core, here are a few common examples:
Descriptor Wallet and GUI:
This disables legacy wallet support and enables the GUI, assuming sqlite and qt are installed.
cmake -B build -DWITH_BDB=OFF -DBUILD_GUI=ON
Run cmake -B build -LH to see the full list of available options.
Descriptor & Legacy Wallet. No GUI:
This enables support for both wallet types, assuming
sqlite3 and db4 are both installed.
cmake -B build -DBerkeleyDB_INCLUDE_DIR:PATH="${BDB_PREFIX}/include" -DWITH_BDB=ON
No Wallet or GUI
cmake -B build -DENABLE_WALLET=OFF
2. Compile
cmake --build build # Use "-j N" for N parallel jobs.
ctest --test-dir build # Use "-j N" for N parallel tests. Some tests are disabled if Python 3 is not available.
NetBSD Build Guide
Updated for NetBSD 10.0
This guide describes how to build bitcoind, command-line utilities, and GUI on NetBSD.
Preparation
1. Install Required Dependencies
Install the required dependencies the usual way you install software on NetBSD.
The example commands below use pkgin.
pkgin install git cmake pkg-config boost-headers libevent
NetBSD currently ships with an older version of gcc than is needed to build. You should upgrade your gcc and then pass this new version to the configure script.
For example, grab gcc12:
pkgin install gcc12
Then, when configuring, pass the following:
cmake -B build
...
-DCMAKE_C_COMPILER="/usr/pkg/gcc12/bin/gcc" \
-DCMAKE_CXX_COMPILER="/usr/pkg/gcc12/bin/g++" \
...
See dependencies.md for a complete overview.
2. Clone Bitcoin Repo
Clone the Bitcoin Core repository to a directory. All build scripts and commands will run from this directory.
git clone https://github.com/bitcoin/bitcoin.git
3. Install Optional Dependencies
Wallet Dependencies
It is not necessary to build wallet functionality to run bitcoind or the GUI.
Descriptor Wallet Support
sqlite3 is required to enable support for descriptor wallets.
pkgin install sqlite3
Legacy Wallet Support
db4 is required to enable support for legacy wallets.
pkgin install db4
GUI Dependencies
Qt5
Bitcoin Core includes a GUI built with the cross-platform Qt Framework. To compile the GUI, we need to install
the necessary parts of Qt, the libqrencode and pass -DBUILD_GUI=ON. Skip if you don't intend to use the GUI.
pkgin install qt5-qtbase qt5-qttools
libqrencode
The GUI will be able to encode addresses in QR codes unless this feature is explicitly disabled. To install libqrencode, run:
pkgin install qrencode
Otherwise, if you don't need QR encoding support, use the -DWITH_QRENCODE=OFF option to disable this feature in order to compile the GUI.
Test Suite Dependencies
There is an included test suite that is useful for testing code changes when developing. To run the test suite (recommended), you will need to have Python 3 installed:
pkgin install python39
Building Bitcoin Core
1. Configuration
There are many ways to configure Bitcoin Core. Here is an example that explicitly disables the wallet and GUI:
cmake -B build -DENABLE_WALLET=OFF -DBUILD_GUI=OFF
Run cmake -B build -LH to see the full list of available options.
2. Compile
Build and run the tests:
cmake --build build # Use "-j N" for N parallel jobs.
ctest --test-dir build # Use "-j N" for N parallel tests. Some tests are disabled if Python 3 is not available.
OpenBSD Build Guide
Updated for OpenBSD 7.5
This guide describes how to build bitcoind, command-line utilities, and GUI on OpenBSD.
Preparation
1. Install Required Dependencies
Run the following as root to install the base dependencies for building.
pkg_add git cmake boost libevent
See dependencies.md for a complete overview.
2. Clone Bitcoin Repo
Clone the Bitcoin Core repository to a directory. All build scripts and commands will run from this directory.
git clone https://github.com/bitcoin/bitcoin.git
3. Install Optional Dependencies
Wallet Dependencies
It is not necessary to build wallet functionality to run either bitcoind or bitcoin-qt.
Descriptor Wallet Support
SQLite is required to support descriptor wallets.
pkg_add sqlite3
Legacy Wallet Support
BerkeleyDB is only required to support legacy wallets.
It is recommended to use Berkeley DB 4.8. You cannot use the BerkeleyDB library from ports. However you can build it yourself, using depends.
Refer to depends/README.md for detailed instructions.
gmake -C depends NO_BOOST=1 NO_LIBEVENT=1 NO_QT=1 NO_SQLITE=1 NO_ZMQ=1 NO_USDT=1
...
to: /path/to/bitcoin/depends/*-unknown-openbsd*
Then set BDB_PREFIX:
export BDB_PREFIX="[path displayed above]"
GUI Dependencies
Qt5
Bitcoin Core includes a GUI built with the cross-platform Qt Framework. To compile the GUI, we need to install
the necessary parts of Qt, the libqrencode and pass -DBUILD_GUI=ON. Skip if you don't intend to use the GUI.
pkg_add qtbase qttools
libqrencode
The GUI will be able to encode addresses in QR codes unless this feature is explicitly disabled. To install libqrencode, run:
pkg_add libqrencode
Otherwise, if you don't need QR encoding support, use the -DWITH_QRENCODE=OFF option to disable this feature in order to compile the GUI.
Notifications
ZeroMQ
Bitcoin Core can provide notifications via ZeroMQ. If the package is installed, support will be compiled in.
pkg_add zeromq
Test Suite Dependencies
There is an included test suite that is useful for testing code changes when developing. To run the test suite (recommended), you will need to have Python 3 installed:
pkg_add python # Select the newest version of the package.
Building Bitcoin Core
1. Configuration
There are many ways to configure Bitcoin Core, here are a few common examples:
Descriptor Wallet and GUI:
This enables descriptor wallet support and the GUI, assuming SQLite and Qt 5 are installed.
cmake -B build -DWITH_SQLITE=ON -DBUILD_GUI=ON
Run cmake -B build -LH to see the full list of available options.
Descriptor & Legacy Wallet. No GUI:
This enables support for both wallet types:
cmake -B build -DBerkeleyDB_INCLUDE_DIR:PATH="${BDB_PREFIX}/include" -DWITH_BDB=ON
2. Compile
cmake --build build # Use "-j N" for N parallel jobs.
ctest --test-dir build # Use "-j N" for N parallel tests. Some tests are disabled if Python 3 is not available.
Resource limits
If the build runs into out-of-memory errors, the instructions in this section might help.
The standard ulimit restrictions in OpenBSD are very strict:
data(kbytes) 1572864
This is, unfortunately, in some cases not enough to compile some .cpp files in the project,
(see issue #6658).
If your user is in the staff group the limit can be raised with:
ulimit -d 3000000
The change will only affect the current shell and processes spawned by it. To
make the change system-wide, change datasize-cur and datasize-max in
/etc/login.conf, and reboot.
macOS Build Guide
Updated for MacOS 15
This guide describes how to build bitcoind, command-line utilities, and GUI on macOS.
Preparation
The commands in this guide should be executed in a Terminal application. macOS comes with a built-in Terminal located in:
/Applications/Utilities/Terminal.app
1. Xcode Command Line Tools
The Xcode Command Line Tools are a collection of build tools for macOS. These tools must be installed in order to build Bitcoin Core from source.
To install, run the following command from your terminal:
xcode-select --install
Upon running the command, you should see a popup appear.
Click on Install to continue the installation process.
2. Homebrew Package Manager
Homebrew is a package manager for macOS that allows one to install packages from the command line easily. While several package managers are available for macOS, this guide will focus on Homebrew as it is the most popular. Since the examples in this guide which walk through the installation of a package will use Homebrew, it is recommended that you install it to follow along. Otherwise, you can adapt the commands to your package manager of choice.
To install the Homebrew package manager, see: https://brew.sh
Note: If you run into issues while installing Homebrew or pulling packages, refer to Homebrew's troubleshooting page.
3. Install Required Dependencies
The first step is to download the required dependencies. These dependencies represent the packages required to get a barebones installation up and running.
See dependencies.md for a complete overview.
To install, run the following from your terminal:
brew install cmake boost pkg-config libevent
4. Clone Bitcoin repository
git should already be installed by default on your system.
Now that all the required dependencies are installed, let's clone the Bitcoin Core repository to a directory.
All build scripts and commands will run from this directory.
git clone https://github.com/bitcoin/bitcoin.git
5. Install Optional Dependencies
Wallet Dependencies
It is not necessary to build wallet functionality to run bitcoind or bitcoin-qt.
Descriptor Wallet Support
sqlite is required to support for descriptor wallets.
macOS ships with a useable sqlite package, meaning you don't need to
install anything.
Legacy Wallet Support
berkeley-db@4 is only required to support for legacy wallets.
Skip if you don't intend to use legacy wallets.
brew install berkeley-db@4
GUI Dependencies
Qt
Bitcoin Core includes a GUI built with the cross-platform Qt Framework. To compile the GUI, we need to install
Qt, libqrencode and pass -DBUILD_GUI=ON. Skip if you don't intend to use the GUI.
brew install qt@5
Note: Building with Qt binaries downloaded from the Qt website is not officially supported. See the notes in #7714.
libqrencode
The GUI will be able to encode addresses in QR codes unless this feature is explicitly disabled. To install libqrencode, run:
brew install qrencode
Otherwise, if you don't need QR encoding support, you can pass -DWITH_QRENCODE=OFF to disable this feature.
ZMQ Dependencies
Support for ZMQ notifications requires the following dependency. Skip if you do not need ZMQ functionality.
brew install zeromq
Check out the further configuration section for more information.
For more information on ZMQ, see: zmq.md
Test Suite Dependencies
There is an included test suite that is useful for testing code changes when developing. To run the test suite (recommended), you will need to have Python 3 installed:
brew install python
Deploy Dependencies
You can deploy a .zip containing the Bitcoin Core application.
It is required that you have python installed.
Building Bitcoin Core
1. Configuration
There are many ways to configure Bitcoin Core, here are a few common examples:
Wallet (BDB + SQlite) Support, No GUI:
If berkeley-db@4 or sqlite are not installed, this will throw an error.
cmake -B build -DWITH_BDB=ON
Wallet (only SQlite) and GUI Support:
This enables the GUI.
If sqlite or qt are not installed, this will throw an error.
cmake -B build -DBUILD_GUI=ON
No Wallet or GUI
cmake -B build -DENABLE_WALLET=OFF
Further Configuration
You may want to dig deeper into the configuration options to achieve your desired behavior. Examine the output of the following command for a full list of configuration options:
cmake -B build -LH
2. Compile
After configuration, you are ready to compile. Run the following in your terminal to compile Bitcoin Core:
cmake --build build # Use "-j N" here for N parallel jobs.
ctest --test-dir build # Use "-j N" for N parallel tests. Some tests are disabled if Python 3 is not available.
3. Deploy (optional)
You can also create a .zip containing the .app bundle by running the following command:
cmake --build build --target deploy
Running Bitcoin Core
Bitcoin Core should now be available at ./build/src/bitcoind.
If you compiled support for the GUI, it should be available at ./build/src/qt/bitcoin-qt.
The first time you run bitcoind or bitcoin-qt, it will start downloading the blockchain.
This process could take many hours, or even days on slower than average systems.
By default, blockchain and wallet data files will be stored in:
/Users/${USER}/Library/Application Support/Bitcoin/
Before running, you may create an empty configuration file:
mkdir -p "/Users/${USER}/Library/Application Support/Bitcoin"
touch "/Users/${USER}/Library/Application Support/Bitcoin/bitcoin.conf"
chmod 600 "/Users/${USER}/Library/Application Support/Bitcoin/bitcoin.conf"
You can monitor the download process by looking at the debug.log file:
tail -f $HOME/Library/Application\ Support/Bitcoin/debug.log
Other commands:
./build/src/bitcoind -daemon # Starts the bitcoin daemon.
./build/src/bitcoin-cli --help # Outputs a list of command-line options.
./build/src/bitcoin-cli help # Outputs a list of RPC commands when the daemon is running.
./build/src/qt/bitcoin-qt -server # Starts the bitcoin-qt server mode, allows bitcoin-cli control
UNIX BUILD NOTES
Some notes on how to build Bitcoin Core in Unix.
(For BSD specific instructions, see build-*bsd.md in this directory.)
To Build
cmake -B build
cmake --build build # use "-j N" for N parallel jobs
cmake --install build # optional
See below for instructions on how to install the dependencies on popular Linux distributions, or the dependencies section for a complete overview.
Memory Requirements
C++ compilers are memory-hungry. It is recommended to have at least 1.5 GB of
memory available when compiling Bitcoin Core. On systems with less, gcc can be
tuned to conserve memory with additional CMAKE_CXX_FLAGS:
cmake -B build -DCMAKE_CXX_FLAGS="--param ggc-min-expand=1 --param ggc-min-heapsize=32768"
Alternatively, or in addition, debugging information can be skipped for compilation.
For the default build type RelWithDebInfo, the default compile flags are
-O2 -g, and can be changed with:
cmake -B build -DCMAKE_CXX_FLAGS_RELWITHDEBINFO="-O2 -g0"
Finally, clang (often less resource hungry) can be used instead of gcc, which is used by default:
cmake -B build -DCMAKE_CXX_COMPILER=clang++ -DCMAKE_C_COMPILER=clang
Linux Distribution Specific Instructions
Ubuntu & Debian
Dependency Build Instructions
Build requirements:
sudo apt-get install build-essential cmake pkg-config python3
Now, you can either build from self-compiled depends or install the required dependencies:
sudo apt-get install libevent-dev libboost-dev
SQLite is required for the descriptor wallet:
sudo apt install libsqlite3-dev
Berkeley DB is only required for the legacy wallet. Ubuntu and Debian have their own libdb-dev and libdb++-dev packages,
but these will install Berkeley DB 5.3 or later. This will break binary wallet compatibility with the distributed
executables, which are based on BerkeleyDB 4.8. Otherwise, you can build Berkeley DB yourself.
To build Bitcoin Core without wallet, see Disable-wallet mode
ZMQ dependencies (provides ZMQ API):
sudo apt-get install libzmq3-dev
User-Space, Statically Defined Tracing (USDT) dependencies:
sudo apt install systemtap-sdt-dev
GUI dependencies:
Bitcoin Core includes a GUI built with the cross-platform Qt Framework. To compile the GUI, we need to install
the necessary parts of Qt, the libqrencode and pass -DBUILD_GUI=ON. Skip if you don't intend to use the GUI.
sudo apt-get install qtbase5-dev qttools5-dev qttools5-dev-tools
Additionally, to support Wayland protocol for modern desktop environments:
sudo apt install qtwayland5
The GUI will be able to encode addresses in QR codes unless this feature is explicitly disabled. To install libqrencode, run:
sudo apt-get install libqrencode-dev
Otherwise, if you don't need QR encoding support, use the -DWITH_QRENCODE=OFF option to disable this feature in order to compile the GUI.
Fedora
Dependency Build Instructions
Build requirements:
sudo dnf install gcc-c++ cmake make python3
Now, you can either build from self-compiled depends or install the required dependencies:
sudo dnf install libevent-devel boost-devel
SQLite is required for the descriptor wallet:
sudo dnf install sqlite-devel
Berkeley DB is only required for the legacy wallet. Fedora releases have only libdb-devel and libdb-cxx-devel packages, but these will install
Berkeley DB 5.3 or later. This will break binary wallet compatibility with the distributed executables, which
are based on Berkeley DB 4.8. Otherwise, you can build Berkeley DB yourself.
To build Bitcoin Core without wallet, see Disable-wallet mode
ZMQ dependencies (provides ZMQ API):
sudo dnf install zeromq-devel
User-Space, Statically Defined Tracing (USDT) dependencies:
sudo dnf install systemtap-sdt-devel
GUI dependencies:
Bitcoin Core includes a GUI built with the cross-platform Qt Framework. To compile the GUI, we need to install
the necessary parts of Qt, the libqrencode and pass -DBUILD_GUI=ON. Skip if you don't intend to use the GUI.
sudo dnf install qt5-qttools-devel qt5-qtbase-devel
Additionally, to support Wayland protocol for modern desktop environments:
sudo dnf install qt5-qtwayland
The GUI will be able to encode addresses in QR codes unless this feature is explicitly disabled. To install libqrencode, run:
sudo dnf install qrencode-devel
Otherwise, if you don't need QR encoding support, use the -DWITH_QRENCODE=OFF option to disable this feature in order to compile the GUI.
Dependencies
See dependencies.md for a complete overview, and depends on how to compile them yourself, if you wish to not use the packages of your Linux distribution.
Berkeley DB
The legacy wallet uses Berkeley DB. To ensure backwards compatibility it is recommended to use Berkeley DB 4.8. If you have to build it yourself, and don't want to use any other libraries built in depends, you can do:
make -C depends NO_BOOST=1 NO_LIBEVENT=1 NO_QT=1 NO_SQLITE=1 NO_ZMQ=1 NO_USDT=1
...
to: /path/to/bitcoin/depends/x86_64-pc-linux-gnu
and configure using the following:
export BDB_PREFIX="/path/to/bitcoin/depends/x86_64-pc-linux-gnu"
cmake -B build -DBerkeleyDB_INCLUDE_DIR:PATH="${BDB_PREFIX}/include" -DWITH_BDB=ON
Note: Make sure that BDB_PREFIX is an absolute path.
Note: You only need Berkeley DB if the legacy wallet is enabled (see Disable-wallet mode).
Disable-wallet mode
When the intention is to only run a P2P node, without a wallet, Bitcoin Core can be compiled in disable-wallet mode with:
cmake -B build -DENABLE_WALLET=OFF
In this case there is no dependency on SQLite or Berkeley DB.
Mining is also possible in disable-wallet mode using the getblocktemplate RPC call.
Additional Configure Flags
A list of additional configure flags can be displayed with:
cmake -B build -LH
Setup and Build Example: Arch Linux
This example lists the steps necessary to setup and build a command line only distribution of the latest changes on Arch Linux:
pacman --sync --needed cmake boost gcc git libevent make python sqlite
git clone https://github.com/bitcoin/bitcoin.git
cd bitcoin/
cmake -B build
cmake --build build
ctest --test-dir build
./build/src/bitcoind
If you intend to work with legacy Berkeley DB wallets, see Berkeley DB section.
Windows / MSVC Build Guide
This guide describes how to build bitcoind, command-line utilities, and GUI on Windows using Microsoft Visual Studio.
For cross-compiling options, please see build-windows.md.
Preparation
1. Visual Studio
This guide relies on using CMake and vcpkg package manager provided with the Visual Studio installation. Here are requirements for the Visual Studio installation:
- Minimum required version: Visual Studio 2022 version 17.6.
- Installed components:
- The "Desktop development with C++" workload.
The commands in this guide should be executed in "Developer PowerShell for VS 2022" or "Developer Command Prompt for VS 2022". The former is assumed hereinafter.
2. Git
Download and install Git for Windows. Once installed, Git is available from PowerShell or the Command Prompt.
3. Clone Bitcoin Repository
Clone the Bitcoin Core repository to a directory. All build scripts and commands will run from this directory.
git clone https://github.com/bitcoin/bitcoin.git
Triplets and Presets
The Bitcoin Core project supports the following vcpkg triplets:
x64-windows(both CRT and library linkage is dynamic)x64-windows-static(both CRT and library linkage is static)
To facilitate build process, the Bitcoin Core project provides presets, which are used in this guide.
Available presets can be listed as follows:
cmake --list-presets
By default, all presets set BUILD_GUI to ON.
Building
CMake will put the resulting object files, libraries, and executables into a dedicated build directory.
In the following instructions, the "Debug" configuration can be specified instead of the "Release" one.
4. Building with Static Linking with GUI
cmake -B build --preset vs2022-static # It might take a while if the vcpkg binary cache is unpopulated or invalidated.
cmake --build build --config Release # Use "-j N" for N parallel jobs.
ctest --test-dir build --build-config Release # Use "-j N" for N parallel tests. Some tests are disabled if Python 3 is not available.
cmake --install build --config Release # Optional.
5. Building with Dynamic Linking without GUI
cmake -B build --preset vs2022 -DBUILD_GUI=OFF # It might take a while if the vcpkg binary cache is unpopulated or invalidated.
cmake --build build --config Release # Use "-j N" for N parallel jobs.
ctest --test-dir build --build-config Release # Use "-j N" for N parallel tests. Some tests are disabled if Python 3 is not available.
Performance Notes
6. vcpkg Manifest Default Features
One can skip vcpkg manifest default features to speedup the configuration step. For example, the following invocation will skip all features except for "wallet" and "tests" and their dependencies:
cmake -B build --preset vs2022 -DVCPKG_MANIFEST_NO_DEFAULT_FEATURES=ON -DVCPKG_MANIFEST_FEATURES="wallet;tests" -DBUILD_GUI=OFF
Available features are listed in the vcpkg.json file.
7. Antivirus Software
To improve the build process performance, one might add the Bitcoin repository directory to the Microsoft Defender Antivirus exclusions.
WINDOWS BUILD NOTES
Below are some notes on how to build Bitcoin Core for Windows.
The options known to work for building Bitcoin Core on Windows are:
- On Linux, using the Mingw-w64 cross compiler tool chain.
- On Windows, using Windows Subsystem for Linux (WSL) and Mingw-w64.
- On Windows, using Microsoft Visual Studio. See
build-windows-msvc.md.
Other options which may work, but which have not been extensively tested are (please contribute instructions):
The instructions below work on Ubuntu and Debian. Make sure the distribution's g++-mingw-w64-x86-64-posix
package meets the minimum required g++ version specified in dependencies.md.
Installing Windows Subsystem for Linux
Follow the upstream installation instructions, available here.
Cross-compilation for Ubuntu and Windows Subsystem for Linux
The steps below can be performed on Ubuntu or WSL. The depends system will also work on other Linux distributions, however the commands for installing the toolchain will be different.
See README.md in the depends directory for which dependencies to install and dependencies.md for a complete overview.
If you want to build the Windows installer using the deploy build target, you will need NSIS:
apt install nsis
Acquire the source in the usual way:
git clone https://github.com/bitcoin/bitcoin.git
cd bitcoin
Note that for WSL the Bitcoin Core source path MUST be somewhere in the default mount file system, for example /usr/src/bitcoin, AND not under /mnt/d/. If this is not the case the dependency autoconf scripts will fail. This means you cannot use a directory that is located directly on the host Windows file system to perform the build.
Build using:
gmake -C depends HOST=x86_64-w64-mingw32 # Use "-j N" for N parallel jobs.
cmake -B build --toolchain depends/x86_64-w64-mingw32/toolchain.cmake
cmake --build build # Use "-j N" for N parallel jobs.
Depends system
For further documentation on the depends system see README.md in the depends directory.
Installation
After building using the Windows subsystem it can be useful to copy the compiled
executables to a directory on the Windows drive in the same directory structure
as they appear in the release .zip archive. This can be done in the following
way. This will install to c:\workspace\bitcoin, for example:
cmake --install build --prefix /mnt/c/workspace/bitcoin
You can also create an installer using:
cmake --build build --target deploy
CJDNS support in Bitcoin Core
It is possible to run Bitcoin Core over CJDNS, an encrypted IPv6 network that uses public-key cryptography for address allocation and a distributed hash table for routing.
What is CJDNS?
CJDNS is like a distributed, shared VPN with multiple entry points where every
participant can reach any other participant. All participants use addresses from
the fc00::/8 network (reserved IPv6 range). Installation and configuration is
done outside of Bitcoin Core, similarly to a VPN (either in the host/OS or on
the network router). See https://github.com/cjdelisle/cjdns#readme and
https://github.com/hyperboria/docs#hyperboriadocs for more information.
Compared to IPv4/IPv6, CJDNS provides end-to-end encryption and protects nodes from traffic analysis and filtering.
Used with Tor and I2P, CJDNS is a complementary option that can enhance network redundancy and robustness for both the Bitcoin network and individual nodes.
Each network has different characteristics. For instance, Tor is widely used but somewhat centralized. I2P connections have a source address and I2P is slow. CJDNS is fast but does not hide the sender and the recipient from intermediate routers.
Installing CJDNS and finding a peer to connect to the network
To install and set up CJDNS, follow the instructions at https://github.com/cjdelisle/cjdns#how-to-install-cjdns.
You need to initiate an outbound connection to a peer on the CJDNS network before it will work with your Bitcoin Core node. This is described in steps "2. Find a friend" and "3. Connect your node to your friend's node" in the CJDNS documentation.
One quick way to accomplish these two steps is to query for available public peers on Hyperboria by running the following:
git clone https://github.com/hyperboria/peers hyperboria-peers
cd hyperboria-peers
./testAvailable.py
For each peer, the ./testAvailable.py script prints the filename of the peer's
credentials followed by the ping result.
Choose one or several peers, copy their credentials from their respective files,
paste them into the relevant IPv4 or IPv6 "connectTo" JSON object in the
cjdroute.conf file you created in step "1. Generate a new configuration
file",
and save the file.
Launching CJDNS
Typically, CJDNS might be launched from its directory with
sudo ./cjdroute < cjdroute.conf and it sheds permissions after setting up the
TUN interface. You may also launch it as an
unprivileged user
with some additional setup.
The network connection can be checked by running ./tools/peerStats from the
CJDNS directory.
Run Bitcoin Core with CJDNS
Once you are connected to the CJDNS network, the following Bitcoin Core configuration option makes CJDNS peers automatically reachable:
-cjdnsreachable
When enabled, this option tells Bitcoin Core that it is running in an
environment where a connection to an fc00::/8 address will be to the CJDNS
network instead of to an RFC4193
IPv6 local network. This helps Bitcoin Core perform better address management:
- Your node can consider incoming
fc00::/8connections to be from the CJDNS network rather than from an IPv6 private one. - If one of your node's local addresses is
fc00::/8, then it can choose to gossip that address to peers.
Additional configuration options related to CJDNS
-onlynet=cjdns
Make automatic outbound connections only to CJDNS addresses. Inbound and manual connections are not affected by this option. It can be specified multiple times to allow multiple networks, e.g. onlynet=cjdns, onlynet=i2p, onlynet=onion.
CJDNS support was added to Bitcoin Core in version 23.0 and there may be fewer
CJDNS peers than Tor or IP ones. You can use bitcoin-cli -addrinfo to see the
number of CJDNS addresses known to your node.
In general, a node can be run with both an onion service and CJDNS (or any/all of IPv4/IPv6/onion/I2P/CJDNS), which can provide a potential fallback if one of the networks has issues. There are a number of ways to configure this; see doc/tor.md for details.
CJDNS-related information in Bitcoin Core
There are several ways to see your CJDNS address in Bitcoin Core:
- in the "Local addresses" output of CLI
-netinfo - in the "localaddresses" output of RPC
getnetworkinfo
To see which CJDNS peers your node is connected to, use bitcoin-cli -netinfo 4
or the getpeerinfo RPC (i.e. bitcoin-cli getpeerinfo).
You can use the getnodeaddresses RPC to fetch a number of CJDNS peers known to your node; run bitcoin-cli help getnodeaddresses for details.
Dependencies
These are the dependencies used by Bitcoin Core.
You can find installation instructions in the build-*.md file for your platform.
"Runtime" and "Version Used" are both in reference to the release binaries.
| Dependency | Minimum required |
|---|---|
| Clang | 16.0 |
| CMake | 3.22 |
| GCC | 11.1 |
| Python (scripts, tests) | 3.10 |
| systemtap (tracing) | N/A |
Required
| Dependency | Releases | Version used | Minimum required | Runtime |
|---|---|---|---|---|
| Boost | link | 1.81.0 | 1.73.0 | No |
| libevent | link | 2.1.12-stable | 2.1.8 | No |
| glibc | link | N/A | 2.31 | Yes |
| Linux Kernel | link | N/A | 3.17.0 | Yes |
Optional
GUI
| Dependency | Releases | Version used | Minimum required | Runtime |
|---|---|---|---|---|
| Fontconfig | link | 2.12.6 | 2.6 | Yes |
| FreeType | link | 2.11.0 | 2.3.0 | Yes |
| qrencode | link | 4.1.1 | No | |
| Qt | link | 5.15.14 | 5.11.3 | No |
Notifications
Wallet
| Dependency | Releases | Version used | Minimum required | Runtime |
|---|---|---|---|---|
| Berkeley DB (legacy wallet) | link | 4.8.30 | 4.8.x | No |
| SQLite | link | 3.38.5 | 3.7.17 | No |
Support for Output Descriptors in Bitcoin Core
Since Bitcoin Core v0.17, there is support for Output Descriptors. This is a simple language which can be used to describe collections of output scripts. Supporting RPCs are:
scantxoutsettakes as input descriptors to scan for, and also reports specialized descriptors for the matching UTXOs.getdescriptorinfoanalyzes a descriptor, and reports a canonicalized version with checksum added.deriveaddressestakes as input a descriptor and computes the corresponding addresses.listunspentoutputs a specialized descriptor for the reported unspent outputs.getaddressinfooutputs a descriptor for solvable addresses (since v0.18).importmultitakes as input descriptors to import into a legacy wallet (since v0.18).generatetodescriptortakes as input a descriptor and generates coins to it (regtestonly, since v0.19).utxoupdatepsbttakes as input descriptors to add information to the psbt (since v0.19).createmultisigandaddmultisigaddressreturn descriptors as well (since v0.20).importdescriptorstakes as input descriptors to import into a descriptor wallet (since v0.21).listdescriptorsoutputs descriptors imported into a descriptor wallet (since v22).scanblockstakes as input descriptors to scan for in blocks and returns the relevant blockhashes (since v25).
This document describes the language. For the specifics on usage, see the RPC documentation for the functions mentioned above.
Features
Output descriptors currently support:
- Pay-to-pubkey scripts (P2PK), through the
pkfunction. - Pay-to-pubkey-hash scripts (P2PKH), through the
pkhfunction. - Pay-to-witness-pubkey-hash scripts (P2WPKH), through the
wpkhfunction. - Pay-to-script-hash scripts (P2SH), through the
shfunction. - Pay-to-witness-script-hash scripts (P2WSH), through the
wshfunction. - Pay-to-taproot outputs (P2TR), through the
trfunction. - Multisig scripts, through the
multifunction. - Multisig scripts where the public keys are sorted lexicographically, through the
sortedmultifunction. - Multisig scripts inside taproot script trees, through the
multi_a(andsortedmulti_a) function. - Any type of supported address through the
addrfunction. - Raw hex scripts through the
rawfunction. - Public keys (compressed and uncompressed) in hex notation, or BIP32 extended pubkeys with derivation paths.
Examples
pk(0279be667ef9dcbbac55a06295ce870b07029bfcdb2dce28d959f2815b16f81798)describes a P2PK output with the specified public key.pkh(02c6047f9441ed7d6d3045406e95c07cd85c778e4b8cef3ca7abac09b95c709ee5)describes a P2PKH output with the specified public key.wpkh(02f9308a019258c31049344f85f89d5229b531c845836f99b08601f113bce036f9)describes a P2WPKH output with the specified public key.sh(wpkh(03fff97bd5755eeea420453a14355235d382f6472f8568a18b2f057a1460297556))describes a P2SH-P2WPKH output with the specified public key.combo(0279be667ef9dcbbac55a06295ce870b07029bfcdb2dce28d959f2815b16f81798)describes any P2PK, P2PKH, P2WPKH, or P2SH-P2WPKH output with the specified public key.sh(wsh(pkh(02e493dbf1c10d80f3581e4904930b1404cc6c13900ee0758474fa94abe8c4cd13)))describes an (overly complicated) P2SH-P2WSH-P2PKH output with the specified public key.multi(1,022f8bde4d1a07209355b4a7250a5c5128e88b84bddc619ab7cba8d569b240efe4,025cbdf0646e5db4eaa398f365f2ea7a0e3d419b7e0330e39ce92bddedcac4f9bc)describes a bare 1-of-2 multisig output with keys in the specified order.sh(multi(2,022f01e5e15cca351daff3843fb70f3c2f0a1bdd05e5af888a67784ef3e10a2a01,03acd484e2f0c7f65309ad178a9f559abde09796974c57e714c35f110dfc27ccbe))describes a P2SH 2-of-2 multisig output with keys in the specified order.sh(sortedmulti(2,03acd484e2f0c7f65309ad178a9f559abde09796974c57e714c35f110dfc27ccbe,022f01e5e15cca351daff3843fb70f3c2f0a1bdd05e5af888a67784ef3e10a2a01))describes a P2SH 2-of-2 multisig output with keys sorted lexicographically in the resulting redeemScript.wsh(multi(2,03a0434d9e47f3c86235477c7b1ae6ae5d3442d49b1943c2b752a68e2a47e247c7,03774ae7f858a9411e5ef4246b70c65aac5649980be5c17891bbec17895da008cb,03d01115d548e7561b15c38f004d734633687cf4419620095bc5b0f47070afe85a))describes a P2WSH 2-of-3 multisig output with keys in the specified order.sh(wsh(multi(1,03f28773c2d975288bc7d1d205c3748651b075fbc6610e58cddeeddf8f19405aa8,03499fdf9e895e719cfd64e67f07d38e3226aa7b63678949e6e49b241a60e823e4,02d7924d4f7d43ea965a465ae3095ff41131e5946f3c85f79e44adbcf8e27e080e)))describes a P2SH-P2WSH 1-of-3 multisig output with keys in the specified order.pk(xpub661MyMwAqRbcFtXgS5sYJABqqG9YLmC4Q1Rdap9gSE8NqtwybGhePY2gZ29ESFjqJoCu1Rupje8YtGqsefD265TMg7usUDFdp6W1EGMcet8)describes a P2PK output with the public key of the specified xpub.pkh(xpub68Gmy5EdvgibQVfPdqkBBCHxA5htiqg55crXYuXoQRKfDBFA1WEjWgP6LHhwBZeNK1VTsfTFUHCdrfp1bgwQ9xv5ski8PX9rL2dZXvgGDnw/1/2)describes a P2PKH output with child key 1/2 of the specified xpub.pkh([d34db33f/44'/0'/0']xpub6ERApfZwUNrhLCkDtcHTcxd75RbzS1ed54G1LkBUHQVHQKqhMkhgbmJbZRkrgZw4koxb5JaHWkY4ALHY2grBGRjaDMzQLcgJvLJuZZvRcEL/1/*)describes a set of P2PKH outputs, but additionally specifies that the specified xpub is a child of a master with fingerprintd34db33f, and derived using path44'/0'/0'.wsh(multi(1,xpub661MyMwAqRbcFW31YEwpkMuc5THy2PSt5bDMsktWQcFF8syAmRUapSCGu8ED9W6oDMSgv6Zz8idoc4a6mr8BDzTJY47LJhkJ8UB7WEGuduB/1/0/*,xpub69H7F5d8KSRgmmdJg2KhpAK8SR3DjMwAdkxj3ZuxV27CprR9LgpeyGmXUbC6wb7ERfvrnKZjXoUmmDznezpbZb7ap6r1D3tgFxHmwMkQTPH/0/0/*))describes a set of 1-of-2 P2WSH multisig outputs where the first multisig key is the 1/0/ichild of the first specified xpub and the second multisig key is the 0/0/ichild of the second specified xpub, andiis any number in a configurable range (0-1000by default).wsh(sortedmulti(1,xpub661MyMwAqRbcFW31YEwpkMuc5THy2PSt5bDMsktWQcFF8syAmRUapSCGu8ED9W6oDMSgv6Zz8idoc4a6mr8BDzTJY47LJhkJ8UB7WEGuduB/1/0/*,xpub69H7F5d8KSRgmmdJg2KhpAK8SR3DjMwAdkxj3ZuxV27CprR9LgpeyGmXUbC6wb7ERfvrnKZjXoUmmDznezpbZb7ap6r1D3tgFxHmwMkQTPH/0/0/*))describes a set of 1-of-2 P2WSH multisig outputs where one multisig key is the 1/0/ichild of the first specified xpub and the other multisig key is the 0/0/ichild of the second specified xpub, andiis any number in a configurable range (0-1000by default). The order of public keys in the resulting witnessScripts is determined by the lexicographic order of the public keys at that index.tr(c6047f9441ed7d6d3045406e95c07cd85c778e4b8cef3ca7abac09b95c709ee5,{pk(fff97bd5755eeea420453a14355235d382f6472f8568a18b2f057a1460297556),pk(e493dbf1c10d80f3581e4904930b1404cc6c13900ee0758474fa94abe8c4cd13)})describes a P2TR output with thec6...x-only pubkey as internal key, and two script paths.tr(c6047f9441ed7d6d3045406e95c07cd85c778e4b8cef3ca7abac09b95c709ee5,sortedmulti_a(2,2f8bde4d1a07209355b4a7250a5c5128e88b84bddc619ab7cba8d569b240efe4,5cbdf0646e5db4eaa398f365f2ea7a0e3d419b7e0330e39ce92bddedcac4f9bc))describes a P2TR output with thec6...x-only pubkey as internal key, and a singlemulti_ascript that needs 2 signatures with 2 specified x-only keys, which will be sorted lexicographically.wsh(sortedmulti(2,[6f53d49c/44h/1h/0h]tpubDDjsCRDQ9YzyaAq9rspCfq8RZFrWoBpYnLxK6sS2hS2yukqSczgcYiur8Scx4Hd5AZatxTuzMtJQJhchufv1FRFanLqUP7JHwusSSpfcEp2/0/*,[e6807791/44h/1h/0h]tpubDDAfvogaaAxaFJ6c15ht7Tq6ZmiqFYfrSmZsHu7tHXBgnjMZSHAeHSwhvjARNA6Qybon4ksPksjRbPDVp7yXA1KjTjSd5x18KHqbppnXP1s/0/*,[367c9cfa/44h/1h/0h]tpubDDtPnSgWYk8dDnaDwnof4ehcnjuL5VoUt1eW2MoAed1grPHuXPDnkX1fWMvXfcz3NqFxPbhqNZ3QBdYjLz2hABeM9Z2oqMR1Gt2HHYDoCgh/0/*))#av0kxgw0describes a 2-of-3 multisig. For brevity, the internal "change" descriptor accompanying the above external "receiving" descriptor is not included here, but it typically differs only in the xpub derivation steps, ending in/1/*for change addresses.
Reference
Descriptors consist of several types of expressions. The top level expression is either a SCRIPT, or SCRIPT#CHECKSUM where CHECKSUM is an 8-character alphanumeric descriptor checksum.
SCRIPT expressions:
sh(SCRIPT)(top level only): P2SH embed the argument.wsh(SCRIPT)(top level or insideshonly): P2WSH embed the argument.pk(KEY)(anywhere): P2PK output for the given public key.pkh(KEY)(not insidetr): P2PKH output for the given public key (useaddrif you only know the pubkey hash).wpkh(KEY)(top level or insideshonly): P2WPKH output for the given compressed pubkey.combo(KEY)(top level only): an alias for the collection ofpk(KEY)andpkh(KEY). If the key is compressed, it also includeswpkh(KEY)andsh(wpkh(KEY)).multi(k,KEY_1,KEY_2,...,KEY_n)(not insidetr): k-of-n multisig script using OP_CHECKMULTISIG.sortedmulti(k,KEY_1,KEY_2,...,KEY_n)(not insidetr): k-of-n multisig script with keys sorted lexicographically in the resulting script.multi_a(k,KEY_1,KEY_2,...,KEY_N)(only insidetr): k-of-n multisig script using OP_CHECKSIG, OP_CHECKSIGADD, and OP_NUMEQUAL.sortedmulti_a(k,KEY_1,KEY_2,...,KEY_N)(only insidetr): similar tomulti_a, but the (x-only) public keys in it will be sorted lexicographically.tr(KEY)ortr(KEY,TREE)(top level only): P2TR output with the specified key as internal key, and optionally a tree of script paths.addr(ADDR)(top level only): the script which ADDR expands to.raw(HEX)(top level only): the script whose hex encoding is HEX.rawtr(KEY)(top level only): P2TR output with the specified key as output key. NOTE: while it's possible to use this to construct wallets, it has several downsides, like being unable to prove no hidden script path exists. Use at your own risk.
KEY expressions:
- Optionally, key origin information, consisting of:
- An open bracket
[ - Exactly 8 hex characters for the fingerprint of the key where the derivation starts (see BIP32 for details)
- Followed by zero or more
/NUMor/NUM'path elements to indicate unhardened or hardened derivation steps between the fingerprint and the key or xpub/xprv root that follows - A closing bracket
]
- An open bracket
- Followed by the actual key, which is either:
- Hex encoded public keys (either 66 characters starting with
02or03for a compressed pubkey, or 130 characters starting with04for an uncompressed pubkey).- Inside
wpkhandwsh, only compressed public keys are permitted. - Inside
trandrawtr, x-only pubkeys are also permitted (64 hex characters).
- Inside
- WIF encoded private keys may be specified instead of the corresponding public key, with the same meaning.
xpubencoded extended public key orxprvencoded extended private key (as defined in BIP 32).- Followed by zero or more
/NUMunhardened and/NUM'hardened BIP32 derivation steps.- No more than one of these derivation steps may be of the form
<NUM;NUM;...;NUM>(including hardened indicators with either or bothNUM). If such specifiers are included, the descriptor will be parsed as multiple descriptors where the first descriptor uses all of the firstNUMin the pair, and the second descriptor uses the secondNUMin the pair for allKEYexpressions, and so on.
- No more than one of these derivation steps may be of the form
- Optionally followed by a single
/*or/*'final step to denote all (direct) unhardened or hardened children. - The usage of hardened derivation steps requires providing the private key.
- Followed by zero or more
- Hex encoded public keys (either 66 characters starting with
(Anywhere a ' suffix is permitted to denote hardened derivation, the suffix h can be used instead.)
TREE expressions:
- any
SCRIPTexpression - An open brace
{, aTREEexpression, a comma,, aTREEexpression, and a closing brace}
ADDR expressions are any type of supported address:
- P2PKH addresses (base58, of the form
1...for mainnet or[nm]...for testnet). Note that P2PKH addresses in descriptors cannot be used for P2PK outputs (use thepkfunction instead). - P2SH addresses (base58, of the form
3...for mainnet or2...for testnet, defined in BIP 13). - Segwit addresses (bech32 and bech32m, of the form
bc1...for mainnet ortb1...for testnet, defined in BIP 173 and BIP 350).
Explanation
Single-key scripts
Many single-key constructions are used in practice, generally including P2PK, P2PKH, P2WPKH, and P2SH-P2WPKH. Many more combinations are imaginable, though they may not be optimal: P2SH-P2PK, P2SH-P2PKH, P2WSH-P2PK, P2WSH-P2PKH, P2SH-P2WSH-P2PK, P2SH-P2WSH-P2PKH.
To describe these, we model these as functions. The functions pk
(P2PK), pkh (P2PKH) and wpkh (P2WPKH) take as input a KEY expression, and return the
corresponding scriptPubKey. The functions sh (P2SH) and wsh (P2WSH)
take as input a SCRIPT expression, and return the script describing P2SH and P2WSH
outputs with the input as embedded script. The names of the functions do
not contain "p2" for brevity.
Multisig
Several pieces of software use multi-signature (multisig) scripts based
on Bitcoin's OP_CHECKMULTISIG opcode. To support these, we introduce the
multi(k,key_1,key_2,...,key_n) and sortedmulti(k,key_1,key_2,...,key_n)
functions. They represent a k-of-n
multisig policy, where any k out of the n provided KEY expressions must
sign.
Key order is significant for multi(). A multi() expression describes a multisig script
with keys in the specified order, and in a search for TXOs, it will not match
outputs with multisig scriptPubKeys that have the same keys in a different
order. Also, to prevent a combinatorial explosion of the search space, if more
than one of the multi() key arguments is a BIP32 wildcard path ending in /*
or *', the multi() expression only matches multisig scripts with the ith
child key from each wildcard path in lockstep, rather than scripts with any
combination of child keys from each wildcard path.
Key order does not matter for sortedmulti(). sortedmulti() behaves in the same way
as multi() does but the keys are reordered in the resulting script such that they
are lexicographically ordered as described in BIP67.
Basic multisig example
For a good example of a basic M-of-N multisig between multiple participants using descriptor wallets and PSBTs, as well as a signing flow, see this functional test.
Disclaimers: It is important to note that this example serves as a quick-start and is kept basic for readability. A downside of the approach outlined here is that each participant must maintain (and backup) two separate wallets: a signer and the corresponding multisig. It should also be noted that privacy best-practices are not "by default" here - participants should take care to only use the signer to sign transactions related to the multisig. Lastly, it is not recommended to use anything other than a Bitcoin Core descriptor wallet to serve as your signer(s). Other wallets, whether hardware or software, likely impose additional checks and safeguards to prevent users from signing transactions that could lead to loss of funds, or are deemed security hazards. Conforming to various 3rd-party checks and verifications is not in the scope of this example.
The basic steps are:
- Every participant generates an xpub. The most straightforward way is to create a new descriptor wallet which we will refer to as
the participant's signer wallet. Avoid reusing this wallet for any purpose other than signing transactions from the
corresponding multisig we are about to create. Hint: extract the wallet's xpubs using
listdescriptorsand pick the one from thepkhdescriptor since it's least likely to be accidentally reused (legacy addresses) - Create a watch-only descriptor wallet (blank, private keys disabled). Now the multisig is created by importing the external and internal descriptors:
wsh(sortedmulti(<M>,XPUB1/0/*,XPUB2/0/*,…,XPUBN/0/*))andwsh(sortedmulti(<M>,XPUB1/1/*,XPUB2/1/*,…,XPUBN/1/*))(one descriptor w/0for receiving addresses and another w/1for change). Every participant does this. All key origin information (master key fingerprint and all derivation steps) should be included with xpubs for proper support of hardware devices / external signers - A receiving address is generated for the multisig. As a check to ensure step 2 was done correctly, every participant should verify they get the same addresses
- Funds are sent to the resulting address
- A sending transaction from the multisig is created using
walletcreatefundedpsbt(anyone can initiate this). It is simple to do this in the GUI by going to theSendtab in the multisig wallet and creating an unsigned transaction (PSBT) - At least
Mparticipants check the PSBT with their multisig usingdecodepsbtto verify the transaction is OK before signing it. - (If OK) the participant signs the PSBT with their signer wallet using
walletprocesspsbt. It is simple to do this in the GUI by loading the PSBT from file and signing it - The signed PSBTs are collected with
combinepsbt, finalized w/finalizepsbt, and then the resulting transaction is broadcasted to the network. Note that any wallet (eg one of the signers or multisig) is capable of doing this. - Checks that balances are correct after the transaction has been included in a block
You may prefer a daisy chained signing flow where each participant signs the PSBT one after another until
the PSBT has been signed M times and is "complete." For the most part, the steps above remain the same, except (6, 7)
change slightly from signing the original PSBT in parallel to signing it in series. combinepsbt is not necessary with
this signing flow and the last (mth) signer can just broadcast the PSBT after signing. Note that a parallel signing flow may be
preferable in cases where there are more signers. This signing flow is also included in the test / Python example.
The test is meant to be documentation as much as it is a functional test, so
it is kept as simple and readable as possible.
BIP32 derived keys and chains
Most modern wallet software and hardware uses keys that are derived using
BIP32 ("HD keys"). We support these directly by permitting strings
consisting of an extended public key (commonly referred to as an xpub)
plus derivation path anywhere a public key is expected. The derivation
path consists of a sequence of 0 or more integers (in the range
0..231-1) each optionally followed by ' or h, and
separated by / characters. The string may optionally end with the
literal /* or /*' (or /*h) to refer to all unhardened or hardened
child keys in a configurable range (by default 0-1000, inclusive).
Whenever a public key is described using a hardened derivation step, the script cannot be computed without access to the corresponding private key.
Key origin identification
In order to describe scripts whose signing keys reside on another device, it may be necessary to identify the master key and derivation path an xpub was derived with.
For example, when following BIP44, it would be useful to describe a
change chain directly as xpub.../44'/0'/0'/1/* where xpub...
corresponds with the master key m. Unfortunately, since there are
hardened derivation steps that follow the xpub, this descriptor does not
let you compute scripts without access to the corresponding private keys.
Instead, it should be written as xpub.../1/*, where xpub corresponds to
m/44'/0'/0'.
When interacting with a hardware device, it may be necessary to include the entire path from the master down. BIP174 standardizes this by providing the master key fingerprint (first 32 bit of the Hash160 of the master pubkey), plus all derivation steps. To support constructing these, we permit providing this key origin information inside the descriptor language, even though it does not affect the actual scriptPubKeys it refers to.
Every public key can be prefixed by an 8-character hexadecimal fingerprint plus optional derivation steps (hardened and unhardened) surrounded by brackets, identifying the master and derivation path the key or xpub that follows was derived with.
Note that the fingerprint of the parent only serves as a fast way to detect parent and child nodes in software, and software must be willing to deal with collisions.
Including private keys
Often it is useful to communicate a description of scripts along with the necessary private keys. For this reason, anywhere a public key or xpub is supported, a private key in WIF format or xprv may be provided instead. This is useful when private keys are necessary for hardened derivation steps, for signing transactions, or for dumping wallet descriptors including private key material.
For example, after importing the following 2-of-3 multisig descriptor
into a wallet, one could use signrawtransactionwithwallet
to sign a transaction with the first key:
sh(multi(2,xprv.../84'/0'/0'/0/0,xpub1...,xpub2...))
Note how the first key is an xprv private key with a specific derivation path, while the other two are public keys.
Specifying receiving and change descriptors in one descriptor
Since receiving and change addresses are frequently derived from the same extended key(s) but with a single derivation index changed, it is convenient to be able to specify a descriptor that can derive at the two different indexes. Thus a single tuple of indexes is allowed in each derivation path following the extended key. When this descriptor is parsed, multiple descriptors will be produced, the first one will use the first index in the tuple for all key expressions, the second will use the second index, the third will use the third index, and so on..
For example, a descriptor of the form:
multi(2,xpub.../<0;1;2>/0/*,xpub.../<2;3;4>/*)
will expand to the two descriptors
multi(2,xpub.../0/0/,xpub.../2/) multi(2,xpub.../1/0/,xpub.../3/) multi(2,xpub.../2/0/,xpub.../4)
When this tuple contains only two elements, wallet implementations can use the first descriptor for receiving addresses and the second descriptor for change addresses.
Compatibility with old wallets
In order to easily represent the sets of scripts currently supported by
existing Bitcoin Core wallets, a convenience function combo is
provided, which takes as input a public key, and describes a set of P2PK,
P2PKH, P2WPKH, and P2SH-P2WPKH scripts for that key. In case the key is
uncompressed, the set only includes P2PK and P2PKH scripts.
Checksums
Descriptors can optionally be suffixed with a checksum to protect against typos or copy-paste errors.
These checksums consist of 8 alphanumeric characters. As long as errors are
restricted to substituting characters in 0123456789()[],'/*abcdefgh@:$%{}
for others in that set and changes in letter case, up to 4 errors will always
be detected in descriptors up to 501 characters, and up to 3 errors in longer
ones. For larger numbers of errors, or other types of errors, there is a
roughly 1 in a trillion chance of not detecting the errors.
All RPCs in Bitcoin Core will include the checksum in their output. Only
certain RPCs require checksums on input, including deriveaddresses and
importmulti. The checksum for a descriptor without one can be computed
using the getdescriptorinfo RPC.
Developer Notes
Table of Contents
- Developer Notes
- Development guidelines
Coding Style (General)
Various coding styles have been used during the history of the codebase, and the result is not very consistent. However, we're now trying to converge to a single style, which is specified below. When writing patches, favor the new style over attempting to mimic the surrounding style, except for move-only commits.
Do not submit patches solely to modify the style of existing code.
Coding Style (C++)
-
Indentation and whitespace rules as specified in src/.clang-format. You can use the provided clang-format-diff script tool to clean up patches automatically before submission.
- Braces on new lines for classes, functions, methods.
- Braces on the same line for everything else.
- 4 space indentation (no tabs) for every block except namespaces.
- No indentation for
public/protected/privateor fornamespace. - No extra spaces inside parenthesis; don't do
( this ). - No space after function names; one space after
if,forandwhile. - If an
ifonly has a single-statementthen-clause, it can appear on the same line as theif, without braces. In every other case, braces are required, and thethenandelseclauses must appear correctly indented on a new line. - There's no hard limit on line width, but prefer to keep lines to <100 characters if doing so does not decrease readability. Break up long function declarations over multiple lines using the Clang Format AlignAfterOpenBracket style option.
-
Symbol naming conventions. These are preferred in new code, but are not required when doing so would need changes to significant pieces of existing code.
-
Variable (including function arguments) and namespace names are all lowercase and may use
_to separate words (snake_case).- Class member variables have a
m_prefix. - Global variables have a
g_prefix.
- Class member variables have a
-
Constant names are all uppercase, and use
_to separate words. -
Enumerator constants may be
snake_case,PascalCaseorALL_CAPS. This is a more tolerant policy than the C++ Core Guidelines, which recommend usingsnake_case. Please use what seems appropriate. -
Class names, function names, and method names are UpperCamelCase (PascalCase). Do not prefix class names with
C. See Internal interface naming style for an exception to this convention. -
Test suite naming convention: The Boost test suite in file
src/test/foo_tests.cppshould be namedfoo_tests. Test suite names must be unique.
-
-
Miscellaneous
++iis preferred overi++.nullptris preferred overNULLor(void*)0.static_assertis preferred overassertwhere possible. Generally; compile-time checking is preferred over run-time checking.- Use a named cast or functional cast, not a C-Style cast. When casting
between integer types, use functional casts such as
int(x)orint{x}instead of(int) x. When casting between more complex types, usestatic_cast. Usereinterpret_castandconst_castas appropriate. - Prefer
list initialization ({})where possible. For exampleint x{0};instead ofint x = 0;orint x(0); - Recursion is checked by clang-tidy and thus must be made explicit. Use
NOLINTNEXTLINE(misc-no-recursion)to suppress the check.
For function calls a namespace should be specified explicitly, unless such functions have been declared within it. Otherwise, argument-dependent lookup, also known as ADL, could be triggered that makes code harder to maintain and reason about:
#include <filesystem>
namespace fs {
class path : public std::filesystem::path
{
};
// The intention is to disallow this function.
bool exists(const fs::path& p) = delete;
} // namespace fs
int main()
{
//fs::path p; // error
std::filesystem::path p; // compiled
exists(p); // ADL being used for unqualified name lookup
}
Block style example:
int g_count{0};
namespace foo {
class Class
{
std::string m_name;
public:
bool Function(const std::string& s, int n)
{
// Comment summarising what this section of code does
for (int i = 0; i < n; ++i) {
int total_sum{0};
// When something fails, return early
if (!Something()) return false;
...
if (SomethingElse(i)) {
total_sum += ComputeSomething(g_count);
} else {
DoSomething(m_name, total_sum);
}
}
// Success return is usually at the end
return true;
}
}
} // namespace foo
Coding Style (C++ functions and methods)
-
When ordering function parameters, place input parameters first, then any in-out parameters, followed by any output parameters.
-
Rationale: API consistency.
-
Prefer returning values directly to using in-out or output parameters. Use
std::optionalwhere helpful for returning values. -
Rationale: Less error-prone (no need for assumptions about what the output is initialized to on failure), easier to read, and often the same or better performance.
-
Generally, use
std::optionalto represent optional by-value inputs (and instead of a magic default value, if there is no real default). Non-optional input parameters should usually be values or const references, while non-optional in-out and output parameters should usually be references, as they cannot be null.
Coding Style (C++ named arguments)
When passing named arguments, use a format that clang-tidy understands. The argument names can otherwise not be verified by clang-tidy.
For example:
void function(Addrman& addrman, bool clear);
int main()
{
function(g_addrman, /*clear=*/false);
}
Running clang-tidy
To run clang-tidy on Ubuntu/Debian, install the dependencies:
apt install clang-tidy clang
Configure with clang as the compiler:
cmake -B build -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DCMAKE_EXPORT_COMPILE_COMMANDS=ON
cmake --build build -j $(nproc)
The output is denoised of errors from external dependencies.
To run clang-tidy on all source files:
( cd ./src/ && run-clang-tidy -p ../build -j $(nproc) )
To run clang-tidy on the changed source lines:
git diff | ( cd ./src/ && clang-tidy-diff -p2 -path ../build -j $(nproc) )
Coding Style (Python)
Refer to /test/functional/README.md#style-guidelines.
Coding Style (Doxygen-compatible comments)
Bitcoin Core uses Doxygen to generate its official documentation.
Use Doxygen-compatible comment blocks for functions, methods, and fields.
For example, to describe a function use:
/**
* ... Description ...
*
* @param[in] arg1 input description...
* @param[in] arg2 input description...
* @param[out] arg3 output description...
* @return Return cases...
* @throws Error type and cases...
* @pre Pre-condition for function...
* @post Post-condition for function...
*/
bool function(int arg1, const char *arg2, std::string& arg3)
A complete list of @xxx commands can be found at https://www.doxygen.nl/manual/commands.html.
As Doxygen recognizes the comments by the delimiters (/** and */ in this case), you don't
need to provide any commands for a comment to be valid; just a description text is fine.
To describe a class, use the same construct above the class definition:
/**
* Alerts are for notifying old versions if they become too obsolete and
* need to upgrade. The message is displayed in the status bar.
* @see GetWarnings()
*/
class CAlert
To describe a member or variable use:
//! Description before the member
int var;
or
int var; //!< Description after the member
Also OK:
///
/// ... Description ...
///
bool function2(int arg1, const char *arg2)
Not picked up by Doxygen:
//
// ... Description ...
//
Also not picked up by Doxygen:
/*
* ... Description ...
*/
A full list of comment syntaxes picked up by Doxygen can be found at https://www.doxygen.nl/manual/docblocks.html, but the above styles are favored.
Recommendations:
-
Avoiding duplicating type and input/output information in function descriptions.
-
Use backticks (``) to refer to
argumentnames in function and parameter descriptions. -
Backticks aren't required when referring to functions Doxygen already knows about; it will build hyperlinks for these automatically. See https://www.doxygen.nl/manual/autolink.html for complete info.
-
Avoid linking to external documentation; links can break.
-
Javadoc and all valid Doxygen comments are stripped from Doxygen source code previews (
STRIP_CODE_COMMENTS = YESin Doxyfile.in). If you want a comment to be preserved, it must instead use//or/* */.
Generating Documentation
Assuming the build directory is named build,
the documentation can be generated with cmake --build build --target docs.
The resulting files will be located in build/doc/doxygen/html;
open index.html in that directory to view the homepage.
Before building the docs target, you'll need to install these dependencies:
Linux: sudo apt install doxygen graphviz
MacOS: brew install doxygen graphviz
Development tips and tricks
Compiling for debugging
When using the default build configuration by running cmake -B build, the
-DCMAKE_BUILD_TYPE is set to RelWithDebInfo. This option adds debug symbols
but also performs some compiler optimizations that may make debugging trickier
as the code may not correspond directly to the source.
If you need to build exclusively for debugging, set the -DCMAKE_BUILD_TYPE
to Debug (i.e. -DCMAKE_BUILD_TYPE=Debug). You can always check the cmake
build options of an existing build with ccmake build.
Show sources in debugging
If you have ccache enabled, absolute paths are stripped from debug information
with the -fdebug-prefix-map and -fmacro-prefix-map options (if supported by the
compiler). This might break source file detection in case you move binaries
after compilation, debug from the directory other than the project root or use
an IDE that only supports absolute paths for debugging (e.g. it won't stop at breakpoints).
There are a few possible fixes:
- Configure source file mapping.
For gdb create or append to .gdbinit file:
set substitute-path ./src /path/to/project/root/src
For lldb create or append to .lldbinit file:
settings set target.source-map ./src /path/to/project/root/src
- Add a symlink to the
./srcdirectory:
ln -s /path/to/project/root/src src
-
Use
debugeditto modify debug information in the binary. -
If your IDE has an option for this, change your breakpoints to use the file name only.
debug.log
If the code is behaving strangely, take a look in the debug.log file in the data directory;
error and debugging messages are written there.
Debug logging can be enabled on startup with the -debug and -loglevel
configuration options and toggled while bitcoind is running with the logging
RPC. For instance, launching bitcoind with -debug or -debug=1 will turn on
all log categories and -loglevel=trace will turn on all log severity levels.
The Qt code routes qDebug() output to debug.log under category "qt": run with -debug=qt
to see it.
Signet, testnet, and regtest modes
If you are testing multi-machine code that needs to operate across the internet,
you can run with either the -signet or the -testnet config option to test
with "play bitcoins" on a test network.
If you are testing something that can run on one machine, run with the
-regtest option. In regression test mode, blocks can be created on demand;
see test/functional/ for tests that run in -regtest mode.
DEBUG_LOCKORDER
Bitcoin Core is a multi-threaded application, and deadlocks or other
multi-threading bugs can be very difficult to track down. The -DCMAKE_BUILD_TYPE=Debug
build option adds -DDEBUG_LOCKORDER to the compiler flags. This inserts
run-time checks to keep track of which locks are held and adds warnings to the
debug.log file if inconsistencies are detected.
DEBUG_LOCKCONTENTION
Defining DEBUG_LOCKCONTENTION adds a "lock" logging category to the logging
RPC that, when enabled, logs the location and duration of each lock contention
to the debug.log file.
The -DCMAKE_BUILD_TYPE=Debug build option adds -DDEBUG_LOCKCONTENTION to the
compiler flags. You may also enable it manually by building with -DDEBUG_LOCKCONTENTION added to your CPPFLAGS,
i.e. CPPFLAGS="-DDEBUG_LOCKCONTENTION", then build and run bitcoind.
You can then use the -debug=lock configuration option at bitcoind startup or
bitcoin-cli logging '["lock"]' at runtime to turn on lock contention logging.
It can be toggled off again with bitcoin-cli logging [] '["lock"]'.
Assertions and Checks
The util file src/util/check.h offers helpers to protect against coding and
internal logic bugs. They must never be used to validate user, network or any
other input.
assertorAssertshould be used to document assumptions when any violation would mean that it is not safe to continue program execution. The code is always compiled with assertions enabled.- For example, a nullptr dereference or any other logic bug in validation code means the program code is faulty and must terminate immediately.
CHECK_NONFATALshould be used for recoverable internal logic bugs. On failure, it will throw an exception, which can be caught to recover from the error.- For example, a nullptr dereference or any other logic bug in RPC code means that the RPC code is faulty and cannot be executed. However, the logic bug can be shown to the user and the program can continue to run.
Assumeshould be used to document assumptions when program execution can safely continue even if the assumption is violated. In debug builds it behaves likeAssert/assertto notify developers and testers about nonfatal errors. In production it doesn't warn or log anything, though the expression is always evaluated.- For example it can be assumed that a variable is only initialized once, but a failed assumption does not result in a fatal bug. A failed assumption may or may not result in a slightly degraded user experience, but it is safe to continue program execution.
Valgrind suppressions file
Valgrind is a programming tool for memory debugging, memory leak detection, and
profiling. The repo contains a Valgrind suppressions file
(valgrind.supp)
which includes known Valgrind warnings in our dependencies that cannot be fixed
in-tree. Example use:
$ valgrind --suppressions=contrib/valgrind.supp build/src/test/test_bitcoin
$ valgrind --suppressions=contrib/valgrind.supp --leak-check=full \
--show-leak-kinds=all build/src/test/test_bitcoin --log_level=test_suite
$ valgrind -v --leak-check=full build/src/bitcoind -printtoconsole
$ ./build/test/functional/test_runner.py --valgrind
Compiling for test coverage
LCOV can be used to generate a test coverage report based upon ctest
execution. LCOV must be installed on your system (e.g. the lcov package
on Debian/Ubuntu).
To enable LCOV report generation during test runs:
cmake -B build -DCMAKE_BUILD_TYPE=Coverage
cmake --build build
cmake -P build/Coverage.cmake
# A coverage report will now be accessible at `./build/test_bitcoin.coverage/index.html`,
# which covers unit tests, and `./build/total.coverage/index.html`, which covers
# unit and functional tests.
Additional LCOV options can be specified using LCOV_OPTS, but may be dependent
on the version of LCOV. For example, when using LCOV 2.x, branch coverage can be
enabled by setting LCOV_OPTS="--rc branch_coverage=1":
cmake -DLCOV_OPTS="--rc branch_coverage=1" -P build/Coverage.cmake
To enable test parallelism:
cmake -DJOBS=$(nproc) -P build/Coverage.cmake
Performance profiling with perf
Profiling is a good way to get a precise idea of where time is being spent in
code. One tool for doing profiling on Linux platforms is called
perf, and has been integrated into
the functional test framework. Perf can observe a running process and sample
(at some frequency) where its execution is.
Perf installation is contingent on which kernel version you're running; see this thread for specific instructions.
Certain kernel parameters may need to be set for perf to be able to inspect the running process's stack.
$ sudo sysctl -w kernel.perf_event_paranoid=-1
$ sudo sysctl -w kernel.kptr_restrict=0
Make sure you understand the security trade-offs of setting these kernel parameters.
To profile a running bitcoind process for 60 seconds, you could use an
invocation of perf record like this:
$ perf record \
-g --call-graph dwarf --per-thread -F 140 \
-p `pgrep bitcoind` -- sleep 60
You could then analyze the results by running:
perf report --stdio | c++filt | less
or using a graphical tool like Hotspot.
See the functional test documentation for how to invoke perf within tests.
Sanitizers
Bitcoin Core can be compiled with various "sanitizers" enabled, which add
instrumentation for issues regarding things like memory safety, thread race
conditions, or undefined behavior. This is controlled with the
-DSANITIZERS cmake build flag, which should be a comma separated list of
sanitizers to enable. The sanitizer list should correspond to supported
-fsanitize= options in your compiler. These sanitizers have runtime overhead,
so they are most useful when testing changes or producing debugging builds.
Some examples:
# Enable both the address sanitizer and the undefined behavior sanitizer
cmake -B build -DSANITIZERS=address,undefined
# Enable the thread sanitizer
cmake -B build -DSANITIZERS=thread
If you are compiling with GCC you will typically need to install corresponding "san" libraries to actually compile with these flags, e.g. libasan for the address sanitizer, libtsan for the thread sanitizer, and libubsan for the undefined sanitizer. If you are missing required libraries, the build will fail with a linker error when testing the sanitizer flags.
The test suite should pass cleanly with the thread and undefined sanitizers. You
may need to use a suppressions file, see test/sanitizer_suppressions. They may be
used as follows:
export LSAN_OPTIONS="suppressions=$(pwd)/test/sanitizer_suppressions/lsan"
export TSAN_OPTIONS="suppressions=$(pwd)/test/sanitizer_suppressions/tsan:halt_on_error=1:second_deadlock_stack=1"
export UBSAN_OPTIONS="suppressions=$(pwd)/test/sanitizer_suppressions/ubsan:print_stacktrace=1:halt_on_error=1:report_error_type=1"
See the CI config for more examples, and upstream documentation for more information about any additional options.
Not all sanitizer options can be enabled at the same time, e.g. trying to build
with -DSANITIZERS=address,thread will fail in the build as
these sanitizers are mutually incompatible. Refer to your compiler manual to
learn more about these options and which sanitizers are supported by your
compiler.
Additional resources:
- AddressSanitizer
- LeakSanitizer
- MemorySanitizer
- ThreadSanitizer
- UndefinedBehaviorSanitizer
- GCC Instrumentation Options
- Google Sanitizers Wiki
Locking/mutex usage notes
The code is multi-threaded and uses mutexes and the
LOCK and TRY_LOCK macros to protect data structures.
Deadlocks due to inconsistent lock ordering (thread 1 locks cs_main and then
cs_wallet, while thread 2 locks them in the opposite order: result, deadlock
as each waits for the other to release its lock) are a problem. Compile with
-DDEBUG_LOCKORDER (or use -DCMAKE_BUILD_TYPE=Debug) to get lock order inconsistencies
reported in the debug.log file.
Re-architecting the core code so there are better-defined interfaces
between the various components is a goal, with any necessary locking
done by the components (e.g. see the self-contained FillableSigningProvider class
and its cs_KeyStore lock for example).
Threads
-
Main thread (
bitcoind) : Started frommain()inbitcoind.cpp. Responsible for starting up and shutting down the application. -
Init load (
b-initload) : Performs various loading tasks that are part of init but shouldn't block the node from being started: external block import, reindex, reindex-chainstate, main chain activation, spawn indexes background sync threads and mempool load. -
CCheckQueue::Loop (
b-scriptch.x) : Parallel script validation threads for transactions in blocks. -
ThreadHTTP (
b-http) : Libevent thread to listen for RPC and REST connections. -
HTTP worker threads(
b-httpworker.x) : Threads to service RPC and REST requests. -
Indexer threads (
b-txindex, etc) : One thread per indexer. -
SchedulerThread (
b-scheduler) : Does asynchronous background tasks like dumping wallet contents, dumping addrman and running asynchronous validationinterface callbacks. -
TorControlThread (
b-torcontrol) : Libevent thread for tor connections. -
Net threads:
-
ThreadMessageHandler (
b-msghand) : Application level message handling (sending and receiving). Almost all net_processing and validation logic runs on this thread. -
ThreadDNSAddressSeed (
b-dnsseed) : Loads addresses of peers from the DNS. -
ThreadMapPort (
b-mapport) : Universal plug-and-play startup/shutdown. -
ThreadSocketHandler (
b-net) : Sends/Receives data from peers on port 8333. -
ThreadOpenAddedConnections (
b-addcon) : Opens network connections to added nodes. -
ThreadOpenConnections (
b-opencon) : Initiates new connections to peers. -
ThreadI2PAcceptIncoming (
b-i2paccept) : Listens for and accepts incoming I2P connections through the I2P SAM proxy.
-
Ignoring IDE/editor files
In closed-source environments in which everyone uses the same IDE, it is common
to add temporary files it produces to the project-wide .gitignore file.
However, in open source software such as Bitcoin Core, where everyone uses
their own editors/IDE/tools, it is less common. Only you know what files your
editor produces and this may change from version to version. The canonical way
to do this is thus to create your local gitignore. Add this to ~/.gitconfig:
[core]
excludesfile = /home/.../.gitignore_global
(alternatively, type the command git config --global core.excludesfile ~/.gitignore_global
on a terminal)
Then put your favourite tool's temporary filenames in that file, e.g.
# NetBeans
nbproject/
Another option is to create a per-repository excludes file .git/info/exclude.
These are not committed but apply only to one repository.
If a set of tools is used by the build system or scripts the repository (for
example, lcov) it is perfectly acceptable to add its files to .gitignore
and commit them.
Development guidelines
A few non-style-related recommendations for developers, as well as points to pay attention to for reviewers of Bitcoin Core code.
General Bitcoin Core
-
New features should be exposed on RPC first, then can be made available in the GUI.
- Rationale: RPC allows for better automatic testing. The test suite for the GUI is very limited.
-
Make sure pull requests pass CI before merging.
-
Rationale: Makes sure that they pass thorough testing, and that the tester will keep passing on the master branch. Otherwise, all new pull requests will start failing the tests, resulting in confusion and mayhem.
-
Explanation: If the test suite is to be updated for a change, this has to be done first.
-
Logging
The macros LogInfo, LogDebug, LogTrace, LogWarning and LogError are available for
logging messages. They should be used as follows:
-
LogDebug(BCLog::CATEGORY, fmt, params...)is what you want most of the time, and it should be used for log messages that are useful for debugging and can reasonably be enabled on a production system (that has sufficient free storage space). They will be logged if the program is started with-debug=categoryor-debug=1. -
LogInfo(fmt, params...)should only be used rarely, e.g. for startup messages or for infrequent and important events such as a new block tip being found or a new outbound connection being made. These log messages are unconditional, so care must be taken that they can't be used by an attacker to fill up storage. Note thatLogPrintf(fmt, params...)is a deprecated alias forLogInfo. -
LogError(fmt, params...)should be used in place ofLogInfofor severe problems that require the node (or a subsystem) to shut down entirely (e.g., insufficient storage space). -
LogWarning(fmt, params...)should be used in place ofLogInfofor severe problems that the node admin should address, but are not severe enough to warrant shutting down the node (e.g., system time appears to be wrong, unknown soft fork appears to have activated). -
LogTrace(BCLog::CATEGORY, fmt, params...)should be used in place ofLogDebugfor log messages that would be unusable on a production system, e.g. due to being too noisy in normal use, or too resource intensive to process. These will be logged if the startup options-debug=category -loglevel=category:traceor-debug=1 -loglevel=traceare selected.
Note that the format strings and parameters of LogDebug and LogTrace
are only evaluated if the logging category is enabled, so you must be
careful to avoid side-effects in those expressions.
Wallet
- Make sure that no crashes happen with run-time option
-disablewallet.
General C++
For general C++ guidelines, you may refer to the C++ Core Guidelines.
Common misconceptions are clarified in those sections:
-
Passing (non-)fundamental types in the C++ Core Guideline.
-
If you use the
.h, you must link the.cpp.- Rationale: Include files define the interface for the code in implementation files. Including one but
not linking the other is confusing. Please avoid that. Moving functions from
the
.hto the.cppshould not result in build errors.
- Rationale: Include files define the interface for the code in implementation files. Including one but
not linking the other is confusing. Please avoid that. Moving functions from
the
-
Use the RAII (Resource Acquisition Is Initialization) paradigm where possible. For example, by using
unique_ptrfor allocations in a function.- Rationale: This avoids memory and resource leaks, and ensures exception safety.
C++ data structures
-
Never use the
std::map []syntax when reading from a map, but instead use.find().- Rationale:
[]does an insert (of the default element) if the item doesn't exist in the map yet. This has resulted in memory leaks in the past, as well as race conditions (expecting read-read behavior). Using[]is fine for writing to a map.
- Rationale:
-
Do not compare an iterator from one data structure with an iterator of another data structure (even if of the same type).
- Rationale: Behavior is undefined. In C++ parlor this means "may reformat the universe", in practice this has resulted in at least one hard-to-debug crash bug.
-
Watch out for out-of-bounds vector access.
&vch[vch.size()]is illegal, including&vch[0]for an empty vector. Usevch.data()andvch.data() + vch.size()instead. -
Vector bounds checking is only enabled in debug mode. Do not rely on it.
-
Initialize all non-static class members where they are defined. If this is skipped for a good reason (i.e., optimization on the critical path), add an explicit comment about this.
- Rationale: Ensure determinism by avoiding accidental use of uninitialized values. Also, static analyzers balk about this. Initializing the members in the declaration makes it easy to spot uninitialized ones.
class A
{
uint32_t m_count{0};
}
-
By default, declare constructors
explicit.- Rationale: This is a precaution to avoid unintended conversions.
-
Use explicitly signed or unsigned
chars, or even betteruint8_tandint8_t. Do not use barecharunless it is to pass to a third-party API. This type can be signed or unsigned depending on the architecture, which can lead to interoperability problems or dangerous conditions such as out-of-bounds array accesses. -
Prefer explicit constructions over implicit ones that rely on 'magical' C++ behavior.
- Rationale: Easier to understand what is happening, thus easier to spot mistakes, even for those that are not language lawyers.
-
Use
Spanas function argument when it can operate on any range-like container.- Rationale: Compared to
Foo(const vector<int>&)this avoids the need for a (potentially expensive) conversion to vector if the caller happens to have the input stored in another type of container. However, be aware of the pitfalls documented in span.h.
- Rationale: Compared to
void Foo(Span<const int> data);
std::vector<int> vec{1,2,3};
Foo(vec);
-
Prefer
enum class(scoped enumerations) overenum(traditional enumerations) where possible.- Rationale: Scoped enumerations avoid two potential pitfalls/problems with traditional C++ enumerations: implicit conversions to
int, and name clashes due to enumerators being exported to the surrounding scope.
- Rationale: Scoped enumerations avoid two potential pitfalls/problems with traditional C++ enumerations: implicit conversions to
-
switchstatement on an enumeration example:
enum class Tabs {
info,
console,
network_graph,
peers
};
int GetInt(Tabs tab)
{
switch (tab) {
case Tabs::info: return 0;
case Tabs::console: return 1;
case Tabs::network_graph: return 2;
case Tabs::peers: return 3;
} // no default case, so the compiler can warn about missing cases
assert(false);
}
Rationale: The comment documents skipping default: label, and it complies with clang-format rules. The assertion prevents firing of -Wreturn-type warning on some compilers.
Strings and formatting
-
Use
std::string, avoid C string manipulation functions.- Rationale: C++ string handling is marginally safer, less scope for
buffer overflows, and surprises with
\0characters. Also, some C string manipulations tend to act differently depending on platform, or even the user locale.
- Rationale: C++ string handling is marginally safer, less scope for
buffer overflows, and surprises with
-
Use
ToIntegralfromstrencodings.hfor number parsing. In legacy code you might also findParseInt*family of functions,ParseDoubleorLocaleIndependentAtoi.- Rationale: These functions do overflow checking and avoid pesky locale issues.
-
Avoid using locale dependent functions if possible. You can use the provided
lint-locale-dependence.pyto check for accidental use of locale dependent functions.-
Rationale: Unnecessary locale dependence can cause bugs that are very tricky to isolate and fix.
-
These functions are known to be locale dependent:
alphasort,asctime,asprintf,atof,atoi,atol,atoll,atoq,btowc,ctime,dprintf,fgetwc,fgetws,fprintf,fputwc,fputws,fscanf,fwprintf,getdate,getwc,getwchar,isalnum,isalpha,isblank,iscntrl,isdigit,isgraph,islower,isprint,ispunct,isspace,isupper,iswalnum,iswalpha,iswblank,iswcntrl,iswctype,iswdigit,iswgraph,iswlower,iswprint,iswpunct,iswspace,iswupper,iswxdigit,isxdigit,mblen,mbrlen,mbrtowc,mbsinit,mbsnrtowcs,mbsrtowcs,mbstowcs,mbtowc,mktime,putwc,putwchar,scanf,snprintf,sprintf,sscanf,stoi,stol,stoll,strcasecmp,strcasestr,strcoll,strfmon,strftime,strncasecmp,strptime,strtod,strtof,strtoimax,strtol,strtold,strtoll,strtoq,strtoul,strtoull,strtoumax,strtouq,strxfrm,swprintf,tolower,toupper,towctrans,towlower,towupper,ungetwc,vasprintf,vdprintf,versionsort,vfprintf,vfscanf,vfwprintf,vprintf,vscanf,vsnprintf,vsprintf,vsscanf,vswprintf,vwprintf,wcrtomb,wcscasecmp,wcscoll,wcsftime,wcsncasecmp,wcsnrtombs,wcsrtombs,wcstod,wcstof,wcstoimax,wcstol,wcstold,wcstoll,wcstombs,wcstoul,wcstoull,wcstoumax,wcswidth,wcsxfrm,wctob,wctomb,wctrans,wctype,wcwidth,wprintf
-
-
For
strprintf,LogInfo,LogDebug, etc formatting characters don't need size specifiers.- Rationale: Bitcoin Core uses tinyformat, which is type safe. Leave them out to avoid confusion.
-
Use
.c_str()sparingly. Its only valid use is to pass C++ strings to C functions that take NULL-terminated strings.-
Do not use it when passing a sized array (so along with
.size()). Use.data()instead to get a pointer to the raw data.- Rationale: Although this is guaranteed to be safe starting with C++11,
.data()communicates the intent better.
- Rationale: Although this is guaranteed to be safe starting with C++11,
-
Do not use it when passing strings to
tfm::format,strprintf,LogInfo,LogDebug, etc.- Rationale: This is redundant. Tinyformat handles strings.
-
Do not use it to convert to
QString. UseQString::fromStdString().- Rationale: Qt has built-in functionality for converting their string type from/to C++. No need to roll your own.
-
In cases where you do call
.c_str(), you might want to additionally check that the string does not contain embedded '\0' characters, because it will (necessarily) truncate the string. This might be used to hide parts of the string from logging or to circumvent checks. If a use of strings is sensitive to this, take care to check the string for embedded NULL characters first and reject it if there are any (seeParsePrechecksinstrencodings.cppfor an example).
-
Shadowing
Although the shadowing warning (-Wshadow) is not enabled by default (it prevents issues arising
from using a different variable with the same name),
please name variables so that their names do not shadow variables defined in the source code.
When using nested cycles, do not name the inner cycle variable the same as in the outer cycle, etc.
Lifetimebound
The Clang lifetimebound
attribute
can be used to tell the compiler that a lifetime is bound to an object and
potentially see a compile-time warning if the object has a shorter lifetime from
the invalid use of a temporary. You can use the attribute by adding a LIFETIMEBOUND
annotation defined in src/attributes.h; please grep the codebase for examples.
Threads and synchronization
-
Prefer
Mutextype toRecursiveMutexone. -
Consistently use Clang Thread Safety Analysis annotations to get compile-time warnings about potential race conditions or deadlocks in code.
-
In functions that are declared separately from where they are defined, the thread safety annotations should be added exclusively to the function declaration. Annotations on the definition could lead to false positives (lack of compile failure) at call sites between the two.
-
Prefer locks that are in a class rather than global, and that are internal to a class (private or protected) rather than public.
-
Combine annotations in function declarations with run-time asserts in function definitions (
AssertLockNotHeld()can be omitted ifLOCK()is called unconditionally after it becauseLOCK()does the same check asAssertLockNotHeld()internally, for non-recursive mutexes):
-
// txmempool.h
class CTxMemPool
{
public:
...
mutable RecursiveMutex cs;
...
void UpdateTransactionsFromBlock(...) EXCLUSIVE_LOCKS_REQUIRED(::cs_main, cs);
...
}
// txmempool.cpp
void CTxMemPool::UpdateTransactionsFromBlock(...)
{
AssertLockHeld(::cs_main);
AssertLockHeld(cs);
...
}
// validation.h
class Chainstate
{
protected:
...
Mutex m_chainstate_mutex;
...
public:
...
bool ActivateBestChain(
BlockValidationState& state,
std::shared_ptr<const CBlock> pblock = nullptr)
EXCLUSIVE_LOCKS_REQUIRED(!m_chainstate_mutex)
LOCKS_EXCLUDED(::cs_main);
...
bool PreciousBlock(BlockValidationState& state, CBlockIndex* pindex)
EXCLUSIVE_LOCKS_REQUIRED(!m_chainstate_mutex)
LOCKS_EXCLUDED(::cs_main);
...
}
// validation.cpp
bool Chainstate::PreciousBlock(BlockValidationState& state, CBlockIndex* pindex)
{
AssertLockNotHeld(m_chainstate_mutex);
AssertLockNotHeld(::cs_main);
{
LOCK(cs_main);
...
}
return ActivateBestChain(state, std::shared_ptr<const CBlock>());
}
-
Build and run tests with
-DDEBUG_LOCKORDERto verify that no potential deadlocks are introduced. This is defined by default when building with-DCMAKE_BUILD_TYPE=Debug. -
When using
LOCK/TRY_LOCKbe aware that the lock exists in the context of the current scope, so surround the statement and the code that needs the lock with braces.OK:
{
TRY_LOCK(cs_vNodes, lockNodes);
...
}
Wrong:
TRY_LOCK(cs_vNodes, lockNodes);
{
...
}
Scripts
Write scripts in Python rather than bash, when possible.
Shebang
-
Use
#!/usr/bin/env bashinstead of obsolete#!/bin/bash.-
#!/bin/bashassumes it is always installed to /bin/ which can cause issues;#!/usr/bin/env bashsearches the user's PATH to find the bash binary.
OK:
-
#!/usr/bin/env bash
Wrong:
#!/bin/bash
Source code organization
-
Implementation code should go into the
.cppfile and not the.h, unless necessary due to template usage or when performance due to inlining is critical.- Rationale: Shorter and simpler header files are easier to read and reduce compile time.
-
Use only the lowercase alphanumerics (
a-z0-9), underscore (_) and hyphen (-) in source code filenames.- Rationale:
grep:ing and auto-completing filenames is easier when using a consistent naming pattern. Potential problems when building on case-insensitive filesystems are avoided when using only lowercase characters in source code filenames.
- Rationale:
-
Every
.cppand.hfile should#includeevery header file it directly uses classes, functions or other definitions from, even if those headers are already included indirectly through other headers.- Rationale: Excluding headers because they are already indirectly included results in compilation failures when those indirect dependencies change. Furthermore, it obscures what the real code dependencies are.
-
Don't import anything into the global namespace (
using namespace ...). Use fully specified types such asstd::string.- Rationale: Avoids symbol conflicts.
-
Terminate namespaces with a comment (
// namespace mynamespace). The comment should be placed on the same line as the brace closing the namespace, e.g.
namespace mynamespace {
...
} // namespace mynamespace
namespace {
...
} // namespace
-
Rationale: Avoids confusion about the namespace context.
-
Use
#include <primitives/transaction.h>bracket syntax instead of#include "primitives/transactions.h"quote syntax.- Rationale: Bracket syntax is less ambiguous because the preprocessor searches a fixed list of include directories without taking location of the source file into account. This allows quoted includes to stand out more when the location of the source file actually is relevant.
-
Use include guards to avoid the problem of double inclusion. The header file
foo/bar.hshould use the include guard identifierBITCOIN_FOO_BAR_H, e.g.
#ifndef BITCOIN_FOO_BAR_H
#define BITCOIN_FOO_BAR_H
...
#endif // BITCOIN_FOO_BAR_H
GUI
-
Do not display or manipulate dialogs in model code (classes
*Model).- Rationale: Model classes pass through events and data from the core, they should not interact with the user. That's where View classes come in. The converse also holds: try to not directly access core data structures from Views.
-
Avoid adding slow or blocking code in the GUI thread. In particular, do not add new
interfaces::Nodeandinterfaces::Walletmethod calls, even if they may be fast now, in case they are changed to lock or communicate across processes in the future.Prefer to offload work from the GUI thread to worker threads (see
RPCExecutorin console code as an example) or take other steps (see https://doc.qt.io/archives/qq/qq27-responsive-guis.html) to keep the GUI responsive.- Rationale: Blocking the GUI thread can increase latency, and lead to hangs and deadlocks.
Subtrees
Several parts of the repository are subtrees of software maintained elsewhere.
Some of these are maintained by active developers of Bitcoin Core, in which case changes should go directly upstream without being PRed directly against the project. They will be merged back in the next subtree merge.
Others are external projects without a tight relationship with our project. Changes to these should also be sent upstream, but bugfixes may also be prudent to PR against a Bitcoin Core subtree, so that they can be integrated quickly. Cosmetic changes should be taken upstream.
There is a tool in test/lint/git-subtree-check.sh (instructions)
to check a subtree directory for consistency with its upstream repository.
Current subtrees include:
-
src/leveldb
- Subtree at https://github.com/bitcoin-core/leveldb-subtree ; maintained by Core contributors.
- Upstream at https://github.com/google/leveldb ; maintained by Google. Open important PRs to the subtree to avoid delay.
- Note: Follow the instructions in Upgrading LevelDB when merging upstream changes to the LevelDB subtree.
-
src/crc32c
- Used by leveldb for hardware acceleration of CRC32C checksums for data integrity.
- Subtree at https://github.com/bitcoin-core/crc32c-subtree ; maintained by Core contributors.
- Upstream at https://github.com/google/crc32c ; maintained by Google.
-
src/secp256k1
- Upstream at https://github.com/bitcoin-core/secp256k1/ ; maintained by Core contributors.
-
src/crypto/ctaes
- Upstream at https://github.com/bitcoin-core/ctaes ; maintained by Core contributors.
-
src/minisketch
- Upstream at https://github.com/sipa/minisketch ; maintained by Core contributors.
Upgrading LevelDB
Extra care must be taken when upgrading LevelDB. This section explains issues you must be aware of.
File Descriptor Counts
In most configurations, we use the default LevelDB value for max_open_files,
which is 1000 at the time of this writing. If LevelDB actually uses this many
file descriptors, it will cause problems with Bitcoin's select() loop, because
it may cause new sockets to be created where the fd value is >= 1024. For this
reason, on 64-bit Unix systems, we rely on an internal LevelDB optimization that
uses mmap() + close() to open table files without actually retaining
references to the table file descriptors. If you are upgrading LevelDB, you must
sanity check the changes to make sure that this assumption remains valid.
In addition to reviewing the upstream changes in env_posix.cc, you can use lsof to
check this. For example, on Linux this command will show open .ldb file counts:
$ lsof -p $(pidof bitcoind) |\
awk 'BEGIN { fd=0; mem=0; } /ldb$/ { if ($4 == "mem") mem++; else fd++ } END { printf "mem = %s, fd = %s\n", mem, fd}'
mem = 119, fd = 0
The mem value shows how many files are mmap'ed, and the fd value shows you
many file descriptors these files are using. You should check that fd is a
small number (usually 0 on 64-bit hosts).
See the notes in the SetMaxOpenFiles() function in dbwrapper.cc for more
details.
Consensus Compatibility
It is possible for LevelDB changes to inadvertently change consensus compatibility between nodes. This happened in Bitcoin 0.8 (when LevelDB was first introduced). When upgrading LevelDB, you should review the upstream changes to check for issues affecting consensus compatibility.
For example, if LevelDB had a bug that accidentally prevented a key from being returned in an edge case, and that bug was fixed upstream, the bug "fix" would be an incompatible consensus change. In this situation, the correct behavior would be to revert the upstream fix before applying the updates to Bitcoin's copy of LevelDB. In general, you should be wary of any upstream changes affecting what data is returned from LevelDB queries.
Scripted diffs
For reformatting and refactoring commits where the changes can be easily automated using a bash script, we use scripted-diff commits. The bash script is included in the commit message and our CI job checks that the result of the script is identical to the commit. This aids reviewers since they can verify that the script does exactly what it is supposed to do. It is also helpful for rebasing (since the same script can just be re-run on the new master commit).
To create a scripted-diff:
- start the commit message with
scripted-diff:(and then a description of the diff on the same line) - in the commit message include the bash script between lines containing just the following text:
-BEGIN VERIFY SCRIPT--END VERIFY SCRIPT-
The scripted-diff is verified by the tool test/lint/commit-script-check.sh. The tool's default behavior, when supplied
with a commit is to verify all scripted-diffs from the beginning of time up to said commit. Internally, the tool passes
the first supplied argument to git rev-list --reverse to determine which commits to verify script-diffs for, ignoring
commits that don't conform to the commit message format described above.
For development, it might be more convenient to verify all scripted-diffs in a range A..B, for example:
test/lint/commit-script-check.sh origin/master..HEAD
Suggestions and examples
If you need to replace in multiple files, prefer git ls-files to find or globbing, and git grep to grep, to
avoid changing files that are not under version control.
For efficient replacement scripts, reduce the selection to the files that potentially need to be modified, so for
example, instead of a blanket git ls-files src | xargs sed -i s/apple/orange/, use
git grep -l apple src | xargs sed -i s/apple/orange/.
Also, it is good to keep the selection of files as specific as possible — for example, replace only in directories where you expect replacements — because it reduces the risk that a rebase of your commit by re-running the script will introduce accidental changes.
Some good examples of scripted-diff:
-
scripted-diff: Rename InitInterfaces to NodeContext uses an elegant script to replace occurrences of multiple terms in all source files.
-
scripted-diff: Remove g_connman, g_banman globals replaces specific terms in a list of specific source files.
-
scripted-diff: Replace fprintf with tfm::format does a global replacement but excludes certain directories.
To find all previous uses of scripted diffs in the repository, do:
git log --grep="-BEGIN VERIFY SCRIPT-"
Release notes
Release notes should be written for any PR that:
- introduces a notable new feature
- fixes a significant bug
- changes an API or configuration model
- makes any other visible change to the end-user experience.
Release notes should be added to a PR-specific release note file at
/doc/release-notes-<PR number>.md to avoid conflicts between multiple PRs.
All release-notes* files are merged into a single release-notes-<version>.md file prior to the release.
RPC interface guidelines
A few guidelines for introducing and reviewing new RPC interfaces:
-
Method naming: use consecutive lower-case names such as
getrawtransactionandsubmitblock.- Rationale: Consistency with the existing interface.
-
Argument and field naming: please consider whether there is already a naming style or spelling convention in the API for the type of object in question (
blockhash, for example), and if so, try to use that. If not, use snake casefee_delta(and not, e.g.feedeltaor camel casefeeDelta).- Rationale: Consistency with the existing interface.
-
Use the JSON parser for parsing, don't manually parse integers or strings from arguments unless absolutely necessary.
-
Rationale: Introduces hand-rolled string manipulation code at both the caller and callee sites, which is error-prone, and it is easy to get things such as escaping wrong. JSON already supports nested data structures, no need to re-invent the wheel.
-
Exception: AmountFromValue can parse amounts as string. This was introduced because many JSON parsers and formatters hard-code handling decimal numbers as floating-point values, resulting in potential loss of precision. This is unacceptable for monetary values. Always use
AmountFromValueandValueFromAmountwhen inputting or outputting monetary values. The only exceptions to this areprioritisetransactionandgetblocktemplatebecause their interface is specified as-is in BIP22.
-
-
Missing arguments and 'null' should be treated the same: as default values. If there is no default value, both cases should fail in the same way. The easiest way to follow this guideline is to detect unspecified arguments with
params[x].isNull()instead ofparams.size() <= x. The former returns true if the argument is either null or missing, while the latter returns true if is missing, and false if it is null.- Rationale: Avoids surprises when switching to name-based arguments. Missing name-based arguments are passed as 'null'.
-
Try not to overload methods on argument type. E.g. don't make
getblock(true)andgetblock("hash")do different things.-
Rationale: This is impossible to use with
bitcoin-cli, and can be surprising to users. -
Exception: Some RPC calls can take both an
intandbool, most notably when a bool was switched to a multi-value, or due to other historical reasons. Always have false map to 0 and true to 1 in this case.
-
-
For new RPC methods, if implementing a
verbosityargument, use integer verbosity rather than boolean. Disallow usage of boolean verbosity (seeParseVerbosity()in util.h).- Rationale: Integer verbosity allows for multiple values. Undocumented boolean verbosity is deprecated and new RPC methods should prevent its use.
-
Don't forget to fill in the argument names correctly in the RPC command table.
- Rationale: If not, the call cannot be used with name-based arguments.
-
Add every non-string RPC argument
(method, idx, name)to the tablevRPCConvertParamsinrpc/client.cpp.- Rationale:
bitcoin-cliand the GUI debug console use this table to determine how to convert a plaintext command line to JSON. If the types don't match, the method can be unusable from there.
- Rationale:
-
A RPC method must either be a wallet method or a non-wallet method. Do not introduce new methods that differ in behavior based on the presence of a wallet.
- Rationale: As well as complicating the implementation and interfering with the introduction of multi-wallet, wallet and non-wallet code should be separated to avoid introducing circular dependencies between code units.
-
Try to make the RPC response a JSON object.
- Rationale: If a RPC response is not a JSON object, then it is harder to avoid API breakage if new data in the response is needed.
-
Wallet RPCs call BlockUntilSyncedToCurrentChain to maintain consistency with
getblockchaininfo's state immediately prior to the call's execution. Wallet RPCs whose behavior does not depend on the current chainstate may omit this call.- Rationale: In previous versions of Bitcoin Core, the wallet was always in-sync with the chainstate (by virtue of them all being updated in the same cs_main lock). In order to maintain the behavior that wallet RPCs return results as of at least the highest best-known block an RPC client may be aware of prior to entering a wallet RPC call, we must block until the wallet is caught up to the chainstate as of the RPC call's entry. This also makes the API much easier for RPC clients to reason about.
-
Be aware of RPC method aliases and generally avoid registering the same callback function pointer for different RPCs.
-
Rationale: RPC methods registered with the same function pointer will be considered aliases and only the first method name will show up in the
helpRPC command list. -
Exception: Using RPC method aliases may be appropriate in cases where a new RPC is replacing a deprecated RPC, to avoid both RPCs confusingly showing up in the command list.
-
-
Use invalid bech32 addresses (e.g. in the constant array
EXAMPLE_ADDRESS) forRPCExampleshelp documentation.- Rationale: Prevent accidental transactions by users and encourage the use of bech32 addresses by default.
-
Use the
UNIX_EPOCH_TIMEconstant when describing UNIX epoch time or timestamps in the documentation.- Rationale: User-facing consistency.
-
Use
fs::path::u8string()/fs::path::utf8string()andfs::u8path()functions when converting path to JSON strings, notfs::PathToStringandfs::PathFromString- Rationale: JSON strings are Unicode strings, not byte strings, and RFC8259 requires JSON to be encoded as UTF-8.
Internal interface guidelines
Internal interfaces between parts of the codebase that are meant to be
independent (node, wallet, GUI), are defined in
src/interfaces/. The main interface classes defined
there are interfaces::Chain, used by wallet to
access the node's latest chain state,
interfaces::Node, used by the GUI to control the
node, interfaces::Wallet, used by the GUI
to control an individual wallet and interfaces::Mining,
used by RPC to generate block templates. There are also more specialized interface
types like interfaces::Handler
interfaces::ChainClient passed to and from
various interface methods.
Interface classes are written in a particular style so node, wallet, and GUI code doesn't need to run in the same process, and so the class declarations work more easily with tools and libraries supporting interprocess communication:
-
Interface classes should be abstract and have methods that are pure virtual. This allows multiple implementations to inherit from the same interface class, particularly so one implementation can execute functionality in the local process, and other implementations can forward calls to remote processes.
-
Interface method definitions should wrap existing functionality instead of implementing new functionality. Any substantial new node or wallet functionality should be implemented in
src/node/orsrc/wallet/and just exposed insrc/interfaces/instead of being implemented there, so it can be more modular and accessible to unit tests. -
Interface method parameter and return types should either be serializable or be other interface classes. Interface methods shouldn't pass references to objects that can't be serialized or accessed from another process.
Examples:
// Good: takes string argument and returns interface class pointer virtual unique_ptr<interfaces::Wallet> loadWallet(std::string filename) = 0; // Bad: returns CWallet reference that can't be used from another process virtual CWallet& loadWallet(std::string filename) = 0;// Good: accepts and returns primitive types virtual bool findBlock(const uint256& hash, int& out_height, int64_t& out_time) = 0; // Bad: returns pointer to internal node in a linked list inaccessible to // other processes virtual const CBlockIndex* findBlock(const uint256& hash) = 0;// Good: takes plain callback type and returns interface pointer using TipChangedFn = std::function<void(int block_height, int64_t block_time)>; virtual std::unique_ptr<interfaces::Handler> handleTipChanged(TipChangedFn fn) = 0; // Bad: returns boost connection specific to local process using TipChangedFn = std::function<void(int block_height, int64_t block_time)>; virtual boost::signals2::scoped_connection connectTipChanged(TipChangedFn fn) = 0; -
Interface methods should not be overloaded.
Rationale: consistency and friendliness to code generation tools.
Example:
// Good: method names are unique virtual bool disconnectByAddress(const CNetAddr& net_addr) = 0; virtual bool disconnectById(NodeId id) = 0; // Bad: methods are overloaded by type virtual bool disconnect(const CNetAddr& net_addr) = 0; virtual bool disconnect(NodeId id) = 0;
Internal interface naming style
-
Interface method names should be
lowerCamelCaseand standalone function names should beUpperCamelCase.Rationale: consistency and friendliness to code generation tools.
Examples:
// Good: lowerCamelCase method name virtual void blockConnected(const CBlock& block, int height) = 0; // Bad: uppercase class method virtual void BlockConnected(const CBlock& block, int height) = 0;// Good: UpperCamelCase standalone function name std::unique_ptr<Node> MakeNode(LocalInit& init); // Bad: lowercase standalone function std::unique_ptr<Node> makeNode(LocalInit& init);Note: This last convention isn't generally followed outside of
src/interfaces/, though it did come up for discussion before in #14635.
Expectations for DNS Seed operators
Bitcoin Core attempts to minimize the level of trust in DNS seeds, but DNS seeds still pose a small amount of risk for the network. As such, DNS seeds must be run by entities which have some minimum level of trust within the Bitcoin community.
Other implementations of Bitcoin software may also use the same seeds and may be more exposed. In light of this exposure, this document establishes some basic expectations for operating dnsseeds.
-
A DNS seed operating organization or person is expected to follow good host security practices, maintain control of applicable infrastructure, and not sell or transfer control of the DNS seed. Any hosting services contracted by the operator are equally expected to uphold these expectations.
-
The DNS seed results must consist exclusively of fairly selected and functioning Bitcoin nodes from the public network to the best of the operator's understanding and capability.
-
For the avoidance of doubt, the results may be randomized but must not single-out any group of hosts to receive different results unless due to an urgent technical necessity and disclosed.
-
The results may not be served with a DNS TTL of less than one minute.
-
Any logging of DNS queries should be only that which is necessary for the operation of the service or urgent health of the Bitcoin network and must not be retained longer than necessary nor disclosed to any third party.
-
Information gathered as a result of the operators node-spidering (not from DNS queries) may be freely published or retained, but only if this data was not made more complete by biasing node connectivity (a violation of expectation (1)).
-
Operators are encouraged, but not required, to publicly document the details of their operating practices.
-
A reachable email contact address must be published for inquiries related to the DNS seed operation.
If these expectations cannot be satisfied the operator should discontinue providing services and contact the active Bitcoin Core development team as well as posting on bitcoin-dev.
Behavior outside of these expectations may be reasonable in some situations but should be discussed in public in advance.
See also
- bitcoin-seeder is a reference implementation of a DNS seed.
Support for signing transactions outside of Bitcoin Core
Bitcoin Core can be launched with -signer=<cmd> where <cmd> is an external tool which can sign transactions and perform other functions. For example, it can be used to communicate with a hardware wallet.
Example usage
The following example is based on the HWI tool. Version 2.0 or newer is required. Although this tool is hosted under the Bitcoin Core GitHub organization and maintained by Bitcoin Core developers, it should be used with caution. It is considered experimental and has far less review than Bitcoin Core itself. Be particularly careful when running tools such as these on a computer with private keys on it.
When using a hardware wallet, consult the manufacturer website for (alternative) software they recommend. As long as their software conforms to the standard below, it should be able to work with Bitcoin Core.
Start Bitcoin Core:
$ bitcoind -signer=../HWI/hwi.py
Device setup
Follow the hardware manufacturers instructions for the initial device setup, as well as their instructions for creating a backup. Alternatively, for some devices, you can use the setup, restore and backup commands provided by HWI.
Create wallet and import keys
Get a list of signing devices / services:
$ bitcoin-cli enumeratesigners
{
"signers": [
{
"fingerprint": "c8df832a"
}
]
The master key fingerprint is used to identify a device.
Create a wallet, this automatically imports the public keys:
$ bitcoin-cli createwallet "hww" true true "" true true true
Verify an address
Display an address on the device:
$ bitcoin-cli -rpcwallet=<wallet> getnewaddress
$ bitcoin-cli -rpcwallet=<wallet> walletdisplayaddress <address>
Replace <address> with the result of getnewaddress.
Spending
Under the hood this uses a Partially Signed Bitcoin Transaction.
$ bitcoin-cli -rpcwallet=<wallet> sendtoaddress <address> <amount>
This prompts your hardware wallet to sign, and fail if it's not connected. If successful it automatically broadcasts the transaction.
{"complete": true, "txid": <txid>}
Signer API
In order to be compatible with Bitcoin Core any signer command should conform to the specification below. This specification is subject to change. Ideally a BIP should propose a standard so that other wallets can also make use of it.
Prerequisite knowledge:
- Output Descriptors
- Partially Signed Bitcoin Transaction (PSBT)
enumerate (required)
Usage:
$ <cmd> enumerate
[
{
"fingerprint": "00000000"
}
]
The command MUST return an (empty) array with at least a fingerprint field.
A future extension could add an optional return field with device capabilities. Perhaps a descriptor with wildcards. For example: ["pkh("44'/0'/$'/{0,1}/*"), sh(wpkh("49'/0'/$'/{0,1}/*")), wpkh("84'/0'/$'/{0,1}/*")]. This would indicate the device supports legacy, wrapped SegWit and native SegWit. In addition it restricts the derivation paths that can used for those, to maintain compatibility with other wallet software. It also indicates the device, or the driver, doesn't support multisig.
A future extension could add an optional return field reachable, in case <cmd> knows a signer exists but can't currently reach it.
signtransaction (required)
Usage:
$ <cmd> --fingerprint=<fingerprint> (--testnet) signtransaction <psbt>
base64_encode_signed_psbt
The command returns a psbt with any signatures.
The psbt SHOULD include bip32 derivations. The command SHOULD fail if none of the bip32 derivations match a key owned by the device.
The command SHOULD fail if the user cancels.
The command MAY complain if --testnet is set, but any of the BIP32 derivation paths contain a coin type other than 1h (and vice versa).
getdescriptors (optional)
Usage:
$ <cmd> --fingerprint=<fingerprint> (--testnet) getdescriptors <account>
<xpub>
Returns descriptors supported by the device. Example:
$ <cmd> --fingerprint=00000000 --testnet getdescriptors
{
"receive": [
"pkh([00000000/44h/0h/0h]xpub6C.../0/*)#fn95jwmg",
"sh(wpkh([00000000/49h/0h/0h]xpub6B..../0/*))#j4r9hntt",
"wpkh([00000000/84h/0h/0h]xpub6C.../0/*)#qw72dxa9"
],
"internal": [
"pkh([00000000/44h/0h/0h]xpub6C.../1/*)#c8q40mts",
"sh(wpkh([00000000/49h/0h/0h]xpub6B..../1/*))#85dn0v75",
"wpkh([00000000/84h/0h/0h]xpub6C..../1/*)#36mtsnda"
]
}
displayaddress (optional)
Usage:
<cmd> --fingerprint=<fingerprint> (--testnet) displayaddress --desc descriptor
Example, display the first native SegWit receive address on Testnet:
<cmd> --fingerprint=00000000 --testnet displayaddress --desc "wpkh([00000000/84h/1h/0h]tpubDDUZ..../0/0)"
The command MUST be able to figure out the address type from the descriptor.
The command MUST return an object containing {"address": "[the address]"}.
As a sanity check, for devices that support this, it SHOULD ask the device to derive the address.
If
If
The command MAY complain if --testnet is set, but the BIP32 coin type is not 1h (and vice versa).
How Bitcoin Core uses the Signer API
The enumeratesigners RPC simply calls <cmd> enumerate.
The createwallet RPC calls:
<cmd> --fingerprint=00000000 getdescriptors 0
It then imports descriptors for all support address types, in a BIP44/49/84 compatible manner.
The walletdisplayaddress RPC reuses some code from getaddressinfo on the provided address and obtains the inferred descriptor. It then calls <cmd> --fingerprint=00000000 displayaddress --desc=<descriptor>.
sendtoaddress and sendmany check inputs->bip32_derivs to see if any inputs have the same master_fingerprint as the signer. If so, it calls <cmd> --fingerprint=00000000 signtransaction <psbt>. It waits for the device to return a (partially) signed psbt, tries to finalize it and broadcasts the transaction.
Bitcoin Core file system
Contents
Data directory location
The data directory is the default location where the Bitcoin Core files are stored.
- The default data directory paths for supported platforms are:
| Platform | Data directory path |
|---|---|
| Linux | $HOME/.bitcoin/ |
| macOS | $HOME/Library/Application Support/Bitcoin/ |
| Windows | %LOCALAPPDATA%\Bitcoin\ [1] |
-
A custom data directory path can be specified with the
-datadiroption. -
All content of the data directory, except for
bitcoin.conffile, is chain-specific. This means the actual data directory paths for non-mainnet cases differ:
| Chain option | Data directory path |
|---|---|
-chain=main (default) | path_to_datadir/ |
-chain=test or -testnet | path_to_datadir/testnet3/ |
-chain=testnet4 or -testnet4 | path_to_datadir/testnet4/ |
-chain=signet or -signet | path_to_datadir/signet/ |
-chain=regtest or -regtest | path_to_datadir/regtest/ |
Data directory layout
| Subdirectory | File(s) | Description |
|---|---|---|
blocks/ | Blocks directory; can be specified by -blocksdir option (except for blocks/index/) | |
blocks/index/ | LevelDB database | Block index; -blocksdir option does not affect this path |
blocks/ | blkNNNNN.dat[2] | Actual Bitcoin blocks (dumped in network format, 128 MiB per file) |
blocks/ | revNNNNN.dat[2] | Block undo data (custom format) |
blocks/ | xor.dat | Rolling XOR pattern for block and undo data files |
chainstate/ | LevelDB database | Blockchain state (a compact representation of all currently unspent transaction outputs (UTXOs) and metadata about the transactions they are from) |
indexes/txindex/ | LevelDB database | Transaction index; optional, used if -txindex=1 |
indexes/blockfilter/basic/db/ | LevelDB database | Blockfilter index LevelDB database for the basic filtertype; optional, used if -blockfilterindex=basic |
indexes/blockfilter/basic/ | fltrNNNNN.dat[2] | Blockfilter index filters for the basic filtertype; optional, used if -blockfilterindex=basic |
indexes/coinstats/db/ | LevelDB database | Coinstats index; optional, used if -coinstatsindex=1 |
wallets/ | Contains wallets; can be specified by -walletdir option; if wallets/ subdirectory does not exist, wallets reside in the data directory | |
./ | anchors.dat | Anchor IP address database, created on shutdown and deleted at startup. Anchors are last known outgoing block-relay-only peers that are tried to re-connect to on startup |
./ | banlist.json | Stores the addresses/subnets of banned nodes. |
./ | bitcoin.conf | User-defined configuration settings for bitcoind or bitcoin-qt. File is not written to by the software and must be created manually. Path can be specified by -conf option |
./ | bitcoind.pid | Stores the process ID (PID) of bitcoind or bitcoin-qt while running; created at start and deleted on shutdown; can be specified by -pid option |
./ | debug.log | Contains debug information and general logging generated by bitcoind or bitcoin-qt; can be specified by -debuglogfile option |
./ | fee_estimates.dat | Stores statistics used to estimate minimum transaction fees required for confirmation |
./ | guisettings.ini.bak | Backup of former GUI settings after -resetguisettings option is used |
./ | ip_asn.map | IP addresses to Autonomous System Numbers (ASNs) mapping used for bucketing of the peers; path can be specified with the -asmap option |
./ | mempool.dat | Dump of the mempool's transactions |
./ | onion_v3_private_key | Cached Tor onion service private key for -listenonion option |
./ | i2p_private_key | Private key that corresponds to our I2P address. When -i2psam= is specified the contents of this file is used to identify ourselves for making outgoing connections to I2P peers and possibly accepting incoming ones. Automatically generated if it does not exist. |
./ | peers.dat | Peer IP address database (custom format) |
./ | settings.json | Read-write settings set through GUI or RPC interfaces, augmenting manual settings from bitcoin.conf. File is created automatically if read-write settings storage is not disabled with -nosettings option. Path can be specified with -settings option |
./ | .cookie | Session RPC authentication cookie; if used, created at start and deleted on shutdown; can be specified by -rpccookiefile option |
./ | .lock | Data directory lock file |
Multi-wallet environment
Wallets are Berkeley DB (BDB) or SQLite databases.
-
Each user-defined wallet named "wallet_name" resides in the
wallets/wallet_name/subdirectory. -
The default (unnamed) wallet resides in
wallets/subdirectory; if the latter does not exist, the wallet resides in the data directory. -
A wallet database path can be specified with the
-walletoption. -
wallet.datfiles must not be shared across different node instances, as that can result in key-reuse and double-spends due the lack of synchronization between instances. -
Any copy or backup of the wallet should be done through a
backupwalletcall in order to update and lock the wallet, preventing any file corruption caused by updates during the copy.
Berkeley DB database based wallets
| Subdirectory | File(s) | Description |
|---|---|---|
database/ | BDB logging files | Part of BDB environment; created at start and deleted on shutdown; a user must keep it as safe as personal wallet wallet.dat |
./ | db.log | BDB error file |
./ | wallet.dat | Personal wallet (a BDB database) with keys and transactions |
./ | .walletlock | BDB wallet lock file |
SQLite database based wallets
| Subdirectory | File | Description |
|---|---|---|
./ | wallet.dat | Personal wallet (a SQLite database) with keys and transactions |
./ | wallet.dat-journal | SQLite Rollback Journal file for wallet.dat. Usually created at start and deleted on shutdown. A user must keep it as safe as the wallet.dat file. |
GUI settings
bitcoin-qt uses QSettings class; this implies platform-specific locations where application settings are stored.
Legacy subdirectories and files
These subdirectories and files are no longer used by Bitcoin Core:
| Path | Description | Repository notes |
|---|---|---|
banlist.dat | Stores the addresses/subnets of banned nodes; superseded by banlist.json in 22.0 and completely ignored in 23.0 | PR #20966, PR #22570 |
blktree/ | Blockchain index; replaced by blocks/index/ in 0.8.0 | PR #2231, 8fdc94cc |
coins/ | Unspent transaction output database; replaced by chainstate/ in 0.8.0 | PR #2231, 8fdc94cc |
blkindex.dat | Blockchain index BDB database; replaced by {chainstate/, blocks/index/, blocks/revNNNNN.dat[2]} in 0.8.0 | PR #1677 |
blk000?.dat | Block data (custom format, 2 GiB per file); replaced by blocks/blkNNNNN.dat[2] in 0.8.0 | PR #1677 |
addr.dat | Peer IP address BDB database; replaced by peers.dat in 0.7.0 | PR #1198, 928d3a01 |
onion_private_key | Cached Tor onion service private key for -listenonion option. Was used for Tor v2 services; replaced by onion_v3_private_key in 0.21.0 | PR #19954 |
Notes
1. The / (slash, U+002F) is used as the platform-independent path component separator in this document.
2. NNNNN matches [0-9]{5} regex.
Fuzzing Bitcoin Core using libFuzzer
Quickstart guide
To quickly get started fuzzing Bitcoin Core using libFuzzer:
$ git clone https://github.com/bitcoin/bitcoin
$ cd bitcoin/
$ cmake --preset=libfuzzer
# macOS users: If you have problem with this step then make sure to read "macOS hints for
# libFuzzer" on https://github.com/bitcoin/bitcoin/blob/master/doc/fuzzing.md#macos-hints-for-libfuzzer
$ cmake --build build_fuzz
$ FUZZ=process_message build_fuzz/src/test/fuzz/fuzz
# abort fuzzing using ctrl-c
One can use --prefix=libfuzzer-nosan to do the same without common sanitizers enabled.
See further for more information.
There is also a runner script to execute all fuzz targets. Refer to
./test/fuzz/test_runner.py --help for more details.
Overview of Bitcoin Core fuzzing
Google has a good overview of fuzzing in general, with contributions from key architects of some of the most-used fuzzers. This paper includes an external overview of the status of Bitcoin Core fuzzing, as of summer 2021. John Regehr provides good advice on writing code that assists fuzzers in finding bugs, which is useful for developers to keep in mind.
Fuzzing harnesses and output
process_message is a fuzzing harness for the ProcessMessage(...) function (net_processing). The available fuzzing harnesses are found in src/test/fuzz/.
The fuzzer will output NEW every time it has created a test input that covers new areas of the code under test. For more information on how to interpret the fuzzer output, see the libFuzzer documentation.
If you specify a corpus directory then any new coverage increasing inputs will be saved there:
$ mkdir -p process_message-seeded-from-thin-air/
$ FUZZ=process_message build_fuzz/src/test/fuzz/fuzz process_message-seeded-from-thin-air/
INFO: Seed: 840522292
INFO: Loaded 1 modules (424174 inline 8-bit counters): 424174 [0x55e121ef9ab8, 0x55e121f613a6),
INFO: Loaded 1 PC tables (424174 PCs): 424174 [0x55e121f613a8,0x55e1225da288),
INFO: 0 files found in process_message-seeded-from-thin-air/
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes
INFO: A corpus is not provided, starting from an empty corpus
#2 INITED cov: 94 ft: 95 corp: 1/1b exec/s: 0 rss: 150Mb
#3 NEW cov: 95 ft: 96 corp: 2/3b lim: 4 exec/s: 0 rss: 150Mb L: 2/2 MS: 1 InsertByte-
#4 NEW cov: 96 ft: 98 corp: 3/7b lim: 4 exec/s: 0 rss: 150Mb L: 4/4 MS: 1 CrossOver-
#21 NEW cov: 96 ft: 100 corp: 4/11b lim: 4 exec/s: 0 rss: 150Mb L: 4/4 MS: 2 ChangeBit-CrossOver-
#324 NEW cov: 101 ft: 105 corp: 5/12b lim: 6 exec/s: 0 rss: 150Mb L: 6/6 MS: 5 CrossOver-ChangeBit-CopyPart-ChangeBit-ChangeBinInt-
#1239 REDUCE cov: 102 ft: 106 corp: 6/24b lim: 14 exec/s: 0 rss: 150Mb L: 13/13 MS: 5 ChangeBit-CrossOver-EraseBytes-ChangeBit-InsertRepeatedBytes-
#1272 REDUCE cov: 102 ft: 106 corp: 6/23b lim: 14 exec/s: 0 rss: 150Mb L: 12/12 MS: 3 ChangeBinInt-ChangeBit-EraseBytes-
NEW_FUNC[1/677]: 0x55e11f456690 in std::_Function_base::~_Function_base() /usr/lib/gcc/x86_64-linux-gnu/8/../../../../include/c++/8/bits/std_function.h:255
NEW_FUNC[2/677]: 0x55e11f465800 in CDataStream::CDataStream(std::vector<unsigned char, std::allocator<unsigned char> > const&, int, int) src/./streams.h:248
#2125 REDUCE cov: 4820 ft: 4867 corp: 7/29b lim: 21 exec/s: 0 rss: 155Mb L: 6/12 MS: 2 CopyPart-CMP- DE: "block"-
NEW_FUNC[1/9]: 0x55e11f64d790 in std::_Rb_tree<uint256, std::pair<uint256 const, std::chrono::duration<long, std::ratio<1l, 1000000l> > >, std::_Select1st<std::pair<uint256 const, std::chrono::duration<long, std::ratio<1l, 1000000l> > > >, std::less<uint256>, std::allocator<std::pair<uint256 const, std::chrono::duration<long, std::ratio<1l, 1000000l> > > > >::~_Rb_tree() /usr/lib/gcc/x86_64-linux-gnu/8/../../../../include/c++/8/bits/stl_tree.h:972
NEW_FUNC[2/9]: 0x55e11f64d870 in std::_Rb_tree<uint256, std::pair<uint256 const, std::chrono::duration<long, std::ratio<1l, 1000000l> > >, std::_Select1st<std::pair<uint256 const, std::chrono::duration<long, std::ratio<1l, 1000000l> > > >, std::less<uint256>, std::allocator<std::pair<uint256 const, std::chrono::duration<long, std::ratio<1l, 1000000l> > > > >::_M_erase(std::_Rb_tree_node<std::pair<uint256 const, std::chrono::duration<long, std::ratio<1l, 1000000l> > > >*) /usr/lib/gcc/x86_64-linux-gnu/8/../../../../include/c++/8/bits/stl_tree.h:1875
#2228 NEW cov: 4898 ft: 4971 corp: 8/35b lim: 21 exec/s: 0 rss: 156Mb L: 6/12 MS: 3 EraseBytes-CopyPart-PersAutoDict- DE: "block"-
NEW_FUNC[1/5]: 0x55e11f46df70 in std::enable_if<__and_<std::allocator_traits<zero_after_free_allocator<char> >::__construct_helper<char, unsigned char const&>::type>::value, void>::type std::allocator_traits<zero_after_free_allocator<char> >::_S_construct<char, unsigned char const&>(zero_after_free_allocator<char>&, char*, unsigned char const&) /usr/lib/gcc/x86_64-linux-gnu/8/../../../../include/c++/8/bits/alloc_traits.h:243
NEW_FUNC[2/5]: 0x55e11f477390 in std::vector<unsigned char, std::allocator<unsigned char> >::data() /usr/lib/gcc/x86_64-linux-gnu/8/../../../../include/c++/8/bits/stl_vector.h:1056
#2456 NEW cov: 4933 ft: 5042 corp: 9/55b lim: 21 exec/s: 0 rss: 160Mb L: 20/20 MS: 3 ChangeByte-InsertRepeatedBytes-PersAutoDict- DE: "block"-
#2467 NEW cov: 4933 ft: 5043 corp: 10/76b lim: 21 exec/s: 0 rss: 161Mb L: 21/21 MS: 1 InsertByte-
#4215 NEW cov: 4941 ft: 5129 corp: 17/205b lim: 29 exec/s: 4215 rss: 350Mb L: 29/29 MS: 5 InsertByte-ChangeBit-CopyPart-InsertRepeatedBytes-CrossOver-
#4567 REDUCE cov: 4941 ft: 5129 corp: 17/204b lim: 29 exec/s: 4567 rss: 404Mb L: 24/29 MS: 2 ChangeByte-EraseBytes-
#6642 NEW cov: 4941 ft: 5138 corp: 18/244b lim: 43 exec/s: 2214 rss: 450Mb L: 43/43 MS: 3 CopyPart-CMP-CrossOver- DE: "verack"-
# abort fuzzing using ctrl-c
$ ls process_message-seeded-from-thin-air/
349ac589fc66a09abc0b72bb4ae445a7a19e2cd8 4df479f1f421f2ea64b383cd4919a272604087a7
a640312c98dcc55d6744730c33e41c5168c55f09 b135de16e4709558c0797c15f86046d31c5d86d7
c000f7b41b05139de8b63f4cbf7d1ad4c6e2aa7f fc52cc00ec1eb1c08470e69f809ae4993fa70082
$ cat --show-nonprinting process_message-seeded-from-thin-air/349ac589fc66a09abc0b72bb4ae445a7a19e2cd8
block^@M-^?M-^?M-^?M-^?M-^?nM-^?M-^?
In this case the fuzzer managed to create a block message which when passed to ProcessMessage(...) increased coverage.
It is possible to specify bitcoind arguments to the fuzz executable.
Depending on the test, they may be ignored or consumed and alter the behavior
of the test. Just make sure to use double-dash to distinguish them from the
fuzzer's own arguments:
$ FUZZ=address_deserialize_v2 build_fuzz/src/test/fuzz/fuzz -runs=1 fuzz_corpora/address_deserialize_v2 --checkaddrman=5 --printtoconsole=1
Fuzzing corpora
The project's collection of seed corpora is found in the bitcoin-core/qa-assets repo.
To fuzz process_message using the bitcoin-core/qa-assets seed corpus:
$ git clone https://github.com/bitcoin-core/qa-assets
$ FUZZ=process_message build_fuzz/src/test/fuzz/fuzz qa-assets/fuzz_corpora/process_message/
INFO: Seed: 1346407872
INFO: Loaded 1 modules (424174 inline 8-bit counters): 424174 [0x55d8a9004ab8, 0x55d8a906c3a6),
INFO: Loaded 1 PC tables (424174 PCs): 424174 [0x55d8a906c3a8,0x55d8a96e5288),
INFO: 991 files found in qa-assets/fuzz_corpora/process_message/
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes
INFO: seed corpus: files: 991 min: 1b max: 1858b total: 288291b rss: 150Mb
#993 INITED cov: 7063 ft: 8236 corp: 25/3821b exec/s: 0 rss: 181Mb
…
Run without sanitizers for increased throughput
Fuzzing on a harness compiled with -DSANITIZERS=address,fuzzer,undefined is
good for finding bugs. However, the very slow execution even under libFuzzer
will limit the ability to find new coverage. A good approach is to perform
occasional long runs without the additional bug-detectors
(--preset=libfuzzer-nosan) and then merge new inputs into a corpus as described in
the qa-assets repo
(https://github.com/bitcoin-core/qa-assets/blob/main/.github/PULL_REQUEST_TEMPLATE.md).
Patience is useful; even with improved throughput, libFuzzer may need days and
10s of millions of executions to reach deep/hard targets.
Reproduce a fuzzer crash reported by the CI
cdinto theqa-assetsdirectory and update it withgit pull qa-assets- locate the crash case described in the CI output, e.g.
Test unit written to ./crash-1bc91feec9fc00b107d97dc225a9f2cdaa078eb6 - make sure to compile with all sanitizers, if they are needed (fuzzing runs more slowly with sanitizers enabled, but a crash should be reproducible very quickly from a crash case)
- run the fuzzer with the case number appended to the seed corpus path:
FUZZ=process_message build_fuzz/src/test/fuzz/fuzz qa-assets/fuzz_corpora/process_message/1bc91feec9fc00b107d97dc225a9f2cdaa078eb6
Submit improved coverage
If you find coverage increasing inputs when fuzzing you are highly encouraged to submit them for inclusion in the bitcoin-core/qa-assets repo.
Every single pull request submitted against the Bitcoin Core repo is automatically tested against all inputs in the bitcoin-core/qa-assets repo. Contributing new coverage increasing inputs is an easy way to help make Bitcoin Core more robust.
macOS hints for libFuzzer
The default Clang/LLVM version supplied by Apple on macOS does not include
fuzzing libraries, so macOS users will need to install a full version, for
example using brew install llvm.
You may also need to take care of giving the correct path for clang and
clang++, like CC=/path/to/clang CXX=/path/to/clang++ if the non-systems
clang does not come first in your path.
Full configuration step that was tested on macOS with brew installed llvm:
$ cmake --preset=libfuzzer \
-DCMAKE_C_COMPILER="$(brew --prefix llvm)/bin/clang" \
-DCMAKE_CXX_COMPILER="$(brew --prefix llvm)/bin/clang++" \
-DAPPEND_LDFLAGS=-Wl,-no_warn_duplicate_libraries
Read the libFuzzer documentation for more information. This libFuzzer tutorial might also be of interest.
Fuzzing Bitcoin Core using afl++
Quickstart guide
To quickly get started fuzzing Bitcoin Core using afl++:
$ git clone https://github.com/bitcoin/bitcoin
$ cd bitcoin/
$ git clone https://github.com/AFLplusplus/AFLplusplus
$ make -C AFLplusplus/ source-only
# If afl-clang-lto is not available, see
# https://github.com/AFLplusplus/AFLplusplus#a-selecting-the-best-afl-compiler-for-instrumenting-the-target
$ cmake -B build_fuzz \
-DCMAKE_C_COMPILER="$(pwd)/AFLplusplus/afl-clang-lto" \
-DCMAKE_CXX_COMPILER="$(pwd)/AFLplusplus/afl-clang-lto++" \
-DBUILD_FOR_FUZZING=ON
$ cmake --build build_fuzz
# For macOS you may need to ignore x86 compilation checks when running "cmake --build". If so,
# try compiling using: AFL_NO_X86=1 cmake --build build_fuzz
$ mkdir -p inputs/ outputs/
$ echo A > inputs/thin-air-input
$ FUZZ=bech32 ./AFLplusplus/afl-fuzz -i inputs/ -o outputs/ -- build_fuzz/src/test/fuzz/fuzz
# You may have to change a few kernel parameters to test optimally - afl-fuzz
# will print an error and suggestion if so.
Read the afl++ documentation for more information.
Fuzzing Bitcoin Core using Honggfuzz
Quickstart guide
To quickly get started fuzzing Bitcoin Core using Honggfuzz:
$ git clone https://github.com/bitcoin/bitcoin
$ cd bitcoin/
$ git clone https://github.com/google/honggfuzz
$ cd honggfuzz/
$ make
$ cd ..
$ cmake -B build_fuzz \
-DCMAKE_C_COMPILER="$(pwd)/honggfuzz/hfuzz_cc/hfuzz-clang" \
-DCMAKE_CXX_COMPILER="$(pwd)/honggfuzz/hfuzz_cc/hfuzz-clang++" \
-DBUILD_FOR_FUZZING=ON \
-DSANITIZERS=address,undefined
$ cmake --build build_fuzz
$ mkdir -p inputs/
$ FUZZ=process_message ./honggfuzz/honggfuzz -i inputs/ -- build_fuzz/src/test/fuzz/fuzz
Read the Honggfuzz documentation for more information.
OSS-Fuzz
Bitcoin Core participates in Google's OSS-Fuzz program, which includes a dashboard of publicly disclosed vulnerabilities.
Bitcoin Core follows its security disclosure policy, which may differ from Google's standard 90-day disclosure window .
OSS-Fuzz also produces a fuzzing coverage report.
Bootstrappable Bitcoin Core Builds
I2P support in Bitcoin Core
It is possible to run Bitcoin Core as an I2P (Invisible Internet Project) service and connect to such services.
This glossary may be useful to get started with I2P terminology.
Run Bitcoin Core with an I2P router (proxy)
A running I2P router (proxy) is required with the SAM application bridge enabled. The following routers are recommended for use with Bitcoin Core:
- i2prouter (I2P Router), the official implementation in
Java. The SAM bridge is not enabled by default; it must be started manually,
or configured to start automatically, in the Clients page in the
router console (
http://127.0.0.1:7657/configclients) or in theclients.configfile. - i2pd (I2P Daemon) (documentation), a lighter alternative in C++. It enables the SAM bridge by default.
Note the IP address and port the SAM proxy is listening to; usually, it is
127.0.0.1:7656.
Once an I2P router with SAM enabled is up and running, use the following Bitcoin Core configuration options:
-i2psam=<ip:port>
I2P SAM proxy to reach I2P peers and accept I2P connections (default:
none)
-i2pacceptincoming
Whether to accept inbound I2P connections (default: 1). Ignored if
-i2psam is not set. Listening for inbound I2P connections is
done through the SAM proxy, not by binding to a local address and
port.
In a typical situation, this suffices:
bitcoind -i2psam=127.0.0.1:7656
Additional configuration options related to I2P
-debug=i2p
Set the debug=i2p config logging option to see additional information in the
debug log about your I2P configuration and connections. Run bitcoin-cli help logging for more information.
-onlynet=i2p
Make automatic outbound connections only to I2P addresses. Inbound and manual connections are not affected by this option. It can be specified multiple times to allow multiple networks, e.g. onlynet=onion, onlynet=i2p.
I2P support was added to Bitcoin Core in version 22.0 and there may be fewer I2P
peers than Tor or IP ones. Therefore, using I2P alone without other networks may
make a node more susceptible to Sybil
attacks. You can use
bitcoin-cli -addrinfo to see the number of I2P addresses known to your node.
Another consideration with onlynet=i2p is that the initial blocks download
phase when syncing up a new node can be very slow. This phase can be sped up by
using other networks, for instance onlynet=onion, at the same time.
In general, a node can be run with both onion and I2P hidden services (or any/all of IPv4/IPv6/onion/I2P/CJDNS), which can provide a potential fallback if one of the networks has issues.
Persistent vs transient I2P addresses
The first time Bitcoin Core connects to the I2P router, it automatically
generates a persistent I2P address and its corresponding private key by default,
unless -i2pacceptincoming=0 is set. The private key is saved in a file named
i2p_private_key in the Bitcoin Core data directory. The persistent I2P
address is used for making outbound connections and accepting inbound
connections.
In the I2P network, the receiver of an inbound connection sees the address of the initiator. This is unlike the Tor network, where the recipient does not know who is connecting to it.
If your node is configured by setting -i2pacceptincoming=0 to not accept
inbound I2P connections, then it will use a random transient I2P address for
itself on each outbound connection to make it harder to discriminate,
fingerprint or analyze it based on its I2P address.
I2P addresses are designed to be long-lived. Waiting for tunnels to be built for every peer connection adds delay to connection setup time. Therefore, I2P listening should only be turned off if really needed.
Fetching I2P-related information from Bitcoin Core
There are several ways to see your I2P address in Bitcoin Core if accepting
incoming I2P connections (-i2pacceptincoming):
- in the "Local addresses" output of CLI
-netinfo - in the "localaddresses" output of RPC
getnetworkinfo - in the debug log (grep for
AddLocal; the I2P address ends in.b32.i2p)
To see which I2P peers your node is connected to, use bitcoin-cli -netinfo 4
or the getpeerinfo RPC (e.g. bitcoin-cli getpeerinfo).
You can use the getnodeaddresses RPC to fetch a number of I2P peers known to your node; run bitcoin-cli help getnodeaddresses for details.
Compatibility
Bitcoin Core uses the SAM v3.1 protocol to connect to the I2P network. Any I2P router that supports it can be used.
Ports in I2P and Bitcoin Core
One particularity of SAM v3.1 is that it does not support ports, unlike newer versions of SAM (v3.2 and up) that do support them and default the port numbers to 0. From the point of view of peers that use newer versions of SAM or other protocols that support ports, a SAM v3.1 peer is connecting to them on port 0, from source port 0.
To allow future upgrades to newer versions of SAM, Bitcoin Core sets its
listening port to 0 when listening for incoming I2P connections and advertises
its own I2P address with port 0. Furthermore, it will not attempt to connect to
I2P addresses with a non-zero port number because with SAM v3.1 the destination
port (TO_PORT) is always set to 0 and is not in the control of Bitcoin Core.
Bandwidth
By default, your node shares bandwidth and transit tunnels with the I2P network in order to increase your anonymity with cover traffic, help the I2P router used by your node integrate optimally with the network, and give back to the network. It's important that the nodes of a popular application like Bitcoin contribute as much to the I2P network as they consume.
It is possible, though strongly discouraged, to change your I2P router configuration to limit the amount of I2P traffic relayed by your node.
With i2pd, this can be done by adjusting the bandwidth, share and
transittunnels options in your i2pd.conf file. For example, to limit total
I2P traffic to 256KB/s and share 50% of this limit for a maximum of 20 transit
tunnels:
bandwidth = 256
share = 50
[limits]
transittunnels = 20
Similar bandwidth configuration options for the Java I2P router can be found in
http://127.0.0.1:7657/config under the "Bandwidth" tab.
Before doing this, please see the "Participating Traffic Considerations" section in Embedding I2P in your Application.
In most cases, the default router settings should work fine.
Bundling I2P in a Bitcoin application
Please see the "General Guidance for Developers" section in https://geti2p.net/en/docs/api/samv3 if you are developing a downstream application that may be bundling I2P with Bitcoin.
Sample init scripts and service configuration for bitcoind
Sample scripts and configuration files for systemd, Upstart and OpenRC can be found in the contrib/init folder.
contrib/init/bitcoind.service: systemd service unit configuration
contrib/init/bitcoind.openrc: OpenRC compatible SysV style init script
contrib/init/bitcoind.openrcconf: OpenRC conf.d file
contrib/init/bitcoind.conf: Upstart service configuration file
contrib/init/bitcoind.init: CentOS compatible SysV style init script
Service User
All three Linux startup configurations assume the existence of a "bitcoin" user and group. They must be created before attempting to use these scripts. The macOS configuration assumes bitcoind will be set up for the current user.
Configuration
Running bitcoind as a daemon does not require any manual configuration. You may
set the rpcauth setting in the bitcoin.conf configuration file to override
the default behaviour of using a special cookie for authentication.
This password does not have to be remembered or typed as it is mostly used as a fixed token that bitcoind and client programs read from the configuration file, however it is recommended that a strong and secure password be used as this password is security critical to securing the wallet should the wallet be enabled.
If bitcoind is run with the "-server" flag (set by default), and no rpcpassword is set, it will use a special cookie file for authentication. The cookie is generated with random content when the daemon starts, and deleted when it exits. Read access to this file controls who can access it through RPC.
By default the cookie is stored in the data directory, but its location can be
overridden with the option -rpccookiefile. Default file permissions for the
cookie are "owner" (i.e. user read/writeable) via default application-wide file
umask of 0077, but these can be overridden with the -rpccookieperms option.
This allows for running bitcoind without having to do any manual configuration.
conf, pid, and wallet accept relative paths which are interpreted as
relative to the data directory. wallet only supports relative paths.
To generate an example configuration file that describes the configuration settings, see contrib/devtools/README.md.
Paths
Linux
All three configurations assume several paths that might need to be adjusted.
Binary: /usr/bin/bitcoind
Configuration file: /etc/bitcoin/bitcoin.conf
Data directory: /var/lib/bitcoind
PID file: /var/run/bitcoind/bitcoind.pid (OpenRC and Upstart) or
/run/bitcoind/bitcoind.pid (systemd)
Lock file: /var/lock/subsys/bitcoind (CentOS)
The PID directory (if applicable) and data directory should both be owned by the bitcoin user and group. It is advised for security reasons to make the configuration file and data directory only readable by the bitcoin user and group. Access to bitcoin-cli and other bitcoind rpc clients can then be controlled by group membership.
NOTE: When using the systemd .service file, the creation of the aforementioned directories and the setting of their permissions is automatically handled by systemd. Directories are given a permission of 710, giving the bitcoin group access to files under it if the files themselves give permission to the bitcoin group to do so. This does not allow for the listing of files under the directory.
NOTE: It is not currently possible to override datadir in
/etc/bitcoin/bitcoin.conf with the current systemd, OpenRC, and Upstart init
files out-of-the-box. This is because the command line options specified in the
init files take precedence over the configurations in
/etc/bitcoin/bitcoin.conf. However, some init systems have their own
configuration mechanisms that would allow for overriding the command line
options specified in the init files (e.g. setting BITCOIND_DATADIR for
OpenRC).
macOS
Binary: /usr/local/bin/bitcoind
Configuration file: ~/Library/Application Support/Bitcoin/bitcoin.conf
Data directory: ~/Library/Application Support/Bitcoin
Lock file: ~/Library/Application Support/Bitcoin/.lock
Installing Service Configuration
systemd
Installing this .service file consists of just copying it to
/usr/lib/systemd/system directory, followed by the command
systemctl daemon-reload in order to update running systemd configuration.
To test, run systemctl start bitcoind and to enable for system startup run
systemctl enable bitcoind
NOTE: When installing for systemd in Debian/Ubuntu the .service file needs to be copied to the /lib/systemd/system directory instead.
OpenRC
Rename bitcoind.openrc to bitcoind and drop it in /etc/init.d. Double
check ownership and permissions and make it executable. Test it with
/etc/init.d/bitcoind start and configure it to run on startup with
rc-update add bitcoind
Upstart (for Debian/Ubuntu based distributions)
Upstart is the default init system for Debian/Ubuntu versions older than 15.04. If you are using version 15.04 or newer and haven't manually configured upstart you should follow the systemd instructions instead.
Drop bitcoind.conf in /etc/init. Test by running service bitcoind start
it will automatically start on reboot.
NOTE: This script is incompatible with CentOS 5 and Amazon Linux 2014 as they use old versions of Upstart and do not supply the start-stop-daemon utility.
CentOS
Copy bitcoind.init to /etc/init.d/bitcoind. Test by running service bitcoind start.
Using this script, you can adjust the path and flags to the bitcoind program by setting the BITCOIND and FLAGS environment variables in the file /etc/sysconfig/bitcoind. You can also use the DAEMONOPTS environment variable here.
macOS
Copy org.bitcoin.bitcoind.plist into ~/Library/LaunchAgents. Load the launch agent by
running launchctl load ~/Library/LaunchAgents/org.bitcoin.bitcoind.plist.
This Launch Agent will cause bitcoind to start whenever the user logs in.
NOTE: This approach is intended for those wanting to run bitcoind as the current user. You will need to modify org.bitcoin.bitcoind.plist if you intend to use it as a Launch Daemon with a dedicated bitcoin user.
Auto-respawn
Auto respawning is currently only configured for Upstart and systemd. Reasonable defaults have been chosen but YMMV.
Managing the Wallet
1. Backing Up and Restoring The Wallet
1.1 Creating the Wallet
Since version 0.21, Bitcoin Core no longer has a default wallet.
Wallets can be created with the createwallet RPC or with the Create wallet GUI menu item.
In the GUI, the Create a new wallet button is displayed on the main screen when there is no wallet loaded. Alternatively, there is the option File ->Create wallet.
The following command, for example, creates a descriptor wallet. More information about this command may be found by running bitcoin-cli help createwallet.
$ bitcoin-cli createwallet "wallet-01"
By default, wallets are created in the wallets folder of the data directory, which varies by operating system, as shown below. The user can change the default by using the -datadir or -walletdir initialization parameters.
| Operating System | Default wallet directory |
|---|---|
| Linux | /home/<user>/.bitcoin/wallets |
| Windows | C:\Users\<user>\AppData\Local\Bitcoin\wallets |
| macOS | /Users/<user>/Library/Application Support/Bitcoin/wallets |
1.2 Encrypting the Wallet
The wallet.dat file is not encrypted by default and is, therefore, vulnerable if an attacker gains access to the device where the wallet or the backups are stored.
Wallet encryption may prevent unauthorized access. However, this significantly increases the risk of losing coins due to forgotten passphrases. There is no way to recover a passphrase. This tradeoff should be well thought out by the user.
Wallet encryption may also not protect against more sophisticated attacks. An attacker can, for example, obtain the password by installing a keylogger on the user's machine.
After encrypting the wallet or changing the passphrase, a new backup needs to be created immediately. The reason is that the keypool is flushed and a new HD seed is generated after encryption. Any bitcoins received by the new seed cannot be recovered from the previous backups.
The wallet's private key may be encrypted with the following command:
$ bitcoin-cli -rpcwallet="wallet-01" encryptwallet "passphrase"
Once encrypted, the passphrase can be changed with the walletpassphrasechange command.
$ bitcoin-cli -rpcwallet="wallet-01" walletpassphrasechange "oldpassphrase" "newpassphrase"
The argument passed to -rpcwallet is the name of the wallet to be encrypted.
Only the wallet's private key is encrypted. All other wallet information, such as transactions, is still visible.
The wallet's private key can also be encrypted in the createwallet command via the passphrase argument:
$ bitcoin-cli -named createwallet wallet_name="wallet-01" passphrase="passphrase"
Note that if the passphrase is lost, all the coins in the wallet will also be lost forever.
1.3 Unlocking the Wallet
If the wallet is encrypted and the user tries any operation related to private keys, such as sending bitcoins, an error message will be displayed.
$ bitcoin-cli -rpcwallet="wallet-01" sendtoaddress "tb1qw508d6qejxtdg4y5r3zarvary0c5xw7kxpjzsx" 0.01
error code: -13
error message:
Error: Please enter the wallet passphrase with walletpassphrase first.
To unlock the wallet and allow it to run these operations, the walletpassphrase RPC is required.
This command takes the passphrase and an argument called timeout, which specifies the time in seconds that the wallet decryption key is stored in memory. After this period expires, the user needs to execute this RPC again.
$ bitcoin-cli -rpcwallet="wallet-01" walletpassphrase "passphrase" 120
In the GUI, there is no specific menu item to unlock the wallet. When the user sends bitcoins, the passphrase will be prompted automatically.
1.4 Backing Up the Wallet
To backup the wallet, the backupwallet RPC or the Backup Wallet GUI menu item must be used to ensure the file is in a safe state when the copy is made.
In the RPC, the destination parameter must include the name of the file. Otherwise, the command will return an error message like "Error: Wallet backup failed!" for descriptor wallets. If it is a legacy wallet, it will be copied and a file will be created with the default file name wallet.dat.
$ bitcoin-cli -rpcwallet="wallet-01" backupwallet /home/node01/Backups/backup-01.dat
In the GUI, the wallet is selected in the Wallet drop-down list in the upper right corner. If this list is not present, the wallet can be loaded in File ->Open Wallet if necessary. Then, the backup can be done in File -> Backup Wallet….
This backup file can be stored on one or multiple offline devices, which must be reliable enough to work in an emergency and be malware free. Backup files can be regularly tested to avoid problems in the future.
If the computer has malware, it can compromise the wallet when recovering the backup file. One way to minimize this is to not connect the backup to an online device.
If both the wallet and all backups are lost for any reason, the bitcoins related to this wallet will become permanently inaccessible.
1.5 Backup Frequency
The original Bitcoin Core wallet was a collection of unrelated private keys. If a non-HD wallet had received funds to an address and then was restored from a backup made before the address was generated, then any funds sent to that address would have been lost because there was no deterministic mechanism to derive the address again.
Bitcoin Core version 0.13 introduced HD wallets with deterministic key derivation. With HD wallets, users no longer lose funds when restoring old backups because all addresses are derived from the HD wallet seed.
This means that a single backup is enough to recover the coins at any time. It is still recommended to make regular backups (once a week) or after a significant number of new transactions to maintain the metadata, such as labels. Metadata cannot be retrieved from a blockchain rescan, so if the backup is too old, the metadata will be lost forever.
Wallets created before version 0.13 are not HD and must be backed up every 100 keys used since the previous backup, or even more often to maintain the metadata.
1.6 Restoring the Wallet From a Backup
To restore a wallet, the restorewallet RPC or the Restore Wallet GUI menu item (File -> Restore Wallet…) must be used.
$ bitcoin-cli restorewallet "restored-wallet" /home/node01/Backups/backup-01.dat
After that, getwalletinfo can be used to check if the wallet has been fully restored.
$ bitcoin-cli -rpcwallet="restored-wallet" getwalletinfo
The restored wallet can also be loaded in the GUI via File ->Open wallet.
Wallet Passphrase
Understanding wallet security is crucial for safely storing your Bitcoin. A key aspect is the wallet passphrase, used for encryption. Let's explore its nuances, role, encryption process, and limitations.
-
Not the Seed: The wallet passphrase and the seed are two separate components in wallet security. The seed, or HD seed, functions as a master key for deriving private and public keys in a hierarchical deterministic (HD) wallet. In contrast, the passphrase serves as an additional layer of security specifically designed to secure the private keys within the wallet. The passphrase serves as a safeguard, demanding an additional layer of authentication to access funds in the wallet.
-
Protection Against Unauthorized Access: The passphrase serves as a protective measure, securing your funds in situations where an unauthorized user gains access to your unlocked computer or device while your wallet application is active. Without the passphrase, they would be unable to access your wallet's funds or execute transactions. However, it's essential to be aware that someone with access can potentially compromise the security of your passphrase by installing a keylogger.
-
Doesn't Encrypt Metadata or Public Keys: It's important to note that the passphrase primarily secures the private keys and access to funds within the wallet. It does not encrypt metadata associated with transactions or public keys. Information about your transaction history and the public keys involved may still be visible.
-
Risk of Fund Loss if Forgotten or Lost: If the wallet passphrase is too complex and is subsequently forgotten or lost, there is a risk of losing access to the funds permanently. A forgotten passphrase will result in the inability to unlock the wallet and access the funds.
Migrating Legacy Wallets to Descriptor Wallets
Legacy wallets (traditional non-descriptor wallets) can be migrated to become Descriptor wallets
through the use of the migratewallet RPC. Migrated wallets will have all of their addresses and private keys added to
a newly created Descriptor wallet that has the same name as the original wallet. Because Descriptor
wallets do not support having private keys and watch-only scripts, there may be up to two
additional wallets created after migration. In addition to a descriptor wallet of the same name,
there may also be a wallet named <name>_watchonly and <name>_solvables. <name>_watchonly
contains all of the watchonly scripts. <name>_solvables contains any scripts which the wallet
knows but is not watching the corresponding P2(W)SH scripts.
Migrated wallets will also generate new addresses differently. While the same BIP 32 seed will be used, the BIP 44, 49, 84, and 86 standard derivation paths will be used. After migrating, a new backup of the wallet(s) will need to be created.
Given that there is an extremely large number of possible configurations for the scripts that
Legacy wallets can know about, be watching for, and be able to sign for, migratewallet only
makes a best effort attempt to capture all of these things into Descriptor wallets. There may be
unforeseen configurations which result in some scripts being excluded. If a migration fails
unexpectedly or otherwise misses any scripts, please create an issue on GitHub. A backup of the
original wallet can be found in the wallet directory with the name <name>-<timestamp>.legacy.bak.
The backup can be restored using the methods discussed in the Restoring the Wallet From a Backup section.
Multiprocess Bitcoin
This document describes usage of the multiprocess feature. For design information, see the design/multiprocess.md file.
Build Option
On Unix systems, the -DWITH_MULTIPROCESS=ON build option can be passed to build the supplemental bitcoin-node and bitcoin-gui multiprocess executables.
Debugging
The -debug=ipc command line option can be used to see requests and responses between processes.
Installation
The multiprocess feature requires Cap'n Proto and libmultiprocess as dependencies. A simple way to get started using it without installing these dependencies manually is to use the depends system with the MULTIPROCESS=1 dependency option passed to make:
cd <BITCOIN_SOURCE_DIRECTORY>
make -C depends NO_QT=1 MULTIPROCESS=1
# Set host platform to output of gcc -dumpmachine or clang -dumpmachine or check the depends/ directory for the generated subdirectory name
HOST_PLATFORM="x86_64-pc-linux-gnu"
cmake -B build --toolchain=depends/$HOST_PLATFORM/toolchain.cmake
cmake --build build
build/src/bitcoin-node -regtest -printtoconsole -debug=ipc
BITCOIND=$(pwd)/build/src/bitcoin-node build/test/functional/test_runner.py
The cmake build will pick up settings and library locations from the depends directory, so there is no need to pass -DWITH_MULTIPROCESS=ON as a separate flag when using the depends system (it's controlled by the MULTIPROCESS=1 option).
Alternately, you can install Cap'n Proto and libmultiprocess packages on your system, and just run cmake -B build -DWITH_MULTIPROCESS=ON without using the depends system. The cmake build will be able to locate the installed packages via pkg-config. See Installation section of the libmultiprocess readme for install steps. See build-unix.md and build-osx.md for information about installing dependencies in general.
Usage
bitcoin-node is a drop-in replacement for bitcoind, and bitcoin-gui is a drop-in replacement for bitcoin-qt, and there are no differences in use or external behavior between the new and old executables. But internally after #10102, bitcoin-gui will spawn a bitcoin-node process to run P2P and RPC code, communicating with it across a socket pair, and bitcoin-node will spawn bitcoin-wallet to run wallet code, also communicating over a socket pair. This will let node, wallet, and GUI code run in separate address spaces for better isolation, and allow future improvements like being able to start and stop components independently on different machines and environments.
#19460 also adds a new bitcoin-node -ipcbind option and an bitcoind-wallet -ipcconnect option to allow new wallet processes to connect to an existing node process.
And #19461 adds a new bitcoin-gui -ipcconnect option to allow new GUI processes to connect to an existing node process.
1. Multisig Tutorial
Currently, it is possible to create a multisig wallet using Bitcoin Core only.
Although there is already a brief explanation about the multisig in the Descriptors documentation, this tutorial proposes to use the signet (instead of regtest), bringing the reader closer to a real environment and explaining some functions in more detail.
This tutorial uses jq JSON processor to process the results from RPC and stores the relevant values in bash variables. This makes the tutorial reproducible and easier to follow step by step.
Before starting this tutorial, start the bitcoin node on the signet network.
./build/src/bitcoind -signet -daemon
This tutorial also uses the default WPKH derivation path to get the xpubs and does not conform to BIP 45 or BIP 87.
At the time of writing, there is no way to extract a specific path from wallets in Bitcoin Core. For this, an external signer/xpub can be used.
1.1 Basic Multisig Workflow
1.1 Create the Descriptor Wallets
For a 2-of-3 multisig, create 3 descriptor wallets. It is important that they are of the descriptor type in order to retrieve the wallet descriptors. These wallets contain HD seed and private keys, which will be used to sign the PSBTs and derive the xpub.
These three wallets should not be used directly for privacy reasons (public key reuse). They should only be used to sign transactions for the (watch-only) multisig wallet.
for ((n=1;n<=3;n++))
do
./build/src/bitcoin-cli -signet createwallet "participant_${n}"
done
Extract the xpub of each wallet. To do this, the listdescriptors RPC is used. By default, Bitcoin Core single-sig wallets are created using path m/44'/1'/0' for PKH, m/84'/1'/0' for WPKH, m/49'/1'/0' for P2WPKH-nested-in-P2SH and m/86'/1'/0' for P2TR based accounts. Each of them uses the chain 0 for external addresses and chain 1 for internal ones, as shown in the example below.
wpkh([1004658e/84'/1'/0']tpubDCBEcmVKbfC9KfdydyLbJ2gfNL88grZu1XcWSW9ytTM6fitvaRmVyr8Ddf7SjZ2ZfMx9RicjYAXhuh3fmLiVLPodPEqnQQURUfrBKiiVZc8/0/*)#g8l47ngv
wpkh([1004658e/84'/1'/0']tpubDCBEcmVKbfC9KfdydyLbJ2gfNL88grZu1XcWSW9ytTM6fitvaRmVyr8Ddf7SjZ2ZfMx9RicjYAXhuh3fmLiVLPodPEqnQQURUfrBKiiVZc8/1/*)#en65rxc5
The suffix (after #) is the checksum. Descriptors can optionally be suffixed with a checksum to protect against typos or copy-paste errors. All RPCs in Bitcoin Core will include the checksum in their output.
declare -A xpubs
for ((n=1;n<=3;n++))
do
xpubs["internal_xpub_${n}"]=$(./build/src/bitcoin-cli -signet -rpcwallet="participant_${n}" listdescriptors | jq '.descriptors | [.[] | select(.desc | startswith("wpkh") and contains("/1/*"))][0] | .desc' | grep -Po '(?<=\().*(?=\))')
xpubs["external_xpub_${n}"]=$(./build/src/bitcoin-cli -signet -rpcwallet="participant_${n}" listdescriptors | jq '.descriptors | [.[] | select(.desc | startswith("wpkh") and contains("/0/*") )][0] | .desc' | grep -Po '(?<=\().*(?=\))')
done
jq is used to extract the xpub from the wpkh descriptor.
The following command can be used to verify if the xpub was generated correctly.
for x in "${!xpubs[@]}"; do printf "[%s]=%s\n" "$x" "${xpubs[$x]}" ; done
As previously mentioned, this step extracts the m/84'/1'/0' account instead of the path defined in BIP 45 or BIP 87, since there is no way to extract a specific path in Bitcoin Core at the time of writing.
1.2 Define the Multisig Descriptors
Define the external and internal multisig descriptors, add the checksum and then, join both in a JSON array.
external_desc="wsh(sortedmulti(2,${xpubs["external_xpub_1"]},${xpubs["external_xpub_2"]},${xpubs["external_xpub_3"]}))"
internal_desc="wsh(sortedmulti(2,${xpubs["internal_xpub_1"]},${xpubs["internal_xpub_2"]},${xpubs["internal_xpub_3"]}))"
external_desc_sum=$(./build/src/bitcoin-cli -signet getdescriptorinfo $external_desc | jq '.descriptor')
internal_desc_sum=$(./build/src/bitcoin-cli -signet getdescriptorinfo $internal_desc | jq '.descriptor')
multisig_ext_desc="{\"desc\": $external_desc_sum, \"active\": true, \"internal\": false, \"timestamp\": \"now\"}"
multisig_int_desc="{\"desc\": $internal_desc_sum, \"active\": true, \"internal\": true, \"timestamp\": \"now\"}"
multisig_desc="[$multisig_ext_desc, $multisig_int_desc]"
external_desc and internal_desc specify the output type (wsh, in this case) and the xpubs involved. They also use BIP 67 (sortedmulti), so the wallet can be recreated without worrying about the order of xpubs. Conceptually, descriptors describe a list of scriptPubKey (along with information for spending from it) [source].
Note that at least two descriptors are usually used, one for internal derivation paths and one for external ones. There are discussions about eliminating this redundancy, as can be seen in the issue #17190.
After creating the descriptors, it is necessary to add the checksum, which is required by the importdescriptors RPC.
The checksum for a descriptor without one can be computed using the getdescriptorinfo RPC. The response has the descriptor field, which is the descriptor with the checksum added.
There are other fields that can be added to the descriptors:
active: Sets the descriptor to be the active one for the corresponding output type (wsh, in this case).internal: Indicates whether matching outputs should be treated as something other than incoming payments (e.g. change).timestamp: Sets the time from which to start rescanning the blockchain for the descriptor, in UNIX epoch time.
Documentation for these and other parameters can be found by typing ./build/src/bitcoin-cli help importdescriptors.
multisig_desc concatenates external and internal descriptors in a JSON array and then it will be used to create the multisig wallet.
1.3 Create the Multisig Wallet
To create the multisig wallet, first create an empty one (no keys, HD seed and private keys disabled).
Then import the descriptors created in the previous step using the importdescriptors RPC.
After that, getwalletinfo can be used to check if the wallet was created successfully.
./build/src/bitcoin-cli -signet -named createwallet wallet_name="multisig_wallet_01" disable_private_keys=true blank=true
./build/src/bitcoin-cli -signet -rpcwallet="multisig_wallet_01" importdescriptors "$multisig_desc"
./build/src/bitcoin-cli -signet -rpcwallet="multisig_wallet_01" getwalletinfo
Once the wallets have already been created and this tutorial needs to be repeated or resumed, it is not necessary to recreate them, just load them with the command below:
for ((n=1;n<=3;n++)); do ./build/src/bitcoin-cli -signet loadwallet "participant_${n}"; done
1.4 Fund the wallet
The wallet can receive signet coins by generating a new address and passing it as parameters to getcoins.py script.
This script will print a captcha in dot-matrix to the terminal, using unicode Braille characters. After solving the captcha, the coins will be sent directly to the address or wallet (according to the parameters).
The url used by the script can also be accessed directly. At time of writing, the url is https://signetfaucet.com.
Coins received by the wallet must have at least 1 confirmation before they can be spent. It is necessary to wait for a new block to be mined before continuing.
receiving_address=$(./build/src/bitcoin-cli -signet -rpcwallet="multisig_wallet_01" getnewaddress)
./contrib/signet/getcoins.py -c ./build/src/bitcoin-cli -a $receiving_address
To copy the receiving address onto the clipboard, use the following command. This can be useful when getting coins via the signet faucet mentioned above.
echo -n "$receiving_address" | xclip -sel clip
The getbalances RPC may be used to check the balance. Coins with trusted status can be spent.
./build/src/bitcoin-cli -signet -rpcwallet="multisig_wallet_01" getbalances
1.5 Create a PSBT
Unlike singlesig wallets, multisig wallets cannot create and sign transactions directly because they require the signatures of the co-signers. Instead they create a Partially Signed Bitcoin Transaction (PSBT).
PSBT is a data format that allows wallets and other tools to exchange information about a Bitcoin transaction and the signatures necessary to complete it. [source]
The current PSBT version (v0) is defined in BIP 174.
For simplicity, the destination address is taken from the participant_1 wallet in the code above, but it can be any valid bitcoin address.
The walletcreatefundedpsbt RPC is used to create and fund a transaction in the PSBT format. It is the first step in creating the PSBT.
balance=$(./build/src/bitcoin-cli -signet -rpcwallet="multisig_wallet_01" getbalance)
amount=$(echo "$balance * 0.8" | bc -l | sed -e 's/^\./0./' -e 's/^-\./-0./')
destination_addr=$(./build/src/bitcoin-cli -signet -rpcwallet="participant_1" getnewaddress)
funded_psbt=$(./build/src/bitcoin-cli -signet -named -rpcwallet="multisig_wallet_01" walletcreatefundedpsbt outputs="{\"$destination_addr\": $amount}" | jq -r '.psbt')
There is also the createpsbt RPC, which serves the same purpose, but it has no access to the wallet or to the UTXO set. It is functionally the same as createrawtransaction and just drops the raw transaction into an otherwise blank PSBT. [source] In most cases, walletcreatefundedpsbt solves the problem.
The send RPC can also return a PSBT if more signatures are needed to sign the transaction.
1.6 Decode or Analyze the PSBT
Optionally, the PSBT can be decoded to a JSON format using decodepsbt RPC.
The analyzepsbt RPC analyzes and provides information about the current status of a PSBT and its inputs, e.g. missing signatures.
./build/src/bitcoin-cli -signet decodepsbt $funded_psbt
./build/src/bitcoin-cli -signet analyzepsbt $funded_psbt
1.7 Update the PSBT
In the code above, two PSBTs are created. One signed by participant_1 wallet and other, by the participant_2 wallet.
The walletprocesspsbt is used by the wallet to sign a PSBT.
psbt_1=$(./build/src/bitcoin-cli -signet -rpcwallet="participant_1" walletprocesspsbt $funded_psbt | jq '.psbt')
psbt_2=$(./build/src/bitcoin-cli -signet -rpcwallet="participant_2" walletprocesspsbt $funded_psbt | jq '.psbt')
1.8 Combine the PSBT
The PSBT, if signed separately by the co-signers, must be combined into one transaction before being finalized. This is done by combinepsbt RPC.
combined_psbt=$(./build/src/bitcoin-cli -signet combinepsbt "[$psbt_1, $psbt_2]")
There is an RPC called joinpsbts, but it has a different purpose than combinepsbt. joinpsbts joins the inputs from multiple distinct PSBTs into one PSBT.
In the example above, the PSBTs are the same, but signed by different participants. If the user tries to merge them using joinpsbts, the error Input txid:pos exists in multiple PSBTs is returned. To be able to merge different PSBTs into one, they must have different inputs and outputs.
1.9 Finalize and Broadcast the PSBT
The finalizepsbt RPC is used to produce a network serialized transaction which can be broadcast with sendrawtransaction.
It checks that all inputs have complete scriptSigs and scriptWitnesses and, if so, encodes them into network serialized transactions.
finalized_psbt_hex=$(./build/src/bitcoin-cli -signet finalizepsbt $combined_psbt | jq -r '.hex')
./build/src/bitcoin-cli -signet sendrawtransaction $finalized_psbt_hex
1.10 Alternative Workflow (PSBT sequential signatures)
Instead of each wallet signing the original PSBT and combining them later, the wallets can also sign the PSBTs sequentially. This is less scalable than the previously presented parallel workflow, but it works.
After that, the rest of the process is the same: the PSBT is finalized and transmitted to the network.
psbt_1=$(./build/src/bitcoin-cli -signet -rpcwallet="participant_1" walletprocesspsbt $funded_psbt | jq -r '.psbt')
psbt_2=$(./build/src/bitcoin-cli -signet -rpcwallet="participant_2" walletprocesspsbt $psbt_1 | jq -r '.psbt')
finalized_psbt_hex=$(./build/src/bitcoin-cli -signet finalizepsbt $psbt_2 | jq -r '.hex')
./build/src/bitcoin-cli -signet sendrawtransaction $finalized_psbt_hex
Offline Signing Tutorial
This tutorial will describe how to use two instances of Bitcoin Core, one online and one offline, to greatly increase security by not having private keys reside on a networked device.
Maintaining an air-gap between private keys and any network connections drastically reduces the opportunity for those keys to be exfiltrated from the user.
This workflow uses Partially Signed Bitcoin Transactions (PSBTs) to transfer the transaction to and from the offline wallet for signing using the private keys.
[!NOTE] While this tutorial demonstrates the process using
signetnetwork, you should omit the-signetflag in the provided commands when working withmainnet.
Overview
In this tutorial we have two hosts, both running Bitcoin v25.0
offlinehost which is disconnected from all networks (internet, Tor, wifi, bluetooth etc.) and does not have, or need, a copy of the blockchain.onlinehost which is a regular online node with a synced blockchain.
We are going to first create an offline_wallet on the offline host. We will then create a watch_only_wallet on the online host using public key descriptors exported from the offline_wallet. Next we will receive some coins into the wallet. In order to spend these coins we'll create an unsigned PSBT using the watch_only_wallet, sign the PSBT using the private keys in the offline_wallet, and finally broadcast the signed PSBT using the online host.
Requirements
- jq installation - This tutorial uses jq to process certain fields from JSON RPC responses, but this convenience is optional.
Create and Prepare the offline_wallet
- On the offline machine create a wallet named
offline_walletsecured by a walletpassphrase. This wallet will contain private keys and must remain unconnected to any networks at all times.
[offline]$ ./build/src/bitcoin-cli -signet -named createwallet \
wallet_name="offline_wallet" \
passphrase="** enter passphrase **"
{
"name": "offline_wallet"
}
[!NOTE] The use of a passphrase is crucial to encrypt the wallet.dat file. This encryption ensures that even if an unauthorized individual gains access to the offline host, they won't be able to access the wallet's contents. Further details about securing your wallet can be found in Managing the Wallet
- Export the public key-only descriptors from the offline host to a JSON file named
descriptors.json. We usejqhere to extract the.descriptorsfield from the full RPC response.
[offline]$ ./build/src/bitcoin-cli -signet -rpcwallet="offline_wallet" listdescriptors \
| jq -r '.descriptors' \
>> /path/to/descriptors.json
[!NOTE] The
descriptors.jsonfile will be transferred to the online machine (e.g. using a USB flash drive) where it can be imported to create a related watch-only wallet.
Create the online watch_only_wallet
- On the online machine create a blank watch-only wallet which has private keys disabled and is named
watch_only_wallet. This is achieved by using thecreatewalletoptions:disable_private_keys=true, blank=true.
The watch_only_wallet wallet will be used to track and validate incoming transactions, create unsigned PSBTs when spending coins, and broadcast signed and finalized PSBTs.
[!NOTE]
disable_private_keysindicates that the wallet should refuse to import private keys, i.e. will be a dedicated watch-only wallet.
[online]$ ./build/src/bitcoin-cli -signet -named createwallet \
wallet_name="watch_only_wallet" \
disable_private_keys=true \
blank=true
{
"name": "watch_only_wallet"
}
- Import the
offline_wallets public key descriptors to the onlinewatch_only_walletusing thedescriptors.jsonfile created on the offline wallet.
[online]$ ./build/src/bitcoin-cli -signet -rpcwallet="watch_only_wallet" importdescriptors "$(cat /path/to/descriptors.json)"
[
{
"success": true
},
{
"success": true
},
{
"success": true
},
{
"success": true
},
{
"success": true
},
{
"success": true
},
{
"success": true
},
{
"success": true
}
]
[!NOTE] Multiple success values indicate that multiple descriptors, for different address types, have been successfully imported. This allows generating different address types on the
watch_only_wallet.
Fund the offline_wallet
At this point, it's important to understand that both the offline_wallet and online watch_only_wallet share the same public keys. As a result, they generate the same addresses. Transactions can be created using either wallet, but valid signatures can only be added by the offline_wallet as only it has the private keys.
- Generate an address to receive coins. You can use either the
offline_walletor the onlinewatch_only_walletto generate this address, as they will produce the same addresses. For the sake of this guide, we'll use the onlinewatch_only_walletto generate the address.
[online]$ ./build/src/bitcoin-cli -signet -rpcwallet="watch_only_wallet" getnewaddress
tb1qtu5qgc6ddhmqm5yqjvhg83qgk2t4ewajg0h6yh
-
Visit a faucet like https://signetfaucet.com and enter your address from the previous command to receive a small amount of signet coins to this address.
-
Confirm that coins were received using the online
watch_only_wallet. Note that the transaction may take a few moments before being received on your local node, depending on its connectivity. Just re-run the command periodically until the transaction is received.
[online]$ ./build/src/bitcoin-cli -signet -rpcwallet="watch_only_wallet" listunspent
[
{
"txid": "0f3953dfc3eb8e753cd1633151837c5b9953992914ff32b7de08c47f1f29c762",
"vout": 1,
"address": "tb1qtu5qgc6ddhmqm5yqjvhg83qgk2t4ewajg0h6yh",
"label": "",
"scriptPubKey": "00145f2804634d6df60dd080932e83c408b2975cbbb2",
"amount": 0.01000000,
"confirmations": 4,
"spendable": true,
"solvable": true,
"desc": "wpkh([306c734f/84h/1h/0h/0/0]025932ccee7590158f7e08bb36290d135d30a0b045163da896e1cd7645ec4223a9)#xytvyr4a",
"parent_descs": [
"wpkh([306c734f/84h/1h/0h]tpubDCJnY92ib4Zu3qd6wrBXEjG436tQdA2tDiJU2iSJYjkNS1darssPWKaBfojhjUF5vMLBcxbN2r93pmFMz2zyTEZuNx9JDo9rWqoHhATW3Uz/0/*)#7mh08dkg"
],
"safe": true
}
]
Create and Export an Unsigned PSBT
-
Get a destination address for the transaction. In this tutorial we'll be sending funds to the address
tb1q9k5w0nhnhyeh78snpxh0t5t7c3lxdeg3erez32, but if you don't need the coins for further testing you could send the coins back to the faucet. -
Create a funded but unsigned PSBT to the destination address with the online
watch_only_walletby usingsend [{"address":amount},...]and export the unsigned PSBT to a filefunded_psbt.txtfor easy portability to theoffline_walletfor signing:
[online]$ ./build/src/bitcoin-cli -signet -rpcwallet="watch_only_wallet" send \
'{"tb1q9k5w0nhnhyeh78snpxh0t5t7c3lxdeg3erez32": 0.009}' \
| jq -r '.psbt' \
>> /path/to/funded_psbt.txt
[online]$ cat /path/to/funded_psbt.txt
cHNidP8BAHECAAAAAWLHKR9/xAjetzL/FCmZU5lbfINRMWPRPHWO68PfUzkPAQAAAAD9////AoA4AQAAAAAAFgAULajnzvO5M38eEwmu9dF+xH5m5RGs0g0AAAAAABYAFMaT0f/Wp2DCZzL6dkJ3GhWj4Y9vAAAAAAABAHECAAAAAY+dRPEBrGopkw4ugSzS9npzJDEIrE/bq1XXI0KbYnYrAQAAAAD+////ArKaXgAAAAAAFgAUwEc4LdoxSjbWo/2Ue+HS+QjwfiBAQg8AAAAAABYAFF8oBGNNbfYN0ICTLoPECLKXXLuyYW8CAAEBH0BCDwAAAAAAFgAUXygEY01t9g3QgJMug8QIspdcu7IiBgJZMszudZAVj34IuzYpDRNdMKCwRRY9qJbhzXZF7EIjqRgwbHNPVAAAgAEAAIAAAACAAAAAAAAAAAAAACICA7BlBnyAR4F2UkKuSX9MFhYCsn6j//z9i7lHDm1O0CU0GDBsc09UAACAAQAAgAAAAIABAAAAAAAAAAA=
[!NOTE] Leaving the
inputarray empty in the abovewalletcreatefundedpsbtcommand is permitted and will cause the wallet to automatically select appropriate inputs for the transaction.
Decode and Analyze the Unsigned PSBT
Decode and analyze the unsigned PSBT on the offline_wallet using the funded_psbt.txt file:
[offline]$ ./build/src/bitcoin-cli -signet decodepsbt $(cat /path/to/funded_psbt.txt)
{
...
}
[offline]$ ./build/src/bitcoin-cli -signet analyzepsbt $(cat /path/to/funded_psbt.txt)
{
"inputs": [
{
"has_utxo": true,
"is_final": false,
"next": "signer",
"missing": {
"signatures": [
"5f2804634d6df60dd080932e83c408b2975cbbb2"
]
}
}
],
"estimated_vsize": 141,
"estimated_feerate": 0.00100000,
"fee": 0.00014100,
"next": "signer"
}
Notice that the analysis of the PSBT shows that "signatures" are missing and should be provided by the private key corresponding to the public key hash (hash160) "5f2804634d6df60dd080932e83c408b2975cbbb2"
Process and Sign the PSBT
- Unlock the
offline_walletwith the Passphrase:
Use the walletpassphrase command to unlock the offline_wallet with the passphrase. You should specify the passphrase and a timeout (in seconds) for how long you want the wallet to remain unlocked.
[offline]$ ./build/src/bitcoin-cli -signet -rpcwallet="offline_wallet" walletpassphrase "** enter passphrase **" 60
- Process, sign and finalize the PSBT on the
offline_walletusing thewalletprocesspsbtcommand, saving the output to a filefinal_psbt.txt.
[offline]$ ./build/src/bitcoin-cli -signet -rpcwallet="offline_wallet" walletprocesspsbt \
$(cat /path/to/funded_psbt.txt) \
| jq -r .hex \
>> /path/to/final_psbt.txt
Broadcast the Signed and Finalized PSBT
Broadcast the funded, signed and finalized PSBT final_psbt.txt using sendrawtransaction with an online node:
[online]$ ./build/src/bitcoin-cli -signet sendrawtransaction $(cat /path/to/final_psbt.txt)
c2430a0e46df472b04b0ca887bbcd5c4abf7b2ce2eb71de981444a80e2b96d52
Confirm Wallet Balance
Confirm the updated balance of the offline wallet using the watch_only_wallet.
[online]$ ./build/src/bitcoin-cli -signet -rpcwallet="watch_only_wallet" getbalances
{
"mine": {
"trusted": 0.00085900,
"untrusted_pending": 0.00000000,
"immature": 0.00000000
},
"lastprocessedblock": {
"hash": "0000003065c0669fff27edb4a71928cb48e5a6cfcdf06f491a83fd86822d18a6",
"height": 159592
}
}
You can also show transactions related to the wallet using listtransactions
[online]$ ./build/src/bitcoin-cli -signet -rpcwallet="watch_only_wallet" listtransactions
{
...
}
When Bitcoin Core automatically opens outgoing P2P connections, it chooses a peer (address and port) from its list of potential peers. This list is populated with unchecked data gossiped over the P2P network by other peers.
A malicious actor may gossip an address:port where no Bitcoin node is listening, or one where a service is listening that is not related to the Bitcoin network. As a result, this service may occasionally get connection attempts from Bitcoin nodes.
"Bad" ports are ones used by services which are usually not open to the public and usually require authentication. A connection attempt (by Bitcoin Core, trying to connect because it thinks there is a Bitcoin node on that address:port) to such service may be considered a malicious action by an ultra-paranoid administrator. An example for such a port is 22 (ssh). On the other hand, connection attempts to public services that usually do not require authentication are unlikely to be considered a malicious action, e.g. port 80 (http).
Below is a list of "bad" ports which Bitcoin Core avoids when choosing a peer to connect to. If a node is listening on such a port, it will likely receive fewer incoming connections.
1: tcpmux
7: echo
9: discard
11: systat
13: daytime
15: netstat
17: qotd
19: chargen
20: ftp data
21: ftp access
22: ssh
23: telnet
25: smtp
37: time
42: name
43: nicname
53: domain
69: tftp
77: priv-rjs
79: finger
87: ttylink
95: supdup
101: hostname
102: iso-tsap
103: gppitnp
104: acr-nema
109: pop2
110: pop3
111: sunrpc
113: auth
115: sftp
117: uucp-path
119: nntp
123: NTP
135: loc-srv /epmap
137: netbios
139: netbios
143: imap2
161: snmp
179: BGP
389: ldap
427: SLP (Also used by Apple Filing Protocol)
465: smtp+ssl
512: print / exec
513: login
514: shell
515: printer
526: tempo
530: courier
531: chat
532: netnews
540: uucp
548: AFP (Apple Filing Protocol)
554: rtsp
556: remotefs
563: nntp+ssl
587: smtp (rfc6409)
601: syslog-conn (rfc3195)
636: ldap+ssl
989: ftps-data
990: ftps
993: ldap+ssl
995: pop3+ssl
1719: h323gatestat
1720: h323hostcall
1723: pptp
2049: nfs
3659: apple-sasl / PasswordServer
4045: lockd
5060: sip
5061: sips
6000: X11
6566: sane-port
6665: Alternate IRC
6666: Alternate IRC
6667: Standard IRC
6668: Alternate IRC
6669: Alternate IRC
6697: IRC + TLS
10080: Amanda
For further information see:
Productivity Notes
Table of Contents
General
Cache compilations with ccache
The easiest way to faster compile times is to cache compiles. ccache is a way to do so, from its description at the time of writing:
ccache is a compiler cache. It speeds up recompilation by caching the result of previous compilations and detecting when the same compilation is being done again. Supported languages are C, C++, Objective-C and Objective-C++.
Install ccache through your distribution's package manager, and run cmake -B build with your normal configuration options to pick it up.
To use ccache for all your C/C++ projects, follow the symlinks method here to set it up.
To get the most out of ccache, put something like this in ~/.ccache/ccache.conf:
max_size = 50.0G # or whatever cache size you prefer; default is 5G; 0 means unlimited
base_dir = /home/yourname # or wherever you keep your source files
Note: base_dir is required for ccache to share cached compiles of the same file across different repositories / paths; it will only do this for paths under base_dir. So this option is required for effective use of ccache with git worktrees (described below).
You must not set base_dir to "/", or anywhere that contains system headers (according to the ccache docs).
Disable features when generating the build system
During the generation of the build system only essential build options are enabled by default to save on compilation time.
Run cmake -B build -LH to see the full list of available options. GUI tools, such as ccmake and cmake-gui, can be also helpful.
If you do need the wallet enabled (-DENABLE_WALLET=ON), it is common for devs to use your system bdb version for the wallet, so you don't have to find a copy of bdb 4.8. Wallets from such a build will be incompatible with any release binary (and vice versa), so use with caution on mainnet.
Make use of your threads with -j
If you have multiple threads on your machine, you can utilize all of them with:
cmake --build build -j "$(($(nproc)+1))"
Only build what you need
When rebuilding during development, note that running cmake --build build, without giving a target, will do a lot of work you probably don't need. It will build the GUI (if you've enabled it) and all the tests (which take much longer to build than the app does).
Obviously, it is important to build and run the tests at appropriate times -- but when you just want a quick compile to check your work, consider picking one or a set of build targets relevant to what you're working on, e.g.:
cmake --build build --target bitcoind bitcoin-cli
cmake --build build --target bitcoin-qt
cmake --build build --target bench_bitcoin
(You can and should combine this with -j, as above, for a parallel build.)
Compile on multiple machines
If you have more than one computer at your disposal, you can use distcc to speed up compilation. This is easiest when all computers run the same operating system and compiler version.
Multiple working directories with git worktrees
If you work with multiple branches or multiple copies of the repository, you should try git worktrees.
To create a new branch that lives under a new working directory without disrupting your current working directory (useful for creating pull requests):
git worktree add -b my-shiny-new-branch ../living-at-my-new-working-directory based-on-my-crufty-old-commit-ish
To simply check out a commit-ish under a new working directory without disrupting your current working directory (useful for reviewing pull requests):
git worktree add --checkout ../where-my-checkout-commit-ish-will-live my-checkout-commit-ish
Interactive "dummy rebases" for fixups and execs with git merge-base
When rebasing, we often want to do a "dummy rebase," whereby we are not rebasing over an updated master but rather over the last common commit with master. This might be useful for rearranging commits, rebase --autosquashing, or rebase --execing without introducing conflicts that arise from an updated master. In these situations, we can use git merge-base to identify the last common commit with master, and rebase off of that.
To squash in git commit --fixup commits without rebasing over an updated master, we can do the following:
git rebase -i --autosquash "$(git merge-base master HEAD)"
To execute cmake --build build && ctest --test-dir build on every commit since last diverged from master, but without rebasing over an updated master, we can do the following:
git rebase -i --exec "cmake --build build && ctest --test-dir build" "$(git merge-base master HEAD)"
This synergizes well with ccache as objects resulting from unchanged code will most likely hit the cache and won't need to be recompiled.
You can also set up upstream refspecs to refer to pull requests easier in the above git worktree commands.
Writing code
Format C/C++ diffs with clang-format-diff.py
See contrib/devtools/README.md.
Format Python diffs with yapf-diff.py
Usage is exactly the same as clang-format-diff.py. You can get it here.
Rebasing/Merging code
More conflict context with merge.conflictstyle diff3
For resolving merge/rebase conflicts, it can be useful to enable diff3 style using git config merge.conflictstyle diff3. Instead of
<<<
yours
===
theirs
>>>
you will see
<<<
yours
|||
original
===
theirs
>>>
This may make it much clearer what caused the conflict. In this style, you can often just look at what changed between original and theirs, and mechanically apply that to yours (or the other way around).
Reviewing code
Reduce mental load with git diff options
When reviewing patches which change indentation in C++ files, use git diff -w and git show -w. This makes the diff algorithm ignore whitespace changes. This feature is also available on github.com, by adding ?w=1 at the end of any URL which shows a diff.
When reviewing patches that change symbol names in many places, use git diff --word-diff. This will instead of showing the patch as deleted/added lines, show deleted/added words.
When reviewing patches that move code around, try using git diff --patience commit~:old/file.cpp commit:new/file/name.cpp, and ignoring everything except the moved body of code which should show up as neither + or - lines. In case it was not a pure move, this may even work when combined with the -w or --word-diff options described above. --color-moved=dimmed-zebra will also dim the coloring of moved hunks in the diff on compatible terminals.
Reference PRs easily with refspecs
When looking at other's pull requests, it may make sense to add the following section to your .git/config file:
[remote "upstream-pull"]
fetch = +refs/pull/*/head:refs/remotes/upstream-pull/*
url = git@github.com:bitcoin/bitcoin.git
This will add an upstream-pull remote to your git repository, which can be fetched using git fetch --all or git fetch upstream-pull. It will download and store on disk quite a lot of data (all PRs, including merged and closed ones). Afterwards, you can use upstream-pull/NUMBER/head in arguments to git show, git checkout and anywhere a commit id would be acceptable to see the changes from pull request NUMBER.
Diff the diffs with git range-diff
It is very common for contributors to rebase their pull requests, or make changes to commits (perhaps in response to review) that are not at the head of their branch. This poses a problem for reviewers as when the contributor force pushes, the reviewer is no longer sure that his previous reviews of commits are still valid (as the commit hashes can now be different even though the diff is semantically the same). git range-diff (Git >= 2.19) can help solve this problem by diffing the diffs.
For example, to identify the differences between your previously reviewed diffs P1-5, and the new diffs P1-2,N3-4 as illustrated below:
P1--P2--P3--P4--P5 <-- previously-reviewed-head
/
...--m <-- master
\
P1--P2--N3--N4--N5 <-- new-head (with P3 slightly modified)
You can do:
git range-diff master previously-reviewed-head new-head
Note that git range-diff also work for rebases:
P1--P2--P3--P4--P5 <-- previously-reviewed-head
/
...--m--m1--m2--m3 <-- master
\
P1--P2--N3--N4 <-- new-head (with P3 modified, P4 & P5 squashed)
PREV=P5 N=4 && git range-diff `git merge-base --all HEAD $PREV`...$PREV HEAD~$N...HEAD
Where P5 is the commit you last reviewed and 4 is the number of commits in the new version.
git range-diff also accepts normal git diff options, see Reduce mental load with git diff options for useful git diff options.
You can also set up upstream refspecs to refer to pull requests easier in the above git range-diff commands.
PSBT Howto for Bitcoin Core
Since Bitcoin Core 0.17, an RPC interface exists for Partially Signed Bitcoin Transactions (PSBTs, as specified in BIP 174).
This document describes the overall workflow for producing signed transactions through the use of PSBT, and the specific RPC commands used in typical scenarios.
PSBT in general
PSBT is an interchange format for Bitcoin transactions that are not fully signed yet, together with relevant metadata to help entities work towards signing it. It is intended to simplify workflows where multiple parties need to cooperate to produce a transaction. Examples include hardware wallets, multisig setups, and CoinJoin transactions.
Overall workflow
Overall, the construction of a fully signed Bitcoin transaction goes through the following steps:
- A Creator proposes a particular transaction to be created. They construct a PSBT that contains certain inputs and outputs, but no additional metadata.
- For each input, an Updater adds information about the UTXOs being spent by the transaction to the PSBT. They also add information about the scripts and public keys involved in each of the inputs (and possibly outputs) of the PSBT.
- Signers inspect the transaction and its metadata to decide whether they agree with the transaction. They can use amount information from the UTXOs to assess the values and fees involved. If they agree, they produce a partial signature for the inputs for which they have relevant key(s).
- A Finalizer is run for each input to convert the partial signatures and
possibly script information into a final
scriptSigand/orscriptWitness. - An Extractor produces a valid Bitcoin transaction (in network format) from a PSBT for which all inputs are finalized.
Generally, each of the above (excluding Creator and Extractor) will simply add more and more data to a particular PSBT, until all inputs are fully signed. In a naive workflow, they all have to operate sequentially, passing the PSBT from one to the next, until the Extractor can convert it to a real transaction. In order to permit parallel operation, Combiners can be employed which merge metadata from different PSBTs for the same unsigned transaction.
The names above in bold are the names of the roles defined in BIP174. They're useful in understanding the underlying steps, but in practice, software and hardware implementations will typically implement multiple roles simultaneously.
PSBT in Bitcoin Core
RPCs
converttopsbt(Creator) is a utility RPC that converts an unsigned raw transaction to PSBT format. It ignores existing signatures.createpsbt(Creator) is a utility RPC that takes a list of inputs and outputs and converts them to a PSBT with no additional information. It is equivalent to callingcreaterawtransactionfollowed byconverttopsbt.walletcreatefundedpsbt(Creator, Updater) is a wallet RPC that creates a PSBT with the specified inputs and outputs, adds additional inputs and change to it to balance it out, and adds relevant metadata. In particular, for inputs that the wallet knows about (counting towards its normal or watch-only balance), UTXO information will be added. For outputs and inputs with UTXO information present, key and script information will be added which the wallet knows about. It is equivalent to runningcreaterawtransaction, followed byfundrawtransaction, andconverttopsbt.walletprocesspsbt(Updater, Signer, Finalizer) is a wallet RPC that takes as input a PSBT, adds UTXO, key, and script data to inputs and outputs that miss it, and optionally signs inputs. Where possible it also finalizes the partial signatures.descriptorprocesspsbt(Updater, Signer, Finalizer) is a node RPC that takes as input a PSBT and a list of descriptors. It updates SegWit inputs with information available from the UTXO set and the mempool and signs the inputs using the provided descriptors. Where possible it also finalizes the partial signatures.utxoupdatepsbt(Updater) is a node RPC that takes a PSBT and updates it to include information available from the UTXO set (works only for SegWit inputs).finalizepsbt(Finalizer, Extractor) is a utility RPC that finalizes any partial signatures, and if all inputs are finalized, converts the result to a fully signed transaction which can be broadcast withsendrawtransaction.combinepsbt(Combiner) is a utility RPC that implements a Combiner. It can be used at any point in the workflow to merge information added to different versions of the same PSBT. In particular it is useful to combine the output of multiple Updaters or Signers.joinpsbts(Creator) is a utility RPC that joins multiple PSBTs together, concatenating the inputs and outputs. This can be used to construct CoinJoin transactions.decodepsbtis a diagnostic utility RPC which will show all information in a PSBT in human-readable form, as well as compute its eventual fee if known.analyzepsbtis a utility RPC that examines a PSBT and reports the current status of its inputs, the next step in the workflow if known, and if possible, computes the fee of the resulting transaction and estimates the final weight and feerate.
Workflows
Multisig with multiple Bitcoin Core instances
For a quick start see Basic M-of-N multisig example using descriptor wallets and PSBTs. If you are using legacy wallets feel free to continue with the example provided here.
Alice, Bob, and Carol want to create a 2-of-3 multisig address. They're all using
Bitcoin Core. We assume their wallets only contain the multisig funds. In case
they also have a personal wallet, this can be accomplished through the
multiwallet feature - possibly resulting in a need to add -rpcwallet=name to
the command line in case bitcoin-cli is used.
Setup:
- All three call
getnewaddressto create a new address; call these addresses Aalice, Abob, and Acarol. - All three call
getaddressinfo "X", with X their respective address, and remember the corresponding public keys. Call these public keys Kalice, Kbob, and Kcarol. - All three now run
addmultisigaddress 2 ["Kalice","Kbob","Kcarol"]to teach their wallet about the multisig script. Call the address produced by this command Amulti. They may be required to explicitly specify the same addresstype option each, to avoid constructing different versions due to differences in configuration. - They also run
importaddress "Amulti" "" falseto make their wallets treat payments to Amulti as contributing to the watch-only balance. - Others can verify the produced address by running
createmultisig 2 ["Kalice","Kbob","Kcarol"], and expecting Amulti as output. Again, it may be necessary to explicitly specify the addresstype in order to get a result that matches. This command won't enable them to initiate transactions later, however. - They can now give out Amulti as address others can pay to.
Later, when V BTC has been received on Amulti, and Bob and Carol want to move the coins in their entirety to address Asend, with no change. Alice does not need to be involved.
- One of them - let's assume Carol here - initiates the creation. She runs
walletcreatefundedpsbt [] {"Asend":V} 0 {"subtractFeeFromOutputs":[0], "includeWatching":true}. We call the resulting PSBT P. P does not contain any signatures. - Carol needs to sign the transaction herself. In order to do so, she runs
walletprocesspsbt "P", and gives the resulting PSBT P2 to Bob. - Bob inspects the PSBT using
decodepsbt "P2"to determine if the transaction has indeed just the expected input, and an output to Asend, and the fee is reasonable. If he agrees, he callswalletprocesspsbt "P2"to sign. The resulting PSBT P3 contains both Carol's and Bob's signature. - Now anyone can call
finalizepsbt "P3"to extract a fully signed transaction T. - Finally anyone can broadcast the transaction using
sendrawtransaction "T".
In case there are more signers, it may be advantageous to let them all sign in
parallel, rather than passing the PSBT from one signer to the next one. In the
above example this would translate to Carol handing a copy of P to each signer
separately. They can then all invoke walletprocesspsbt "P", and end up with
their individually-signed PSBT structures. They then all send those back to
Carol (or anyone) who can combine them using combinepsbt. The last two steps
(finalizepsbt and sendrawtransaction) remain unchanged.
Reduce Memory
There are a few parameters that can be dialed down to reduce the memory usage of bitcoind. This can be useful on embedded systems or small VPSes.
In-memory caches
The size of some in-memory caches can be reduced. As caches trade off memory usage for performance, reducing these will usually have a negative effect on performance.
-dbcache=<n>- the UTXO database cache size, this defaults to450. The unit is MiB (1024).- The minimum value for
-dbcacheis 4. - A lower
-dbcachemakes initial sync time much longer. After the initial sync, the effect is less pronounced for most use-cases, unless fast validation of blocks is important, such as for mining.
- The minimum value for
Memory pool
-
In Bitcoin Core there is a memory pool limiter which can be configured with
-maxmempool=<n>, where<n>is the size in MB (1000). The default value is300.- The minimum value for
-maxmempoolis 5. - A lower maximum mempool size means that transactions will be evicted sooner. This will affect any uses of
bitcoindthat process unconfirmed transactions.
- The minimum value for
-
Since
0.14.0, unused memory allocated to the mempool (default: 300MB) is shared with the UTXO cache, so when trying to reduce memory usage you should limit the mempool, with the-maxmempoolcommand line argument. -
To disable most of the mempool functionality there is the
-blocksonlyoption. This will reduce the default memory usage to 5MB and make the client opt out of receiving (and thus relaying) transactions, except from peers who have therelaypermission set (e.g. whitelisted peers), and as part of blocks.- Do not use this when using the client to broadcast transactions as any transaction sent will stick out like a sore thumb, affecting privacy. When used with the wallet it should be combined with
-walletbroadcast=0and-spendzeroconfchange=0. Another mechanism for broadcasting outgoing transactions (if any) should be used.
- Do not use this when using the client to broadcast transactions as any transaction sent will stick out like a sore thumb, affecting privacy. When used with the wallet it should be combined with
Number of peers
-
-maxconnections=<n>- the maximum number of connections, which defaults to 125. Each active connection takes up some memory. This option applies only if inbound connections are enabled; otherwise, the number of connections will not be more than 11. Of the 11 outbound peers, there can be 8 full-relay connections, 2 block-relay-only ones, and occasionally 1 short-lived feeler or extra outbound block-relay-only connection. -
These limits do not apply to connections added manually with the
-addnodeconfiguration option or theaddnodeRPC, which have a separate limit of 8 connections.
Thread configuration
For each thread a thread stack needs to be allocated. By default on Linux, threads take up 8MiB for the thread stack on a 64-bit system, and 4MiB in a 32-bit system.
-par=<n>- the number of script verification threads, defaults to the number of cores in the system minus one.-rpcthreads=<n>- the number of threads used for processing RPC requests, defaults to4.
Linux specific
By default, glibc's implementation of malloc may use more than one arena. This is known to cause excessive memory usage in some scenarios. To avoid this, make a script that sets MALLOC_ARENA_MAX before starting bitcoind:
#!/usr/bin/env bash
export MALLOC_ARENA_MAX=1
bitcoind
The behavior was introduced to increase CPU locality of allocated memory and performance with concurrent allocation, so this setting could in theory reduce performance. However, in Bitcoin Core very little parallel allocation happens, so the impact is expected to be small or absent.
Reduce Traffic
Some node operators need to deal with bandwidth caps imposed by their ISPs.
By default, Bitcoin Core allows up to 125 connections to different peers, 11 of which are outbound. You can therefore, have at most 114 inbound connections. Of the 11 outbound peers, there can be 8 full-relay connections, 2 block-relay-only ones and occasionally 1 short-lived feeler or an extra block-relay-only connection.
The default settings can result in relatively significant traffic consumption.
Ways to reduce traffic:
1. Use -maxuploadtarget=<MiB per day>
A major component of the traffic is caused by serving historic blocks to other nodes during the initial blocks download phase (syncing up a new node). This option can be specified in MiB per day and is turned off by default. This is not a hard limit; only a threshold to minimize the outbound traffic. When the limit is about to be reached, the uploaded data is cut by no longer serving historic blocks (blocks older than one week). Keep in mind that new nodes require other nodes that are willing to serve historic blocks.
Peers with the download permission will never be disconnected, although their traffic counts for
calculating the target.
2. Disable "listening" (-listen=0)
Disabling listening will result in fewer nodes connected (remember the maximum of 11 outbound peers). Fewer nodes will result in less traffic usage as you are relaying blocks and transactions to fewer nodes.
3. Reduce maximum connections (-maxconnections=<num>)
Reducing the maximum connected nodes to a minimum could be desirable if traffic limits are tiny. Keep in mind that bitcoin's trustless model works best if you are connected to a handful of nodes.
4. Turn off transaction relay (-blocksonly)
Forwarding transactions to peers increases the P2P traffic. To only sync blocks with other peers, you can disable transaction relay.
Be reminded of the effects of this setting.
- Fee estimation will no longer work.
- It sets the flag "-walletbroadcast" to be "0", only if it is currently unset. Doing so disables the automatic broadcasting of transactions from wallet. Not relaying other's transactions could hurt your privacy if used while a wallet is loaded or if you use the node to broadcast transactions.
- If a peer has the forcerelay permission, we will still receive and relay their transactions.
- It makes block propagation slower because compact block relay can only be used when transaction relay is enabled.
Updated settings
- The maximum allowed value for the
-dbcacheconfiguration option has been dropped due to recent UTXO set growth. Note that before this change, large-dbcachevalues were automatically reduced to 16 GiB (1 GiB on 32 bit systems). (#28358)
P2P and network changes
Ephemeral dust is a new concept that allows a single dust output in a transaction, provided the transaction is zero fee. In order to spend any unconfirmed outputs from this transaction, the spender must also spend this dust in addition to any other outputs.
In other words, this type of transaction should be created in a transaction package where the dust is both created and spent simultaneously.
Full Replace-By-Fee
Starting with v28.0, the mempoolfullrbf startup option was set to
default to 1. With widespread adoption of this policy, users no longer
benefit from disabling it, so the option has been removed, making full
replace-by-fee the standard behavior. (#30592)
P2P and network changes
Support for UPnP was dropped. If you want to open a port automatically, consider using the -natpmp
option instead, which uses PCP or NAT-PMP depending on router support.
Updated settings
- Setting
-upnpwill now return an error. Consider using-natpmpinstead.
Test
The BIP94 timewarp attack mitigation (designed for testnet4) is no longer active on the regtest network. (#31156)
The release notes draft is a temporary file that can be added to by anyone. See /doc/developer-notes.md#release-notes for the process.
version Release Notes Draft
Bitcoin Core version version is now available from:
https://bitcoincore.org/bin/bitcoin-core-*version*/
This release includes new features, various bug fixes and performance improvements, as well as updated translations.
Please report bugs using the issue tracker at GitHub:
https://github.com/bitcoin/bitcoin/issues
To receive security and update notifications, please subscribe to:
https://bitcoincore.org/en/list/announcements/join/
How to Upgrade
If you are running an older version, shut it down. Wait until it has completely
shut down (which might take a few minutes in some cases), then run the
installer (on Windows) or just copy over /Applications/Bitcoin-Qt (on macOS)
or bitcoind/bitcoin-qt (on Linux).
Upgrading directly from a version of Bitcoin Core that has reached its EOL is possible, but it might take some time if the data directory needs to be migrated. Old wallet versions of Bitcoin Core are generally supported.
Running Bitcoin Core binaries on macOS requires self signing.
cd /path/to/bitcoin-core/bin
xattr -d com.apple.quarantine bitcoin-cli bitcoin-qt bitcoin-tx bitcoin-util bitcoin-wallet bitcoind test_bitcoin
codesign -s - bitcoin-cli bitcoin-qt bitcoin-tx bitcoin-util bitcoin-wallet bitcoind test_bitcoin
Compatibility
Bitcoin Core is supported and extensively tested on operating systems using the Linux Kernel 3.17+, macOS 13.0+, and Windows 7 and newer. Bitcoin Core should also work on most other Unix-like systems but is not as frequently tested on them. It is not recommended to use Bitcoin Core on unsupported systems.
Notable changes
P2P and network changes
Updated RPCs
Changes to wallet related RPCs can be found in the Wallet section below.
New RPCs
Build System
Updated settings
Changes to GUI or wallet related settings can be found in the GUI or Wallet section below.
New settings
Tools and Utilities
Wallet
GUI changes
Low-level changes
RPC
Tests
version change log
Credits
Thanks to everyone who directly contributed to this release:
As well as to everyone that helped with translations on Transifex.
Release Process
Branch updates
Before every release candidate
- Update release candidate version in
CMakeLists.txt(CLIENT_VERSION_RC). - Update manpages (after rebuilding the binaries), see gen-manpages.py.
- Update bitcoin.conf and commit changes if they exist, see gen-bitcoin-conf.sh.
Before every major and minor release
- Update bips.md to account for changes since the last release.
- Update version in
CMakeLists.txt(don't forget to setCLIENT_VERSION_RCto0). - Update manpages (see previous section)
- Write release notes (see "Write the release notes" below) in doc/release-notes.md. If necessary, archive the previous release notes as doc/release-notes/release-notes-${VERSION}.md.
Before every major release
- On both the master branch and the new release branch:
- update
CLIENT_VERSION_MAJORinCMakeLists.txt
- update
- On the new release branch in
CMakeLists.txt(see this commit):- set
CLIENT_VERSION_MINORto0 - set
CLIENT_VERSION_BUILDto0 - set
CLIENT_VERSION_IS_RELEASEtotrue
- set
Before branch-off
- Update translations see translation_process.md.
- Update hardcoded seeds, see this pull request for an example.
- Update the following variables in
src/kernel/chainparams.cppfor mainnet, testnet, and signet:m_assumed_blockchain_sizeandm_assumed_chain_state_sizewith the current size plus some overhead (see this for information on how to calculate them).- The following updates should be reviewed with
reindex-chainstateandassumevalid=0to catch any defect that causes rejection of blocks in the past history. chainTxDatawith statistics about the transaction count and rate. Use the output of thegetchaintxstatsRPC with annBlocksof 4096 (28 days) and abestblockhashof RPCgetbestblockhash; see this pull request for an example. Reviewers can verify the results by runninggetchaintxstats <window_block_count> <window_final_block_hash>with thewindow_block_countandwindow_final_block_hashfrom your output.defaultAssumeValidwith the output of RPCgetblockhashusing theheightofwindow_final_block_heightabove (and update the block height comment with that height), taking into account the following:- On mainnet, the selected value must not be orphaned, so it may be useful to set the height two blocks back from the tip.
- Testnet should be set with a height some tens of thousands back from the tip, due to reorgs there.
nMinimumChainWorkwith the "chainwork" value of RPCgetblockheaderusing the same height as that selected for the previous step.
- Consider updating the headers synchronization tuning parameters to account for the chainparams updates.
The optimal values change very slowly, so this isn't strictly necessary every release, but doing so doesn't hurt.
- Update configuration variables in
contrib/devtools/headerssync-params.py:- Set
TIMEto the software's expected supported lifetime -- after this time, its ability to defend against a high bandwidth timewarp attacker will begin to degrade. - Set
MINCHAINWORK_HEADERSto the height used for thenMinimumChainWorkcalculation above. - Check that the other variables still look reasonable.
- Set
- Run the script. It works fine in CPython, but PyPy is much faster (seconds instead of minutes):
pypy3 contrib/devtools/headerssync-params.py. - Paste the output defining
HEADER_COMMITMENT_PERIODandREDOWNLOAD_BUFFER_SIZEinto the top ofsrc/headerssync.cpp.
- Update configuration variables in
- Clear the release notes and move them to the wiki (see "Write the release notes" below).
- Translations on Transifex:
- Pull translations from Transifex into the master branch.
- Create a new resource named after the major version with the slug
qt-translation-<RRR>x, whereRRRis the major branch number padded with zeros. Usesrc/qt/locale/bitcoin_en.xlfto create it. - In the project workflow settings, ensure that Translation Memory Fill-up is enabled and that Translation Memory Context Matching is disabled.
- Update the Transifex slug in
.tx/configto the slug of the resource created in the first step. This identifies which resource the translations will be synchronized from. - Make an announcement that translators can start translating for the new version. You can use one of the previous announcements as a template.
- Change the auto-update URL for the resource to
master, e.g.https://raw.githubusercontent.com/bitcoin/bitcoin/master/src/qt/locale/bitcoin_en.xlf. (Do this only after the previous steps, to prevent an auto-update from interfering.)
After branch-off (on the major release branch)
- Update the versions.
- Create the draft, named "version Release Notes Draft", as a collaborative wiki.
- Clear the release notes:
cp doc/release-notes-empty-template.md doc/release-notes.md - Create a pinned meta-issue for testing the release candidate (see this issue for an example) and provide a link to it in the release announcements where useful.
- Translations on Transifex
- Change the auto-update URL for the new major version's resource away from
masterand to the branch, e.g.https://raw.githubusercontent.com/bitcoin/bitcoin/<branch>/src/qt/locale/bitcoin_en.xlf. Do not forget this or it will keep tracking the translations on master instead, drifting away from the specific major release.
- Change the auto-update URL for the new major version's resource away from
- Prune inputs from the qa-assets repo (See pruning inputs).
Before final release
- Merge the release notes from the wiki into the branch.
- Ensure the "Needs release note" label is removed from all relevant pull requests and issues: https://github.com/bitcoin/bitcoin/issues?q=label%3A%22Needs+release+note%22
Tagging a release (candidate)
To tag the version (or release candidate) in git, use the make-tag.py script from bitcoin-maintainer-tools. From the root of the repository run:
../bitcoin-maintainer-tools/make-tag.py v(new version, e.g. 25.0)
This will perform a few last-minute consistency checks in the build system files, and if they pass, create a signed tag.
Building
First time / New builders
Install Guix using one of the installation methods detailed in contrib/guix/INSTALL.md.
Check out the source code in the following directory hierarchy.
cd /path/to/your/toplevel/build
git clone https://github.com/bitcoin-core/guix.sigs.git
git clone https://github.com/bitcoin-core/bitcoin-detached-sigs.git
git clone https://github.com/bitcoin/bitcoin.git
Write the release notes
Open a draft of the release notes for collaborative editing at https://github.com/bitcoin-core/bitcoin-devwiki/wiki.
For the period during which the notes are being edited on the wiki, the version on the branch should be wiped and replaced with a link to the wiki which should be used for all announcements until -final.
Generate list of authors:
git log --format='- %aN' v(current version, e.g. 25.0)..v(new version, e.g. 25.1) | grep -v 'merge-script' | sort -fiu
Setup and perform Guix builds
Checkout the Bitcoin Core version you'd like to build:
pushd ./bitcoin
SIGNER='(your builder key, ie bluematt, sipa, etc)'
VERSION='(new version without v-prefix, e.g. 25.0)'
git fetch origin "v${VERSION}"
git checkout "v${VERSION}"
popd
Ensure your guix.sigs are up-to-date if you wish to guix-verify your builds
against other guix-attest signatures.
git -C ./guix.sigs pull
Create the macOS SDK tarball (first time, or when SDK version changes)
Create the macOS SDK tarball, see the macdeploy instructions for details.
Build and attest to build outputs
Follow the relevant Guix README.md sections:
Verify other builders' signatures to your own (optional)
Commit your non codesigned signature to guix.sigs
pushd ./guix.sigs
git add "${VERSION}/${SIGNER}"/noncodesigned.SHA256SUMS{,.asc}
git commit -m "Add attestations by ${SIGNER} for ${VERSION} non-codesigned"
popd
Then open a Pull Request to the guix.sigs repository.
Codesigning
macOS codesigner only: Create detached macOS signatures (assuming signapple is installed and up to date with master branch)
In the guix-build-${VERSION}/output/x86_64-apple-darwin and guix-build-${VERSION}/output/arm64-apple-darwin directories:
tar xf bitcoin-osx-unsigned.tar.gz
./detached-sig-create.sh /path/to/codesign.p12
Enter the keychain password and authorize the signature
signature-osx.tar.gz will be created
Windows codesigner only: Create detached Windows signatures
In the guix-build-${VERSION}/output/x86_64-w64-mingw32 directory:
tar xf bitcoin-win-unsigned.tar.gz
./detached-sig-create.sh -key /path/to/codesign.key
Enter the passphrase for the key when prompted
signature-win.tar.gz will be created
Windows and macOS codesigners only: test code signatures
It is advised to test that the code signature attaches properly prior to tagging by performing the guix-codesign step.
However if this is done, once the release has been tagged in the bitcoin-detached-sigs repo, the guix-codesign step must be performed again in order for the guix attestation to be valid when compared against the attestations of non-codesigner builds. The directories created by guix-codesign will need to be cleared prior to running guix-codesign again.
Windows and macOS codesigners only: Commit the detached codesign payloads
pushd ./bitcoin-detached-sigs
# checkout or create the appropriate branch for this release series
git checkout --orphan <branch>
# if you are the macOS codesigner
rm -rf osx
tar xf signature-osx.tar.gz
# if you are the windows codesigner
rm -rf win
tar xf signature-win.tar.gz
git add -A
git commit -m "<version>: {osx,win} signature for {rc,final}"
git tag -s "v${VERSION}" HEAD
git push the current branch and new tag
popd
Non-codesigners: wait for Windows and macOS detached signatures
- Once the Windows and macOS builds each have 3 matching signatures, they will be signed with their respective release keys.
- Detached signatures will then be committed to the bitcoin-detached-sigs repository, which can be combined with the unsigned apps to create signed binaries.
Create the codesigned build outputs
Verify other builders' signatures to your own (optional)
Commit your codesigned signature to guix.sigs (for the signed macOS/Windows binaries)
pushd ./guix.sigs
git add "${VERSION}/${SIGNER}"/all.SHA256SUMS{,.asc}
git commit -m "Add attestations by ${SIGNER} for ${VERSION} codesigned"
popd
Then open a Pull Request to the guix.sigs repository.
After 6 or more people have guix-built and their results match
After verifying signatures, combine the all.SHA256SUMS.asc file from all signers into SHA256SUMS.asc:
cat "$VERSION"/*/all.SHA256SUMS.asc > SHA256SUMS.asc
-
Upload to the bitcoincore.org server:
-
The contents of each
./bitcoin/guix-build-${VERSION}/output/${HOST}/directory.Guix will output all of the results into host subdirectories, but the SHA256SUMS file does not include these subdirectories. In order for downloads via torrent to verify without directory structure modification, all of the uploaded files need to be in the same directory as the SHA256SUMS file.
Wait until all of these files have finished uploading before uploading the SHA256SUMS(.asc) files.
-
The
SHA256SUMSfile -
The
SHA256SUMS.asccombined signature file you just created.
-
-
After uploading release candidate binaries, notify the bitcoin-core-dev mailing list and bitcoin-dev group that a release candidate is available for testing. Include a link to the release notes draft.
-
The server will automatically create an OpenTimestamps file and torrent of the directory.
-
Optionally help seed this torrent. To get the
magnet:URI use:transmission-show -m <torrent file>Insert the magnet URI into the announcement sent to mailing lists. This permits people without access to
bitcoincore.orgto download the binary distribution. Also put it into theoptional_magnetlink:slot in the YAML file for bitcoincore.org. -
Archive the release notes for the new version to
doc/release-notes/release-notes-${VERSION}.md(branchmasterand branch of the release). -
Update the bitcoincore.org website
-
blog post
-
maintained versions table
-
RPC documentation update
- See https://github.com/bitcoin-core/bitcoincore.org/blob/master/contrib/doc-gen/
-
-
Update repositories
-
Delete post-EOL release branches and create a tag
v${branch_name}-final. -
Delete "Needs backport" labels for non-existing branches.
-
Update packaging repo
-
Push the flatpak to flathub, e.g. https://github.com/flathub/org.bitcoincore.bitcoin-qt/pull/2
-
Push the snap, see https://github.com/bitcoin-core/packaging/blob/main/snap/local/build.md
-
-
Create a new GitHub release with a link to the archived release notes
-
-
Announce the release:
-
bitcoin-dev and bitcoin-core-dev mailing list
-
Bitcoin Core announcements list https://bitcoincore.org/en/list/announcements/join/
-
Bitcoin Core Twitter https://twitter.com/bitcoincoreorg
-
Celebrate
-
Additional information
How to calculate m_assumed_blockchain_size and m_assumed_chain_state_size
Both variables are used as a guideline for how much space the user needs on their drive in total, not just strictly for the blockchain. Note that all values should be taken from a fully synced node and have an overhead of 5-10% added on top of its base value.
To calculate m_assumed_blockchain_size, take the size in GiB of these directories:
- For
mainnet-> the data directory, excluding the/testnet3,/testnet4,/signet, and/regtestdirectories and any overly large files, e.g. a hugedebug.log - For
testnet->/testnet3 - For
testnet4->/testnet4 - For
signet->/signet
To calculate m_assumed_chain_state_size, take the size in GiB of these directories:
- For
mainnet->/chainstate - For
testnet->/testnet3/chainstate - For
testnet4->/testnet4/chainstate - For
signet->/signet/chainstate
Notes:
- When taking the size for
m_assumed_blockchain_size, there's no need to exclude the/chainstatedirectory since it's a guideline value and an overhead will be added anyway. - The expected overhead for growth may change over time. Consider whether the percentage needs to be changed in response; if so, update it here in this section.
TOR SUPPORT IN BITCOIN
It is possible to run Bitcoin Core as a Tor onion service, and connect to such services.
The following directions assume you have a Tor proxy running on port 9050. Many distributions default to having a SOCKS proxy listening on port 9050, but others may not. In particular, the Tor Browser Bundle defaults to listening on port 9150.
Compatibility
-
Starting with version 22.0, Bitcoin Core only supports Tor version 3 hidden services (Tor v3). Tor v2 addresses are ignored by Bitcoin Core and neither relayed nor stored.
-
Tor removed v2 support beginning with version 0.4.6.
How to see information about your Tor configuration via Bitcoin Core
There are several ways to see your local onion address in Bitcoin Core:
- in the "Local addresses" output of CLI
-netinfo - in the "localaddresses" output of RPC
getnetworkinfo - in the debug log (grep for "AddLocal"; the Tor address ends in
.onion)
You may set the -debug=tor config logging option to have additional
information in the debug log about your Tor configuration.
CLI -addrinfo returns the number of addresses known to your node per
network. This can be useful to see how many onion peers your node knows,
e.g. for -onlynet=onion.
You can use the getnodeaddresses RPC to fetch a number of onion peers known to your node; run bitcoin-cli help getnodeaddresses for details.
1. Run Bitcoin Core behind a Tor proxy
The first step is running Bitcoin Core behind a Tor proxy. This will already anonymize all outgoing connections, but more is possible.
-proxy=ip:port Set the proxy server. If SOCKS5 is selected (default), this proxy
server will be used to try to reach .onion addresses as well.
You need to use -noonion or -onion=0 to explicitly disable
outbound access to onion services.
-onion=ip:port Set the proxy server to use for Tor onion services. You do not
need to set this if it's the same as -proxy. You can use -onion=0
to explicitly disable access to onion services.
------------------------------------------------------------------
Note: Only the -proxy option sets the proxy for DNS requests;
with -onion they will not route over Tor, so use -proxy if you
have privacy concerns.
------------------------------------------------------------------
-listen When using -proxy, listening is disabled by default. If you want
to manually configure an onion service (see section 3), you'll
need to enable it explicitly.
-connect=X When behind a Tor proxy, you can specify .onion addresses instead
-addnode=X of IP addresses or hostnames in these parameters. It requires
-seednode=X SOCKS5. In Tor mode, such addresses can also be exchanged with
other P2P nodes.
-onlynet=onion Make automatic outbound connections only to .onion addresses.
Inbound and manual connections are not affected by this option.
It can be specified multiple times to allow multiple networks,
e.g. onlynet=onion, onlynet=i2p, onlynet=cjdns.
In a typical situation, this suffices to run behind a Tor proxy:
./bitcoind -proxy=127.0.0.1:9050
2. Automatically create a Bitcoin Core onion service
Bitcoin Core makes use of Tor's control socket API to create and destroy ephemeral onion services programmatically. This means that if Tor is running and proper authentication has been configured, Bitcoin Core automatically creates an onion service to listen on. The goal is to increase the number of available onion nodes.
This feature is enabled by default if Bitcoin Core is listening (-listen) and
it requires a Tor connection to work. It can be explicitly disabled with
-listenonion=0. If it is not disabled, it can be configured using the
-torcontrol and -torpassword settings.
To see verbose Tor information in the bitcoind debug log, pass -debug=tor.
Control Port
You may need to set up the Tor Control Port. On Linux distributions there may be
some or all of the following settings in /etc/tor/torrc, generally commented
out by default (if not, add them):
ControlPort 9051
CookieAuthentication 1
CookieAuthFileGroupReadable 1
DataDirectoryGroupReadable 1
Add or uncomment those, save, and restart Tor (usually systemctl restart tor
or sudo systemctl restart tor on most systemd-based systems, including recent
Debian and Ubuntu, or just restart the computer).
Authentication
Connecting to Tor's control socket API requires one of two authentication
methods to be configured: cookie authentication or bitcoind's -torpassword
configuration option.
Cookie authentication
For cookie authentication, the user running bitcoind must have read access to
the CookieAuthFile specified in the Tor configuration. In some cases this is
preconfigured and the creation of an onion service is automatic. Don't forget to
use the -debug=tor bitcoind configuration option to enable Tor debug logging.
If a permissions problem is seen in the debug log, e.g. tor: Authentication cookie /run/tor/control.authcookie could not be opened (check permissions), it
can be resolved by adding both the user running Tor and the user running
bitcoind to the same Tor group and setting permissions appropriately.
On Debian-derived systems, the Tor group will likely be debian-tor and one way
to verify could be to list the groups and grep for a "tor" group name:
getent group | cut -d: -f1 | grep -i tor
You can also check the group of the cookie file. On most Linux systems, the Tor
auth cookie will usually be /run/tor/control.authcookie:
TORGROUP=$(stat -c '%G' /run/tor/control.authcookie)
Once you have determined the ${TORGROUP} and selected the ${USER} that will
run bitcoind, run this as root:
usermod -a -G ${TORGROUP} ${USER}
Then restart the computer (or log out) and log in as the ${USER} that will run
bitcoind.
torpassword authentication
For the -torpassword=password option, the password is the clear text form that
was used when generating the hashed password for the HashedControlPassword
option in the Tor configuration file.
The hashed password can be obtained with the command tor --hash-password password (refer to the Tor Dev
Manual for more
details).
3. Manually create a Bitcoin Core onion service
You can also manually configure your node to be reachable from the Tor network.
Add these lines to your /etc/tor/torrc (or equivalent config file):
HiddenServiceDir /var/lib/tor/bitcoin-service/
HiddenServicePort 8333 127.0.0.1:8334
The directory can be different of course, but virtual port numbers should be equal to your bitcoind's P2P listen port (8333 by default), and target addresses and ports should be equal to binding address and port for inbound Tor connections (127.0.0.1:8334 by default).
-externalip=X You can tell bitcoin about its publicly reachable addresses using
this option, and this can be an onion address. Given the above
configuration, you can find your onion address in
/var/lib/tor/bitcoin-service/hostname. For connections
coming from unroutable addresses (such as 127.0.0.1, where the
Tor proxy typically runs), onion addresses are given
preference for your node to advertise itself with.
You can set multiple local addresses with -externalip. The
one that will be rumoured to a particular peer is the most
compatible one and also using heuristics, e.g. the address
with the most incoming connections, etc.
-listen You'll need to enable listening for incoming connections, as this
is off by default behind a proxy.
-discover When -externalip is specified, no attempt is made to discover local
IPv4 or IPv6 addresses. If you want to run a dual stack, reachable
from both Tor and IPv4 (or IPv6), you'll need to either pass your
other addresses using -externalip, or explicitly enable -discover.
Note that both addresses of a dual-stack system may be easily
linkable using traffic analysis.
In a typical situation, where you're only reachable via Tor, this should suffice:
./bitcoind -proxy=127.0.0.1:9050 -externalip=7zvj7a2imdgkdbg4f2dryd5rgtrn7upivr5eeij4cicjh65pooxeshid.onion -listen
(obviously, replace the .onion address with your own). It should be noted that you still listen on all devices and another node could establish a clearnet connection, when knowing your address. To mitigate this, additionally bind the address of your Tor proxy:
./bitcoind ... -bind=127.0.0.1:8334=onion
If you don't care too much about hiding your node, and want to be reachable on IPv4
as well, use discover instead:
./bitcoind ... -discover
and open port 8333 on your firewall (or use port mapping, i.e., -natpmp).
If you only want to use Tor to reach .onion addresses, but not use it as a proxy for normal IPv4/IPv6 communication, use:
./bitcoind -onion=127.0.0.1:9050 -externalip=7zvj7a2imdgkdbg4f2dryd5rgtrn7upivr5eeij4cicjh65pooxeshid.onion -discover
4. Privacy recommendations
- Do not add anything but Bitcoin Core ports to the onion service created in section 3. If you run a web service too, create a new onion service for that. Otherwise it is trivial to link them, which may reduce privacy. Onion services created automatically (as in section 2) always have only one port open.
User-space, Statically Defined Tracing (USDT) for Bitcoin Core
Bitcoin Core includes statically defined tracepoints to allow for more observability during development, debugging, code review, and production usage. These tracepoints make it possible to keep track of custom statistics and enable detailed monitoring of otherwise hidden internals. They have little to no performance impact when unused.
eBPF and USDT Overview
======================
┌──────────────────┐ ┌──────────────┐
│ tracing script │ │ bitcoind │
│==================│ 2. │==============│
│ eBPF │ tracing │ hooks │ │
│ code │ logic │ into┌─┤►tracepoint 1─┼───┐ 3.
└────┬───┴──▲──────┘ ├─┤►tracepoint 2 │ │ pass args
1. │ │ 4. │ │ ... │ │ to eBPF
User compiles │ │ pass data to │ └──────────────┘ │ program
Space & loads │ │ tracing script │ │
─────────────────┼──────┼─────────────────┼────────────────────┼───
Kernel │ │ │ │
Space ┌──┬─▼──────┴─────────────────┴────────────┐ │
│ │ eBPF program │◄──────┘
│ └───────────────────────────────────────┤
│ eBPF kernel Virtual Machine (sandboxed) │
└──────────────────────────────────────────┘
1. The tracing script compiles the eBPF code and loads the eBPF program into a kernel VM
2. The eBPF program hooks into one or more tracepoints
3. When the tracepoint is called, the arguments are passed to the eBPF program
4. The eBPF program processes the arguments and returns data to the tracing script
The Linux kernel can hook into the tracepoints during runtime and pass data to sandboxed eBPF programs running in the kernel. These eBPF programs can, for example, collect statistics or pass data back to user-space scripts for further processing.
The two main eBPF front-ends with support for USDT are bpftrace and
BPF Compiler Collection (BCC). BCC is used for complex tools and daemons and
bpftrace is preferred for one-liners and shorter scripts. Examples for both can
be found in contrib/tracing.
Tracepoint documentation
The currently available tracepoints are listed here.
Context net
Tracepoint net:inbound_message
Is called when a message is received from a peer over the P2P network. Passes information about our peer, the connection and the message as arguments.
Arguments passed:
- Peer ID as
int64 - Peer Address and Port (IPv4, IPv6, Tor v3, I2P, ...) as
pointer to C-style String(max. length 68 characters) - Connection Type (inbound, feeler, outbound-full-relay, ...) as
pointer to C-style String(max. length 20 characters) - Message Type (inv, ping, getdata, addrv2, ...) as
pointer to C-style String(max. length 20 characters) - Message Size in bytes as
uint64 - Message Bytes as
pointer to unsigned chars(i.e. bytes)
Note: The message is passed to the tracepoint in full, however, due to space limitations in the eBPF kernel VM it might not be possible to pass the message to user-space in full. Messages longer than a 32kb might be cut off. This can be detected in tracing scripts by comparing the message size to the length of the passed message.
Tracepoint net:outbound_message
Is called when a message is sent to a peer over the P2P network. Passes information about our peer, the connection and the message as arguments.
Arguments passed:
- Peer ID as
int64 - Peer Address and Port (IPv4, IPv6, Tor v3, I2P, ...) as
pointer to C-style String(max. length 68 characters) - Connection Type (inbound, feeler, outbound-full-relay, ...) as
pointer to C-style String(max. length 20 characters) - Message Type (inv, ping, getdata, addrv2, ...) as
pointer to C-style String(max. length 20 characters) - Message Size in bytes as
uint64 - Message Bytes as
pointer to unsigned chars(i.e. bytes)
Note: The message is passed to the tracepoint in full, however, due to space limitations in the eBPF kernel VM it might not be possible to pass the message to user-space in full. Messages longer than a 32kb might be cut off. This can be detected in tracing scripts by comparing the message size to the length of the passed message.
Context validation
Tracepoint validation:block_connected
Is called after a block is connected to the chain. Can, for example, be used
to benchmark block connections together with -reindex.
Arguments passed:
- Block Header Hash as
pointer to unsigned chars(i.e. 32 bytes in little-endian) - Block Height as
int32 - Transactions in the Block as
uint64 - Inputs spend in the Block as
int32 - SigOps in the Block (excluding coinbase SigOps)
uint64 - Time it took to connect the Block in nanoseconds (ns) as
uint64
Context utxocache
The following tracepoints cover the in-memory UTXO cache. UTXOs are, for example,
added to and removed (spent) from the cache when we connect a new block.
Note: Bitcoin Core uses temporary clones of the main UTXO cache
(chainstate.CoinsTip()). For example, the RPCs generateblock and
getblocktemplate call TestBlockValidity(), which applies the UTXO set
changes to a temporary cache. Similarly, mempool consistency checks, which are
frequent on regtest, also apply the UTXO set changes to a temporary cache.
Changes to the main UTXO cache and to temporary caches trigger the tracepoints.
We can't tell if a temporary cache or the main cache was changed.
Tracepoint utxocache:flush
Is called after the in-memory UTXO cache is flushed.
Arguments passed:
- Time it took to flush the cache microseconds as
int64 - Flush state mode as
uint32. It's an enumerator class with values0(NONE),1(IF_NEEDED),2(PERIODIC),3(ALWAYS) - Cache size (number of coins) before the flush as
uint64 - Cache memory usage in bytes as
uint64 - If pruning caused the flush as
bool
Tracepoint utxocache:add
Is called when a coin is added to a UTXO cache. This can be a temporary UTXO cache too.
Arguments passed:
- Transaction ID (hash) as
pointer to unsigned chars(i.e. 32 bytes in little-endian) - Output index as
uint32 - Block height the coin was added to the UTXO-set as
uint32 - Value of the coin as
int64 - If the coin is a coinbase as
bool
Tracepoint utxocache:spent
Is called when a coin is spent from a UTXO cache. This can be a temporary UTXO cache too.
Arguments passed:
- Transaction ID (hash) as
pointer to unsigned chars(i.e. 32 bytes in little-endian) - Output index as
uint32 - Block height the coin was spent, as
uint32 - Value of the coin as
int64 - If the coin is a coinbase as
bool
Tracepoint utxocache:uncache
Is called when a coin is purposefully unloaded from a UTXO cache. This happens, for example, when we load an UTXO into a cache when trying to accept a transaction that turns out to be invalid. The loaded UTXO is uncached to avoid filling our UTXO cache up with irrelevant UTXOs.
Arguments passed:
- Transaction ID (hash) as
pointer to unsigned chars(i.e. 32 bytes in little-endian) - Output index as
uint32 - Block height the coin was uncached, as
uint32 - Value of the coin as
int64 - If the coin is a coinbase as
bool
Context coin_selection
Tracepoint coin_selection:selected_coins
Is called when SelectCoins completes.
Arguments passed:
- Wallet name as
pointer to C-style string - Coin selection algorithm name as
pointer to C-style string - Selection target value as
int64 - Calculated waste metric of the solution as
int64 - Total value of the selected inputs as
int64
Tracepoint coin_selection:normal_create_tx_internal
Is called when the first CreateTransactionInternal completes.
Arguments passed:
- Wallet name as
pointer to C-style string - Whether
CreateTransactionInternalsucceeded asbool - The expected transaction fee as an
int64 - The position of the change output as an
int32
Tracepoint coin_selection:attempting_aps_create_tx
Is called when CreateTransactionInternal is called the second time for the optimistic
Avoid Partial Spends selection attempt. This is used to determine whether the next
tracepoints called are for the Avoid Partial Spends solution, or a different transaction.
Arguments passed:
- Wallet name as
pointer to C-style string
Tracepoint coin_selection:aps_create_tx_internal
Is called when the second CreateTransactionInternal with Avoid Partial Spends enabled completes.
Arguments passed:
- Wallet name as
pointer to C-style string - Whether the Avoid Partial Spends solution will be used as
bool - Whether
CreateTransactionInternalsucceeded asbool - The expected transaction fee as an
int64 - The position of the change output as an
int32
Context mempool
Tracepoint mempool:added
Is called when a transaction is added to the node's mempool. Passes information about the transaction.
Arguments passed:
- Transaction ID (hash) as
pointer to unsigned chars(i.e. 32 bytes in little-endian) - Transaction virtual size as
int32 - Transaction fee as
int64
Tracepoint mempool:removed
Is called when a transaction is removed from the node's mempool. Passes information about the transaction.
Arguments passed:
- Transaction ID (hash) as
pointer to unsigned chars(i.e. 32 bytes in little-endian) - Removal reason as
pointer to C-style String(max. length 9 characters) - Transaction virtual size as
int32 - Transaction fee as
int64 - Transaction mempool entry time (epoch) as
uint64
Tracepoint mempool:replaced
Is called when a transaction in the node's mempool is getting replaced by another. Passes information about the replaced and replacement transactions.
Arguments passed:
- Replaced transaction ID (hash) as
pointer to unsigned chars(i.e. 32 bytes in little-endian) - Replaced transaction virtual size as
int32 - Replaced transaction fee as
int64 - Replaced transaction mempool entry time (epoch) as
uint64 - Replacement transaction ID (hash) as
pointer to unsigned chars(i.e. 32 bytes in little-endian) - Replacement transaction virtual size as
int32 - Replacement transaction fee as
int64
Note: In cases where a single replacement transaction replaces multiple existing transactions in the mempool, the tracepoint is called once for each replaced transaction, with data of the replacement transaction being the same in each call.
Tracepoint mempool:rejected
Is called when a transaction is not permitted to enter the mempool. Passes information about the rejected transaction.
Arguments passed:
- Transaction ID (hash) as
pointer to unsigned chars(i.e. 32 bytes in little-endian) - Reject reason as
pointer to C-style String(max. length 118 characters)
Adding tracepoints to Bitcoin Core
Use the TRACEPOINT macro to add a new tracepoint. If not yet included, include
util/trace.h (defines the tracepoint macros) with #include <util/trace.h>.
Each tracepoint needs a context and an event. Please use snake_case and
try to make sure that the tracepoint names make sense even without detailed
knowledge of the implementation details. You can pass zero to twelve arguments
to the tracepoint. Each tracepoint also needs a global semaphore. The semaphore
gates the tracepoint arguments from being processed if we are not attached to
the tracepoint. Add a TRACEPOINT_SEMAPHORE(context, event) with the context
and event of your tracepoint in the top-level namespace at the beginning of
the file. Do not forget to update the tracepoint list in this document.
For example, the net:outbound_message tracepoint in src/net.cpp with six
arguments.
// src/net.cpp
TRACEPOINT_SEMAPHORE(net, outbound_message);
…
void CConnman::PushMessage(…) {
…
TRACEPOINT(net, outbound_message,
pnode->GetId(),
pnode->m_addr_name.c_str(),
pnode->ConnectionTypeAsString().c_str(),
sanitizedType.c_str(),
msg.data.size(),
msg.data.data()
);
…
}
If needed, an extra if (TRACEPOINT_ACTIVE(context, event)) {...} check can be
used to prepare somewhat expensive arguments right before the tracepoint. While
the tracepoint arguments are only prepared when we attach something to the
tracepoint, an argument preparation should never hang the process. Hashing and
serialization of data structures is probably fine, a sleep(10s) not.
// An example tracepoint with an expensive argument.
TRACEPOINT_SEMAPHORE(example, gated_expensive_argument);
…
if (TRACEPOINT_ACTIVE(example, gated_expensive_argument)) {
expensive_argument = expensive_calulation();
TRACEPOINT(example, gated_expensive_argument, expensive_argument);
}
Guidelines and best practices
Clear motivation and use case
Tracepoints need a clear motivation and use case. The motivation should outweigh the impact on, for example, code readability. There is no point in adding tracepoints that don't end up being used.
Provide an example
When adding a new tracepoint, provide an example. Examples can show the use case and help reviewers testing that the tracepoint works as intended. The examples can be kept simple but should give others a starting point when working with the tracepoint. See existing examples in contrib/tracing/.
Semi-stable API
Tracepoints should have a semi-stable API. Users should be able to rely on the tracepoints for scripting. This means tracepoints need to be documented, and the argument order ideally should not change. If there is an important reason to change argument order, make sure to document the change and update the examples using the tracepoint.
eBPF Virtual Machine limits
Keep the eBPF Virtual Machine limits in mind. eBPF programs receiving data from the tracepoints run in a sandboxed Linux kernel VM. This VM has a limited stack size of 512 bytes. Check if it makes sense to pass larger amounts of data, for example, with a tracing script that can handle the passed data.
bpftrace argument limit
While tracepoints can have up to 12 arguments, bpftrace scripts currently only
support reading from the first six arguments (arg0 till arg5) on x86_64.
bpftrace currently lacks real support for handling and printing binary data,
like block header hashes and txids. When a tracepoint passes more than six
arguments, then string and integer arguments should preferably be placed in the
first six argument fields. Binary data can be placed in later arguments. The BCC
supports reading from all 12 arguments.
Strings as C-style String
Generally, strings should be passed into the TRACEPOINT macros as pointers to
C-style strings (a null-terminated sequence of characters). For C++
std::strings, c_str() can be used. It's recommended to document the
maximum expected string size if known.
Listing available tracepoints
Multiple tools can list the available tracepoints in a bitcoind binary with
USDT support.
GDB - GNU Project Debugger
To list probes in Bitcoin Core, use info probes in gdb:
$ gdb ./build/src/bitcoind
…
(gdb) info probes
Type Provider Name Where Semaphore Object
stap net inbound_message 0x000000000014419e 0x0000000000d29bd2 /build/src/bitcoind
stap net outbound_message 0x0000000000107c05 0x0000000000d29bd0 /build/src/bitcoind
stap validation block_connected 0x00000000002fb10c 0x0000000000d29bd8 /build/src/bitcoind
…
With readelf
The readelf tool can be used to display the USDT tracepoints in Bitcoin Core.
Look for the notes with the description NT_STAPSDT.
$ readelf -n ./build/src/bitcoind | grep NT_STAPSDT -A 4 -B 2
Displaying notes found in: .note.stapsdt
Owner Data size Description
stapsdt 0x0000005d NT_STAPSDT (SystemTap probe descriptors)
Provider: net
Name: outbound_message
Location: 0x0000000000107c05, Base: 0x0000000000579c90, Semaphore: 0x0000000000d29bd0
Arguments: -8@%r12 8@%rbx 8@%rdi 8@192(%rsp) 8@%rax 8@%rdx
…
With tplist
The tplist tool is provided by BCC (see Installing BCC). It displays kernel
tracepoints or USDT probes and their formats (for more information, see the
tplist usage demonstration). There are slight binary naming differences
between distributions. For example, on
Ubuntu the binary is called tplist-bpfcc.
$ tplist -l ./build/src/bitcoind -v
b'net':b'outbound_message' [sema 0xd29bd0]
1 location(s)
6 argument(s)
…
Translations
The Bitcoin-Core project has been designed to support multiple localisations. This makes adding new phrases, and completely new languages easily achievable. For managing all application translations, Bitcoin-Core makes use of the Transifex online translation management tool.
Helping to translate (using Transifex)
Transifex is setup to monitor the GitHub repo for updates, and when code containing new translations is found, Transifex will process any changes. It may take several hours after a pull-request has been merged, to appear in the Transifex web interface.
Multiple language support is critical in assisting Bitcoin’s global adoption, and growth. One of Bitcoin’s greatest strengths is cross-border money transfers, any help making that easier is greatly appreciated.
See the Transifex Bitcoin project to assist in translations. You should also join the translation mailing list for announcements - see details below.
Writing code with translations
We use automated scripts to help extract translations in both Qt, and non-Qt source files. It is rarely necessary to manually edit the files in src/qt/locale/. The translation source files must adhere to the following format:
bitcoin_xx_YY.ts or bitcoin_xx.ts
src/qt/locale/bitcoin_en.ts is treated in a special way. It is used as the source for all other translations. Whenever a string in the source code is changed, this file must be updated to reflect those changes. A custom script is used to extract strings from the non-Qt parts. This script makes use of gettext, so make sure that utility is installed (ie, apt-get install gettext on Ubuntu/Debian). Once this has been updated, lupdate (included in the Qt SDK) is used to update bitcoin_en.ts.
To automatically regenerate the bitcoin_en.ts file, run the following commands:
cmake -B build --preset dev-mode -DWITH_BDB=ON -DBUILD_GUI=ON
cmake --build build --target translate
Example Qt translation
QToolBar *toolbar = addToolBar(tr("Tabs toolbar"));
Creating a pull-request
For general PRs, you shouldn’t include any updates to the translation source files. They will be updated periodically, primarily around pre-releases, allowing time for any new phrases to be translated before public releases. This is also important in avoiding translation related merge conflicts.
When an updated source file is merged into the GitHub repo, Transifex will automatically detect it (although it can take several hours). Once processed, the new strings will show up as "Remaining" in the Transifex web interface and are ready for translators.
To create the pull-request, use the following commands:
git add src/qt/bitcoinstrings.cpp src/qt/locale/bitcoin_en.ts
git commit
Creating a Transifex account
Visit the Transifex Signup page to create an account. Take note of your username and password, as they will be required to configure the command-line tool.
You can find the Bitcoin translation project at https://www.transifex.com/bitcoin/bitcoin/.
Installing the Transifex client command-line tool
The client is used to fetch updated translations. Please check installation instructions and any other details at https://developers.transifex.com/docs/cli.
The Transifex Bitcoin project config file is included as part of the repo. It can be found at .tx/config, however you shouldn’t need to change anything.
Synchronising translations
To assist in updating translations, a helper script is available in the maintainer-tools repo. To use it and commit the result, simply do:
python3 ../bitcoin-maintainer-tools/update-translations.py
git commit -a
Do not directly download translations one by one from the Transifex website, as we do a few post-processing steps before committing the translations.
Handling Plurals (in source files)
When new plurals are added to the source file, it's important to do the following steps:
- Open
bitcoin_en.tsin Qt Linguist (included in the Qt SDK) - Search for
%n, which will take you to the parts in the translation that use plurals - Look for empty
English Translation (Singular)andEnglish Translation (Plural)fields - Add the appropriate strings for the singular and plural form of the base string
- Mark the item as done (via the green arrow symbol in the toolbar)
- Repeat from step 2, until all singular and plural forms are in the source file
- Save the source file
Translating a new language
To create a new language template, you will need to edit the languages manifest file src/qt/bitcoin_locale.qrc and add a new entry. Below is an example of the English language entry.
<qresource prefix="/translations">
<file alias="en">locale/bitcoin_en.qm</file>
...
</qresource>
Note: that the language translation file must end in .qm (the compiled extension), and not .ts.
Questions and general assistance
If you are a translator, you should also subscribe to the mailing list, https://groups.google.com/forum/#!forum/bitcoin-translators. Announcements will be posted during application pre-releases to notify translators to check for updates.
Translation Strings Policy
This document provides guidelines for internationalization of the Bitcoin Core software.
How to translate?
To mark a message as translatable
-
In GUI source code (under
src/qt): usetr("...") -
In non-GUI source code (under
src): use_("...")
No internationalization is used for e.g. developer scripts outside src.
Strings to be translated
On a high level, these strings are to be translated:
- GUI strings, anything that appears in a dialog or window
GUI strings
Do not translate technical or extremely rare errors.
Anything else that appears to the user in the GUI is to be translated. This includes labels, menu items, button texts, tooltips and window titles.
This includes messages passed to the GUI through the UI interface through InitMessage, ThreadSafeMessageBox or ShowProgress.
General recommendations
Avoid unnecessary translation strings
Try not to burden translators with translating messages that are e.g. slight variations of other messages.
In the GUI, avoid the use of text where an icon or symbol will do.
Make sure that placeholder texts in forms do not end up in the list of strings to be translated (use <string notr="true">).
Make translated strings understandable
Try to write translation strings in an understandable way, for both the user and the translator. Avoid overly technical or detailed messages.
Do not translate internal errors
Do not translate internal errors, log messages, or messages that appear on the RPC interface. If an error is to be shown to the user, use a translatable generic message, then log the detailed message to the log. E.g., "A fatal internal error occurred, see debug.log for details". This helps troubleshooting; if the error is the same for everyone, the likelihood is increased that it can be found using a search engine.
Avoid fragments
Avoid dividing up a message into fragments. Translators see every string separately, so they may misunderstand the context if the messages are not self-contained.
Avoid HTML in translation strings
There have been difficulties with the use of HTML in translation strings; translators should not be able to accidentally affect the formatting of messages. This may sometimes be at conflict with the recommendation in the previous section.
Plurals
Plurals can be complex in some languages. A quote from the gettext documentation:
In Polish we use e.g. plik (file) this way:
1 plik,
2,3,4 pliki,
5-21 pliko'w,
22-24 pliki,
25-31 pliko'w
and so on
In Qt code, use tr's third argument for optional plurality. For example:
tr("%n hour(s)","",secs/HOUR_IN_SECONDS);
tr("%n day(s)","",secs/DAY_IN_SECONDS);
tr("%n week(s)","",secs/WEEK_IN_SECONDS);
This adds <numerusform>s to the respective .ts file, which can be translated separately depending on the language. In English, this is simply:
<message numerus="yes">
<source>%n active connection(s) to Bitcoin network</source>
<translation>
<numerusform>%n active connection to Bitcoin network</numerusform>
<numerusform>%n active connections to Bitcoin network</numerusform>
</translation>
</message>
Where possible, try to avoid embedding numbers into the flow of the string at all. E.g.,
WARNING: check your network connection, %d blocks received in the last %d hours (%d expected)
versus
WARNING: check your network connection, less blocks (%d) were received in the last %n hours than expected (%d).
The second example reduces the number of pluralized words that translators have to handle from three to one, at no cost to comprehensibility of the sentence.
String freezes
During a string freeze (often before a major release), no translation strings are to be added, modified or removed.
This can be checked by building the translate target with cmake (instructions), then verifying that bitcoin_en.ts remains unchanged.
Block and Transaction Broadcasting with ZeroMQ
ZeroMQ is a lightweight wrapper around TCP connections, inter-process communication, and shared-memory, providing various message-oriented semantics such as publish/subscribe, request/reply, and push/pull.
The Bitcoin Core daemon can be configured to act as a trusted "border router", implementing the bitcoin wire protocol and relay, making consensus decisions, maintaining the local blockchain database, broadcasting locally generated transactions into the network, and providing a queryable RPC interface to interact on a polled basis for requesting blockchain related data. However, there exists only a limited service to notify external software of events like the arrival of new blocks or transactions.
The ZeroMQ facility implements a notification interface through a set of specific notifiers. Currently there are notifiers that publish blocks and transactions. This read-only facility requires only the connection of a corresponding ZeroMQ subscriber port in receiving software; it is not authenticated nor is there any two-way protocol involvement. Therefore, subscribers should validate the received data since it may be out of date, incomplete or even invalid.
ZeroMQ sockets are self-connecting and self-healing; that is, connections made between two endpoints will be automatically restored after an outage, and either end may be freely started or stopped in any order.
Because ZeroMQ is message oriented, subscribers receive transactions and blocks all-at-once and do not need to implement any sort of buffering or reassembly.
Prerequisites
The ZeroMQ feature in Bitcoin Core requires the ZeroMQ API >= 4.0.0 libzmq. For version information, see dependencies.md. Typically, it is packaged by distributions as something like libzmq3-dev. The C++ wrapper for ZeroMQ is not needed.
In order to run the example Python client scripts in the contrib/zmq/
directory, one must also install PyZMQ
(generally with pip install pyzmq), though this is not necessary for daemon
operation.
Enabling
By default, the ZeroMQ feature is not automatically compiled.
To enable, use -DWITH_ZMQ=ON when configuring the build system:
$ cmake -B build -DWITH_ZMQ=ON
To actually enable operation, one must set the appropriate options on the command line or in the configuration file.
Usage
Currently, the following notifications are supported:
-zmqpubhashtx=address
-zmqpubhashblock=address
-zmqpubrawblock=address
-zmqpubrawtx=address
-zmqpubsequence=address
The socket type is PUB and the address must be a valid ZeroMQ socket address. The same address can be used in more than one notification. The same notification can be specified more than once.
The option to set the PUB socket's outbound message high water mark (SNDHWM) may be set individually for each notification:
-zmqpubhashtxhwm=n
-zmqpubhashblockhwm=n
-zmqpubrawblockhwm=n
-zmqpubrawtxhwm=n
-zmqpubsequencehwm=n
The high water mark value must be an integer greater than or equal to 0.
For instance:
$ bitcoind -zmqpubhashtx=tcp://127.0.0.1:28332 \
-zmqpubhashtx=tcp://192.168.1.2:28332 \
-zmqpubhashblock="tcp://[::1]:28333" \
-zmqpubrawtx=ipc:///tmp/bitcoind.tx.raw \
-zmqpubhashtxhwm=10000
Each PUB notification has a topic and body, where the header
corresponds to the notification type. For instance, for the
notification -zmqpubhashtx the topic is hashtx (no null
terminator). These options can also be provided in bitcoin.conf.
The topics are:
sequence: the body is structured as the following based on the type of message:
<32-byte hash>C : Blockhash connected
<32-byte hash>D : Blockhash disconnected
<32-byte hash>R<8-byte LE uint> : Transactionhash removed from mempool for non-block inclusion reason
<32-byte hash>A<8-byte LE uint> : Transactionhash added mempool
Where the 8-byte uints correspond to the mempool sequence number.
rawtx: Notifies about all transactions, both when they are added to mempool or when a new block arrives. This means a transaction could be published multiple times. First, when it enters the mempool and then again in each block that includes it. The messages are ZMQ multipart messages with three parts. The first part is the topic (rawtx), the second part is the serialized transaction, and the last part is a sequence number (representing the message count to detect lost messages).
| rawtx | <serialized transaction> | <uint32 sequence number in Little Endian>
hashtx: Notifies about all transactions, both when they are added to mempool or when a new block arrives. This means a transaction could be published multiple times. First, when it enters the mempool and then again in each block that includes it. The messages are ZMQ multipart messages with three parts. The first part is the topic (hashtx), the second part is the 32-byte transaction hash, and the last part is a sequence number (representing the message count to detect lost messages).
| hashtx | <32-byte transaction hash in Little Endian> | <uint32 sequence number in Little Endian>
rawblock: Notifies when the chain tip is updated. When assumeutxo is in use, this notification will not be issued for historical blocks connected to the background validation chainstate. Messages are ZMQ multipart messages with three parts. The first part is the topic (rawblock), the second part is the serialized block, and the last part is a sequence number (representing the message count to detect lost messages).
| rawblock | <serialized block> | <uint32 sequence number in Little Endian>
hashblock: Notifies when the chain tip is updated. When assumeutxo is in use, this notification will not be issued for historical blocks connected to the background validation chainstate. Messages are ZMQ multipart messages with three parts. The first part is the topic (hashblock), the second part is the 32-byte block hash, and the last part is a sequence number (representing the message count to detect lost messages).
| hashblock | <32-byte block hash in Little Endian> | <uint32 sequence number in Little Endian>
NOTE: Note that the 32-byte hashes are in Little Endian and not in the Big Endian format that the RPC interface and block explorers use to display transaction and block hashes.
ZeroMQ endpoint specifiers for TCP (and others) are documented in the ZeroMQ API.
Client side, then, the ZeroMQ subscriber socket must have the
ZMQ_SUBSCRIBE option set to one or either of these prefixes (for
instance, just hash); without doing so will result in no messages
arriving. Please see contrib/zmq/zmq_sub.py for a working example.
The ZMQ_PUB socket's ZMQ_TCP_KEEPALIVE option is enabled. This means that the underlying SO_KEEPALIVE option is enabled when using a TCP transport. The effective TCP keepalive values are managed through the underlying operating system configuration and must be configured prior to connection establishment.
For example, when running on GNU/Linux, one might use the following to lower the keepalive setting to 10 minutes:
sudo sysctl -w net.ipv4.tcp_keepalive_time=600
Setting the keepalive values appropriately for your operating environment may improve connectivity in situations where long-lived connections are silently dropped by network middle boxes.
Also, the socket's ZMQ_IPV6 option is enabled to accept connections from IPv6 hosts as well. If needed, this option has to be set on the client side too.
Remarks
From the perspective of bitcoind, the ZeroMQ socket is write-only; PUB sockets don't even have a read function. Thus, there is no state introduced into bitcoind directly. Furthermore, no information is broadcast that wasn't already received from the public P2P network.
No authentication or authorization is done on connecting clients; it is assumed that the ZeroMQ port is exposed only to trusted entities, using other means such as firewalling.
Note that for *block topics, when the block chain tip changes,
a reorganisation may occur and just the tip will be notified.
It is up to the subscriber to retrieve the chain from the last known
block to the new tip. Also note that no notification will occur if the tip
was in the active chain, as would be the case after calling the invalidateblock RPC.
In contrast, the sequence topic publishes all block connections and
disconnections.
There are several possibilities that ZMQ notification can get lost during transmission depending on the communication type you are using. Bitcoind appends an up-counting sequence number to each notification which allows listeners to detect lost notifications.
The sequence topic refers specifically to the mempool sequence
number, which is also published along with all mempool events. This
is a different sequence value than in ZMQ itself in order to allow a total
ordering of mempool events to be constructed.
This Page Intentionally Left Blank
Assumeutxo Design
For notes on the usage of Assumeutxo, please refer to the usage doc.
General background
Design notes
-
The concept of UTXO snapshots is treated as an implementation detail that lives behind the ChainstateManager interface. The external presentation of the changes required to facilitate the use of UTXO snapshots is the understanding that there are now certain regions of the chain that can be temporarily assumed to be valid. In certain cases, e.g. wallet rescanning, this is very similar to dealing with a pruned chain.
Logic outside ChainstateManager should try not to know about snapshots, instead preferring to work in terms of more general states like assumed-valid.
Chainstate phases
Chainstate within the system goes through a number of phases when UTXO snapshots are
used, as managed by ChainstateManager. At various points there can be multiple
Chainstate objects in existence to facilitate both maintaining the network tip and
performing historical validation of the assumed-valid chain.
It is worth noting that though there are multiple separate chainstates, those
chainstates share use of a common block index (i.e. they hold the same BlockManager
reference).
The subheadings below outline the phases and the corresponding changes to chainstate data.
"Normal" operation via initial block download
ChainstateManager manages a single Chainstate object, for which
m_from_snapshot_blockhash is std::nullopt. This chainstate is (maybe obviously)
considered active. This is the "traditional" mode of operation for bitcoind.
| number of chainstates | 1 |
| active chainstate | ibd |
User loads a UTXO snapshot via loadtxoutset RPC
ChainstateManager initializes a new chainstate (see ActivateSnapshot()) to load the
snapshot contents into. During snapshot load and validation (see
PopulateAndValidateSnapshot()), the new chainstate is not considered active and the
original chainstate remains in use as active.
| number of chainstates | 2 |
| active chainstate | ibd |
Once the snapshot chainstate is loaded and validated, it is promoted to active
chainstate and a sync to tip begins. A new chainstate directory is created in the
datadir for the snapshot chainstate called chainstate_snapshot.
When this directory is present in the datadir, the snapshot chainstate will be detected
and loaded as active on node startup (via DetectSnapshotChainstate()).
A special file is created within that directory, base_blockhash, which contains the
serialized uint256 of the base block of the snapshot. This is used to reinitialize
the snapshot chainstate on subsequent inits. Otherwise, the directory is a normal
leveldb database.
| number of chainstates | 2 |
| active chainstate | snapshot |
The snapshot begins to sync to tip from its base block, technically in parallel with
the original chainstate, but it is given priority during block download and is
allocated most of the cache (see MaybeRebalanceCaches() and usages) as our chief
goal is getting to network tip.
Failure consideration: if shutdown happens at any point during this phase, both chainstates will be detected during the next init and the process will resume.
Snapshot chainstate hits network tip
Once the snapshot chainstate leaves IBD, caches are rebalanced
(via MaybeRebalanceCaches() in ActivateBestChain()) and more cache is given
to the background chainstate, which is responsible for doing full validation of the
assumed-valid parts of the chain.
Note: at this point, ValidationInterface callbacks will be coming in from both chainstates. Considerations here must be made for indexing, which may no longer be happening sequentially.
Background chainstate hits snapshot base block
Once the tip of the background chainstate hits the base block of the snapshot
chainstate, we stop use of the background chainstate by setting m_disabled, in
MaybeCompleteSnapshotValidation(), which is checked in ActivateBestChain()). We hash the
background chainstate's UTXO set contents and ensure it matches the compiled value in
CMainParams::m_assumeutxo_data.
| number of chainstates | 2 (ibd has m_disabled=true) |
| active chainstate | snapshot |
The background chainstate data lingers on disk until the program is restarted.
Bitcoind restarts sometime after snapshot validation has completed
After a shutdown and subsequent restart, LoadChainstate() cleans up the background
chainstate with ValidatedSnapshotCleanup(), which renames the chainstate_snapshot
datadir as chainstate and removes the now unnecessary background chainstate data.
| number of chainstates | 1 |
| active chainstate | ibd (was snapshot, but is now fully validated) |
What began as the snapshot chainstate is now indistinguishable from a chainstate that has been built from the traditional IBD process, and will be initialized as such.
A file will be left in chainstate/base_blockhash, which indicates that the
chainstate, even though now fully validated, was originally started from a snapshot
with the corresponding base blockhash.
Libraries
| Name | Description |
|---|---|
| libbitcoin_cli | RPC client functionality used by bitcoin-cli executable |
| libbitcoin_common | Home for common functionality shared by different executables and libraries. Similar to libbitcoin_util, but higher-level (see Dependencies). |
| libbitcoin_consensus | Consensus functionality used by libbitcoin_node and libbitcoin_wallet. |
| libbitcoin_crypto | Hardware-optimized functions for data encryption, hashing, message authentication, and key derivation. |
| libbitcoin_kernel | Consensus engine and support library used for validation by libbitcoin_node. |
| libbitcoinqt | GUI functionality used by bitcoin-qt and bitcoin-gui executables. |
| libbitcoin_ipc | IPC functionality used by bitcoin-node, bitcoin-wallet, bitcoin-gui executables to communicate when -DWITH_MULTIPROCESS=ON is used. |
| libbitcoin_node | P2P and RPC server functionality used by bitcoind and bitcoin-qt executables. |
| libbitcoin_util | Home for common functionality shared by different executables and libraries. Similar to libbitcoin_common, but lower-level (see Dependencies). |
| libbitcoin_wallet | Wallet functionality used by bitcoind and bitcoin-wallet executables. |
| libbitcoin_wallet_tool | Lower-level wallet functionality used by bitcoin-wallet executable. |
| libbitcoin_zmq | ZeroMQ functionality used by bitcoind and bitcoin-qt executables. |
Conventions
-
Most libraries are internal libraries and have APIs which are completely unstable! There are few or no restrictions on backwards compatibility or rules about external dependencies. An exception is libbitcoin_kernel, which, at some future point, will have a documented external interface.
-
Generally each library should have a corresponding source directory and namespace. Source code organization is a work in progress, so it is true that some namespaces are applied inconsistently, and if you look at
add_library(bitcoin_* ...)lists you can see that many libraries pull in files from outside their source directory. But when working with libraries, it is good to follow a consistent pattern like:- libbitcoin_node code lives in
src/node/in thenode::namespace - libbitcoin_wallet code lives in
src/wallet/in thewallet::namespace - libbitcoin_ipc code lives in
src/ipc/in theipc::namespace - libbitcoin_util code lives in
src/util/in theutil::namespace - libbitcoin_consensus code lives in
src/consensus/in theConsensus::namespace
- libbitcoin_node code lives in
Dependencies
- Libraries should minimize what other libraries they depend on, and only reference symbols following the arrows shown in the dependency graph below:
|
|
Dependency graph. Arrows show linker symbol dependencies. Crypto lib depends on nothing. Util lib is depended on by everything. Kernel lib depends only on consensus, crypto, and util. |
-
The graph shows what linker symbols (functions and variables) from each library other libraries can call and reference directly, but it is not a call graph. For example, there is no arrow connecting libbitcoin_wallet and libbitcoin_node libraries, because these libraries are intended to be modular and not depend on each other's internal implementation details. But wallet code is still able to call node code indirectly through the
interfaces::Chainabstract class ininterfaces/chain.hand node code calls wallet code through theinterfaces::ChainClientandinterfaces::Chain::Notificationsabstract classes in the same file. In general, defining abstract classes insrc/interfaces/can be a convenient way of avoiding unwanted direct dependencies or circular dependencies between libraries. -
libbitcoin_crypto should be a standalone dependency that any library can depend on, and it should not depend on any other libraries itself.
-
libbitcoin_consensus should only depend on libbitcoin_crypto, and all other libraries besides libbitcoin_crypto should be allowed to depend on it.
-
libbitcoin_util should be a standalone dependency that any library can depend on, and it should not depend on other libraries except libbitcoin_crypto. It provides basic utilities that fill in gaps in the C++ standard library and provide lightweight abstractions over platform-specific features. Since the util library is distributed with the kernel and is usable by kernel applications, it shouldn't contain functions that external code shouldn't call, like higher level code targeted at the node or wallet. (libbitcoin_common is a better place for higher level code, or code that is meant to be used by internal applications only.)
-
libbitcoin_common is a home for miscellaneous shared code used by different Bitcoin Core applications. It should not depend on anything other than libbitcoin_util, libbitcoin_consensus, and libbitcoin_crypto.
-
libbitcoin_kernel should only depend on libbitcoin_util, libbitcoin_consensus, and libbitcoin_crypto.
-
The only thing that should depend on libbitcoin_kernel internally should be libbitcoin_node. GUI and wallet libraries libbitcoinqt and libbitcoin_wallet in particular should not depend on libbitcoin_kernel and the unneeded functionality it would pull in, like block validation. To the extent that GUI and wallet code need scripting and signing functionality, they should be get able it from libbitcoin_consensus, libbitcoin_common, libbitcoin_crypto, and libbitcoin_util, instead of libbitcoin_kernel.
-
GUI, node, and wallet code internal implementations should all be independent of each other, and the libbitcoinqt, libbitcoin_node, libbitcoin_wallet libraries should never reference each other's symbols. They should only call each other through
src/interfaces/abstract interfaces.
Work in progress
- Validation code is moving from libbitcoin_node to libbitcoin_kernel as part of The libbitcoinkernel Project #27587
Multiprocess Bitcoin Design Document
Guide to the design and architecture of the Bitcoin Core multiprocess feature
This document describes the design of the multiprocess feature. For usage information, see the top-level multiprocess.md file.
Table of contents
- Introduction
- Current Architecture
- Proposed Architecture
- Component Overview: Navigating the IPC Framework
- Design Considerations
- Security Considerations
- Example Use Cases and Flows
- Future Enhancements
- Conclusion
- Appendices
- Acknowledgements
Introduction
The Bitcoin Core software has historically employed a monolithic architecture. The existing design has integrated functionality like P2P network operations, wallet management, and a GUI into a single executable. While effective, it has limitations in flexibility, security, and scalability. This project introduces changes that transition Bitcoin Core to a more modular architecture. It aims to enhance security, improve usability, and facilitate maintenance and development of the software in the long run.
Current Architecture
The current system features two primary executables: bitcoind and bitcoin-qt. bitcoind combines a Bitcoin P2P node with an integrated JSON-RPC server, wallet, and indexes. bitcoin-qt extends this by incorporating a Qt-based GUI. This monolithic structure, although robust, presents challenges such as limited operational flexibility and increased security risks due to the tight integration of components.
Proposed Architecture
The new architecture divides the existing code into three specialized executables:
bitcoin-node: Manages the P2P node, indexes, and JSON-RPC server.bitcoin-wallet: Handles all wallet functionality.bitcoin-gui: Provides a standalone Qt-based GUI.
This modular approach is designed to enhance security through component isolation and improve usability by allowing independent operation of each module. This allows for new use-cases, such as running the node on a dedicated machine and operating wallets and GUIs on separate machines with the flexibility to start and stop them as needed.
This subdivision could be extended in the future. For example, indexes could be removed from the bitcoin-node executable and run in separate executables. And JSON-RPC servers could be added to wallet and index executables, so they can listen and respond to RPC requests on their own ports, without needing to forward RPC requests through bitcoin-node.
|
| Processes and socket connection. |
Component Overview: Navigating the IPC Framework
This section describes the major components of the Inter-Process Communication (IPC) framework covering the relevant source files, generated files, tools, and libraries.
Abstract C++ Classes in src/interfaces/
- The foundation of the IPC implementation lies in the abstract C++ classes within the
src/interfaces/directory. These classes define pure virtual methods that code insrc/node/,src/wallet/, andsrc/qt/directories call to interact with each other. - Each abstract class in this directory represents a distinct interface that the different modules (node, wallet, GUI) implement and use for cross-process communication.
- The classes are written following conventions described in Internal Interface Guidelines to ensure compatibility with Cap'n Proto.
Cap’n Proto Files in src/ipc/capnp/
- Corresponding to each abstract class, there are
.capnpfiles within thesrc/ipc/capnp/directory. These files are used as input to thempgentool (described below) to generate C++ code. - These Cap’n Proto files (learn more about Cap'n Proto RPC) define the structure and format of messages that are exchanged over IPC. They serve as blueprints for generating C++ code that bridges the gap between high-level C++ interfaces and low-level socket communication.
The mpgen Code Generation Tool
- A central component of the IPC framework is the
mpgentool which is part thelibmultiprocessproject. This tool takes the.capnpfiles as input and generates C++ code. - The generated code handles IPC communication, translating interface calls into socket reads and writes.
C++ Client Subclasses in Generated Code
- In the generated code, we have C++ client subclasses that inherit from the abstract classes in
src/interfaces/. These subclasses are the workhorses of the IPC mechanism. - They implement all the methods of the interface, marshalling arguments into a structured format, sending them as requests to the IPC server via a UNIX socket, and handling the responses.
- These subclasses effectively mask the complexity of IPC, presenting a familiar C++ interface to developers.
- Internally, the client subclasses generated by the
mpgentool wrap client classes generated by Cap'n Proto, and use them to send IPC requests. The Cap'n Proto client classes are low-level, with non-blocking methods that use asynchronous I/O and pass request and response objects, while mpgen client subclasses provide normal C++ methods that block while executing and convert between request/response objects and arguments/return values.
C++ Server Classes in Generated Code
- On the server side, corresponding generated C++ classes receive IPC requests. These server classes are responsible for unmarshalling method arguments, invoking the corresponding methods in the local
src/interfaces/objects, and creating the IPC response. - The server classes ensure that return values (including output argument values and thrown exceptions) are marshalled and sent back to the client, completing the communication cycle.
- Internally, the server subclasses generated by the
mpgentool inherit from server classes generated by Cap'n Proto, and use them to process IPC requests.
The libmultiprocess Runtime Library
- Core Functionality: The
libmultiprocessruntime library's primary function is to instantiate the generated client and server classes as needed. - Bootstrapping IPC Connections: It provides functions for starting new IPC connections, specifically binding generated client and server classes for an initial
interfaces::Initinterface (defined insrc/interfaces/init.h) to a UNIX socket. This initial interface has methods returning other interfaces that different Bitcoin Core modules use to communicate after the bootstrapping phase. - Asynchronous I/O and Thread Management: The library is also responsible for managing I/O and threading. Particularly, it ensures that IPC requests never block each other and that new threads on either side of a connection can always make client calls. It also manages worker threads on the server side of calls, ensuring that calls from the same client thread always execute on the same server thread (to avoid locking issues and support nested callbacks).
Type Hooks in src/ipc/capnp/*-types.h
- Custom Type Conversions: In
src/ipc/capnp/*-types.h, function overloads oflibmultiprocessC++ functions,mp::CustomReadField,mp::CustomBuildField,mp::CustomReadMessageandmp::CustomBuildMessage, are defined. These overloads are used for customizing the conversion of specific C++ types to and from Cap’n Proto types. - Handling Special Cases: The
mpgentool andlibmultiprocesslibrary can convert most C++ types to and from Cap’n Proto types automatically, including interface types, primitive C++ types, standard C++ types likestd::vector,std::set,std::map,std::tuple, andstd::function, as well as simple C++ structs that consist of aforementioned types and whose fields correspond 1:1 with Cap’n Proto struct fields. For other types,*-types.hfiles provide custom code to convert between C++ and Cap’n Proto data representations.
Protocol-Agnostic IPC Code in src/ipc/
- Broad Applicability: Unlike the Cap’n Proto-specific code in
src/ipc/capnp/, the code in thesrc/ipc/directory is protocol-agnostic. This enables potential support for other protocols, such as gRPC or a custom protocol in the future. - Process Management and Socket Operations: The main purpose of this component is to provide functions for spawning new processes and creating and connecting to UNIX sockets.
- ipc::Exception Class: This code also defines an
ipc::Exceptionclass which is thrown from the generated C++ client class methods when there is an unexpected IPC error, such as a disconnection.
|
| Diagram showing generated source files and includes. |
Design Considerations
Selection of Cap’n Proto
The choice to use Cap’n Proto for IPC was primarily influenced by its support for passing object references and managing object lifetimes, which would have to be implemented manually with a framework that only supported plain requests and responses like gRPC. The support is especially helpful for passing callback objects like std::function and enabling bidirectional calls between processes.
The choice to use an RPC framework at all instead of a custom protocol was necessitated by the size of Bitcoin Core internal interfaces which consist of around 150 methods that pass complex data structures and are called in complicated ways (in parallel, and from callbacks that can be nested and stored). Writing a custom protocol to wrap these complicated interfaces would be a lot more work, akin to writing a new RPC framework.
Hiding IPC
The IPC mechanism is deliberately isolated from the rest of the codebase so less code has to be concerned with IPC.
Building Bitcoin Core with IPC support is optional, and node, wallet, and GUI code can be compiled to either run in the same process or separate processes. The build system also ensures Cap’n Proto library headers can only be used within the src/ipc/capnp/ directory, not in other parts of the codebase.
The libmultiprocess runtime is designed to place as few constraints as possible on IPC interfaces and to make IPC calls act like normal function calls. Method arguments, return values, and exceptions are automatically serialized and sent between processes. Object references and std::function arguments are tracked to allow invoked code to call back into invoking code at any time. And there is a 1:1 threading model where every client thread has a corresponding server thread responsible for executing incoming calls from that thread (there can be multiple calls from the same thread due to callbacks) without blocking, and holding the same thread-local variables and locks so behavior is the same whether IPC is used or not.
Interface Definition Maintenance
The choice to maintain interface definitions and C++ type mappings as .capnp files in the src/ipc/capnp/ was mostly done for convenience, and probably something that could be improved in the future.
In the current design, class names, method names, and parameter names are duplicated between C++ interfaces in src/interfaces/ and Cap’n Proto files in src/ipc/capnp/. While this keeps C++ interface headers simple and free of references to IPC, it is a maintenance burden because it means inconsistencies between C++ declarations and Cap’n Proto declarations will result in compile errors. (Static type checking ensures these are not runtime errors.)
An alternate approach could use custom C++ Attributes embedded in interface declarations to automatically generate .capnp files from C++ headers. This has not been pursued because parsing C++ headers is more complicated than parsing Cap’n Proto interface definitions, especially portably on multiple platforms.
In the meantime, the developer guide Internal interface guidelines can provide guidance on keeping interfaces consistent and functional and avoiding compile errors.
Interface Stability
The currently defined IPC interfaces are unstable, and can change freely with no backwards compatibility. The decision to allow this stems from the recognition that our current interfaces are still evolving and not yet ideal for external use. As these interfaces mature and become more refined, there may be an opportunity to declare them stable and use Cap’n Proto's support for protocol evolution (Cap'n Proto - Evolving Your Protocol) to allow them to be extended while remaining backwards compatible. This could allow different versions of node, GUI, and wallet binaries to interoperate, and potentially open doors for external tools to utilize these interfaces, such as creating custom indexes through a stable indexing interface. However, for now, the priority is to improve the interfaces internally. Given their current state and the advantages of using JSON-RPC for most common tasks, it's more practical to focus on internal development rather than external applicability.
Security Considerations
The integration of Cap’n Proto and libmultiprocess into the Bitcoin Core architecture increases its potential attack surface. Cap’n Proto, being a complex and substantial new dependency, introduces potential sources of vulnerability, particularly through the creation of new UNIX sockets. The inclusion of libmultiprocess, while a smaller external dependency, also contributes to this risk. However, plans are underway to incorporate libmultiprocess as a git subtree, aligning it more closely with the project's well-reviewed internal libraries. While adopting these multiprocess features does introduce some risk, it's worth noting that they can be disabled, allowing builds without these new dependencies. This flexibility ensures that users can balance functionality with security considerations as needed.
Example Use Cases and Flows
Retrieving a Block Hash
Let’s walk through an example where the bitcoin-wallet process requests the hash of a block at a specific height from the bitcoin-node process. This example demonstrates the practical application of the IPC mechanism, specifically the interplay between C++ method calls and Cap’n Proto-generated RPC calls.
|
Chain::getBlockHash call diagram
|
-
Initiation in bitcoin-wallet
- The wallet process calls the
getBlockHashmethod on aChainobject. This method is defined as a virtual method insrc/interfaces/chain.h.
- The wallet process calls the
-
Translation to Cap’n Proto RPC
- The
Chain::getBlockHashvirtual method is overridden by theChainclient subclass to translate the method call into a Cap’n Proto RPC call. - The client subclass is automatically generated by the
mpgentool from thechain.capnpfile insrc/ipc/capnp/.
- The
-
Request Preparation and Dispatch
- The
getBlockHashmethod of the generatedChainclient subclass inbitcoin-walletpopulates a Cap’n Proto request with theheightparameter, sends it tobitcoin-nodeprocess, and waits for a response.
- The
-
Handling in bitcoin-node
- Upon receiving the request, the Cap'n Proto dispatching code in the
bitcoin-nodeprocess calls thegetBlockHashmethod of theChainserver class. - The server class is automatically generated by the
mpgentool from thechain.capnpfile insrc/ipc/capnp/. - The
getBlockHashmethod of the generatedChainserver subclass inbitcoin-walletreceives a Cap’n Proto request object with theheightparameter, and calls thegetBlockHashmethod on its localChainobject with the providedheight. - When the call returns, it encapsulates the return value in a Cap’n Proto response, which it sends back to the
bitcoin-walletprocess.
- Upon receiving the request, the Cap'n Proto dispatching code in the
-
Response and Return
- The
getBlockHashmethod of the generatedChainclient subclass inbitcoin-walletwhich sent the request now receives the response. - It extracts the block hash value from the response, and returns it to the original caller.
- The
Future Enhancements
Further improvements are possible such as:
- Separating indexes from
bitcoin-node, and running indexing code in separate processes (see indexes: Stop using node internal types #24230). - Enabling wallet processes to listen for JSON-RPC requests on their own ports instead of needing the node process to listen and forward requests to them.
- Automatically generating
.capnpfiles from C++ interface definitions (see Interface Definition Maintenance). - Simplifying and stabilizing interfaces (see Interface Stability).
- Adding sandbox features, restricting subprocess access to resources and data (see https://eklitzke.org/multiprocess-bitcoin).
- Using Cap'n Proto's support for other languages, such as Rust, to allow code written in other languages to call Bitcoin Core C++ code, and vice versa (see How to rustify libmultiprocess? #56).
Conclusion
This modularization represents an advancement in Bitcoin Core's architecture, offering enhanced security, flexibility, and maintainability. The project invites collaboration and feedback from the community.
Appendices
Glossary of Terms
-
abstract class: A class in C++ that consists of virtual functions. In the Bitcoin Core project, they define interfaces for inter-component communication.
-
asynchronous I/O: A form of input/output processing that allows a program to continue other operations while a transmission is in progress.
-
Cap’n Proto: A high-performance data serialization and RPC library, chosen for its support for object references and bidirectional communication.
-
Cap’n Proto interface: A set of methods defined in Cap’n Proto to facilitate structured communication between different software components.
-
Cap’n Proto struct: A structured data format used in Cap’n Proto, similar to structs in C++, for organizing and transporting data across different processes.
-
client class (in generated code): A C++ class generated from a Cap’n Proto interface which inherits from a Bitcoin Core abstract class, and implements each virtual method to send IPC requests to another process. (see also components section)
-
IPC (inter-process communication): Mechanisms that enable processes to exchange requests and data.
-
ipc::Exception class: A class within Bitcoin Core's protocol-agnostic IPC code that is thrown by client class methods when there is an IPC error.
-
libmultiprocess: A custom library and code generation tool used for creating IPC interfaces and managing IPC connections.
-
marshalling: Transforming an object’s memory representation for transmission.
-
mpgen tool: A tool within the
libmultiprocesssuite that generates C++ code from Cap’n Proto files, facilitating IPC. -
protocol-agnostic code: Generic IPC code in
src/ipc/that does not rely on Cap’n Proto and could be used with other protocols. Distinct from code insrc/ipc/capnp/which relies on Cap’n Proto. -
RPC (remote procedure call): A protocol that enables a program to request a service from another program in a different address space or network. Bitcoin Core uses JSON-RPC for RPC.
-
server class (in generated code): A C++ class generated from a Cap’n Proto interface which handles requests sent by a client class in another process. The request handled by calling a local Bitcoin Core interface method, and the return values (if any) are sent back in a response. (see also: components section)
-
unix socket: Communication endpoint which is a filesystem path, used for exchanging data between processes running on the same host.
-
virtual method: A function or method whose behavior can be overridden within an inheriting class by a function with the same signature.
References
- Cap’n Proto RPC protocol description: https://capnproto.org/rpc.html
- libmultiprocess project page: https://github.com/chaincodelabs/libmultiprocess
Acknowledgements
This design doc was written by @ryanofsky, who is grateful to all the reviewers who gave feedback and tested multiprocess PRs, and everyone else who's helped with this project. Particular thanks to @ariard who deeply reviewed IPC code and improved the design of the IPC library and initialization process. @jnewbery who championed the early refactoring PRs and helped guide them through development and review. @sjors who has reviewed and repeatedly tested multiprocess code, reporting many issues and helping debug them. @hebasto, @fanquake, and @maflcko who made significant improvements to the build system and fixed countless build issues. @vasild and @jamesob who were brave contributors to the libmultiprocess library. And Chaincode Labs for making this work possible. Also thanks to ChatGPT, who actually wrote most of this document (not @ryanofsky).
Transaction Relay Policy
Policy (Mempool or Transaction Relay Policy) is the node's set of validation rules, in addition
to consensus, enforced for unconfirmed transactions before submitting them to the mempool. These
rules are local to the node and configurable, see "Node relay options" when running -help.
Policy may include restrictions on the transaction itself, the transaction
in relation to the current chain tip, and the transaction in relation to the node's mempool
contents. Policy is not applied to transactions in blocks.
This documentation is not an exhaustive list of all policy rules.
Mempool Limits
Definitions
Given any two transactions Tx0 and Tx1 where Tx1 spends an output of Tx0, Tx0 is a parent of Tx1 and Tx1 is a child of Tx0.
A transaction's ancestors include, recursively, its parents, the parents of its parents, etc. A transaction's descendants include, recursively, its children, the children of its children, etc.
A mempool entry's ancestor count is the total number of in-mempool (unconfirmed) transactions in its ancestor set, including itself. A mempool entry's descendant count is the total number of in-mempool (unconfirmed) transactions in its descendant set, including itself.
A mempool entry's ancestor size is the aggregated virtual size of in-mempool (unconfirmed) transactions in its ancestor set, including itself. A mempool entry's descendant size is the aggregated virtual size of in-mempool (unconfirmed) transactions in its descendant set, including itself.
Transactions submitted to the mempool must not exceed the ancestor and descendant limits (aka
mempool package limits) set by the node (see -limitancestorcount, -limitancestorsize,
-limitdescendantcount, -limitdescendantsize).
Exemptions
CPFP Carve Out
CPFP Carve Out if a transaction candidate for submission to the mempool would cause some mempool entry to exceed its descendant limits, an exemption is made if all of the following conditions are met:
-
The candidate transaction is no more than 10,000 virtual bytes.
-
The candidate transaction has an ancestor count of 2 (itself and exactly 1 ancestor).
-
The in-mempool transaction's descendant count, including the candidate transaction, would only exceed the limit by 1.
Rationale: this rule was introduced to prevent pinning by domination of a transaction's descendant limits in two-party contract protocols such as LN. Also see the mailing list post.
This rule was introduced in PR #15681.
Single-Conflict RBF Carve Out
When a candidate transaction for submission to the mempool would replace mempool entries, it may also decrease the descendant count of other mempool entries. Since ancestor/descendant limits are calculated prior to removing the would-be-replaced transactions, they may be overestimated.
An exemption is given for a candidate transaction that would replace mempool transactions and meets all of the following conditions:
-
The candidate transaction has exactly 1 directly conflicting transaction.
-
The candidate transaction does not spend any unconfirmed inputs that are not also spent by the directly conflicting transaction.
The following discounts are given to account for the would-be-replaced transaction(s):
-
The descendant count limit is temporarily increased by 1.
-
The descendant size limit temporarily is increased by the virtual size of the to-be-replaced directly conflicting transaction.
Mempool Replacements
Current Replace-by-Fee Policy
A transaction conflicts with an in-mempool transaction ("directly conflicting transaction") if they spend one or more of the same inputs. A transaction may conflict with multiple in-mempool transactions.
A transaction ("replacement transaction") may replace its directly conflicting transactions and their in-mempool descendants (together, "original transactions") if, in addition to passing all other consensus and policy rules, each of the following conditions are met:
-
(Removed)
-
The replacement transaction only include an unconfirmed input if that input was included in one of the directly conflicting transactions. An unconfirmed input spends an output from a currently-unconfirmed transaction.
Rationale: When RBF was originally implemented, the mempool did not keep track of ancestor feerates yet. This rule was suggested as a temporary restriction.
-
The replacement transaction pays an absolute fee of at least the sum paid by the original transactions.
Rationale: Only requiring the replacement transaction to have a higher feerate could allow an attacker to bypass node minimum relay feerate requirements and cause the network to repeatedly relay slightly smaller replacement transactions without adding any more fees. Additionally, if any of the original transactions would be included in the next block assembled by an economically rational miner, a replacement policy allowing the replacement transaction to decrease the absolute fees in the next block would be incentive-incompatible.
-
The additional fees (difference between absolute fee paid by the replacement transaction and the sum paid by the original transactions) pays for the replacement transaction's bandwidth at or above the rate set by the node's incremental relay feerate. For example, if the incremental relay feerate is 1 satoshi/vB and the replacement transaction is 500 virtual bytes total, then the replacement pays a fee at least 500 satoshis higher than the sum of the original transactions.
Rationale: Try to prevent DoS attacks where an attacker causes the network to repeatedly relay transactions each paying a tiny additional amount in fees, e.g. just 1 satoshi.
-
The number of original transactions does not exceed 100. More precisely, the sum of all directly conflicting transactions' descendant counts (number of transactions inclusive of itself and its descendants) must not exceed 100; it is possible that this overestimates the true number of original transactions.
Rationale: Try to prevent DoS attacks where an attacker is able to easily occupy and flush out significant portions of the node's mempool using replacements with multiple directly conflicting transactions, each with large descendant sets.
-
The replacement transaction's feerate is greater than the feerates of all directly conflicting transactions.
Rationale: This rule was originally intended to ensure that the replacement transaction is preferable for block-inclusion, compared to what would be removed from the mempool. This rule predates ancestor feerate-based transaction selection.
This set of rules is similar but distinct from BIP125.
History
-
Opt-in full replace-by-fee (without inherited signaling) honoured in mempool and mining as of v0.12.0 (PR 6871).
-
BIP125 defined based on Bitcoin Core implementation.
-
The incremental relay feerate used to calculate the required additional fees is distinct from
-minrelaytxfeeand configurable using-incrementalrelayfee(PR #9380). -
RBF enabled by default in the wallet GUI as of v0.18.1 (PR #11605).
-
Full replace-by-fee enabled as a configurable mempool policy as of v24.0 (PR #25353).
-
Full replace-by-fee is the default policy as of v28.0 (PR #30493).
-
Signaling for replace-by-fee is no longer required as of PR 30592.
Package Mempool Accept
Definitions
A package is an ordered list of transactions, representable by a connected Directed Acyclic Graph (a directed edge exists between a transaction that spends the output of another transaction).
For every transaction t in a topologically sorted package, if any of its parents are present
in the package, they appear somewhere in the list before t.
A child-with-unconfirmed-parents package is a topologically sorted package that consists of exactly one child and all of its unconfirmed parents (no other transactions may be present). The last transaction in the package is the child, and its package can be canonically defined based on the current state: each of its inputs must be available in the UTXO set as of the current chain tip or some preceding transaction in the package.
Package Mempool Acceptance Rules
The following rules are enforced for all packages:
-
Packages cannot exceed
MAX_PACKAGE_COUNT=25count andMAX_PACKAGE_WEIGHT=404000total weight (#20833)-
Rationale: We want package size to be as small as possible to mitigate DoS via package validation. However, we want to make sure that the limit does not restrict ancestor packages that would be allowed if submitted individually.
-
Note that, if these mempool limits change, package limits should be reconsidered. Users may also configure their mempool limits differently.
-
Note that this is transaction weight, not "virtual" size as with other limits to allow simpler context-less checks.
-
-
Packages must be topologically sorted. (#20833)
-
Packages cannot have conflicting transactions, i.e. no two transactions in a package can spend the same inputs. Packages cannot have duplicate transactions. (#20833)
-
Only limited package replacements are currently considered. (#28984)
-
Packages are 1-parent-1-child, with no in-mempool ancestors of the package.
-
All conflicting clusters (connected components of mempool transactions) must be clusters of up to size 2.
-
No more than MAX_REPLACEMENT_CANDIDATES transactions can be replaced, analogous to regular replacement rule 5).
-
Replacements must pay more total total fees at the incremental relay fee (analogous to regular replacement rules 3 and 4).
-
Parent feerate must be lower than package feerate.
-
Must improve feerate diagram. (#29242)
-
Rationale: Basic support for package RBF can be used by wallets by making chains of no longer than two, then directly conflicting those chains when needed. Combined with TRUC transactions this can result in more robust fee bumping. More general package RBF may be enabled in the future.
-
-
When packages are evaluated against ancestor/descendant limits, the union of all transactions' descendants and ancestors is considered. (#21800)
- Rationale: This is essentially a "worst case" heuristic intended for packages that are heavily connected, i.e. some transaction in the package is the ancestor or descendant of all the other transactions.
-
CPFP Carve Out is disabled in packaged contexts. (#21800)
- Rationale: This carve out cannot be accurately applied when there are multiple transactions' ancestors and descendants being considered at the same time.
The following rules are only enforced for packages to be submitted to the mempool (not enforced for test accepts):
-
Packages must be child-with-unconfirmed-parents packages. This also means packages must contain at least 2 transactions. (#22674)
-
Rationale: This allows for fee-bumping by CPFP. Allowing multiple parents makes it possible to fee-bump a batch of transactions. Restricting packages to a defined topology is easier to reason about and simplifies the validation logic greatly.
-
Warning: Batched fee-bumping may be unsafe for some use cases. Users and application developers should take caution if utilizing multi-parent packages.
-
-
Transactions in the package that have the same txid as another transaction already in the mempool will be removed from the package prior to submission ("deduplication").
-
Rationale: Node operators are free to set their mempool policies however they please, nodes may receive transactions in different orders, and malicious counterparties may try to take advantage of policy differences to pin or delay propagation of transactions. As such, it's possible for some package transaction(s) to already be in the mempool, and there is no need to repeat validation for those transactions or double-count them in fees.
-
Rationale: We want to prevent potential censorship vectors. We should not reject entire packages because we already have one of the transactions. Also, if an attacker first broadcasts a competing package or transaction with a mutated witness, even though the two same-txid-different-witness transactions are conflicting and cannot replace each other, the honest package should still be considered for acceptance.
-
Package Fees and Feerate
Package Feerate is the total modified fees (base fees + any fee delta from
prioritisetransaction) divided by the total virtual size of all transactions in the package.
If any transactions in the package are already in the mempool, they are not submitted again
("deduplicated") and are thus excluded from this calculation.
To meet the dynamic mempool minimum feerate, i.e., the feerate determined by the transactions evicted when the mempool reaches capacity (not the static minimum relay feerate), the total package feerate instead of individual feerate can be used. For example, if the mempool minimum feerate is 5sat/vB and a 1sat/vB parent transaction has a high-feerate child, it may be accepted if submitted as a package.
Rationale: This can be thought of as "CPFP within a package," solving the issue of a presigned transaction (i.e. in which a replacement transaction with a higher fee cannot be signed) being rejected from the mempool when transaction volume is high and the mempool minimum feerate rises.
Note: Package feerate cannot be used to meet the minimum relay feerate (-minrelaytxfee)
requirement. For example, if the mempool minimum feerate is 5sat/vB and the minimum relay feerate is
set to 5satvB, a 1sat/vB parent transaction with a high-feerate child will not be accepted, even if
submitted as a package.
Rationale: Avoid situations in which the mempool contains non-bumped transactions below min relay feerate (which we consider to have pay 0 fees and thus receiving free relay). While package submission would ensure these transactions are bumped at the time of entry, it is not guaranteed that the transaction will always be bumped. For example, a later transaction could replace the fee-bumping child without still bumping the parent. These no-longer-bumped transactions should be removed during a replacement, but we do not have a DoS-resistant way of removing them or enforcing a limit on their quantity. Instead, prevent their entry into the mempool.
Implementation Note: Transactions within a package are always validated individually first, and package validation is used for the transactions that failed. Since package feerate is only calculated using transactions that are not in the mempool, this implementation detail affects the outcome of package validation.
Rationale: It would be incorrect to use the fees of transactions that are already in the mempool, as we do not want a transaction's fees to be double-counted.
Rationale: Packages are intended for incentive-compatible fee-bumping: transaction B is a "legitimate" fee-bump for transaction A only if B is a descendant of A and has a higher feerate than A. We want to prevent "parents pay for children" behavior; fees of parents should not help their children, since the parents can be mined without the child. More generally, if transaction A is not needed in order for transaction B to be mined, A's fees cannot help B. In a child-with-parents package, simply excluding any parent transactions that meet feerate requirements individually is sufficient to ensure this.
Rationale: We must not allow a low-feerate child to prevent its parent from being accepted; fees of children should not negatively impact their parents, since they are not necessary for the parents to be mined. More generally, if transaction B is not needed in order for transaction A to be mined, B's fees cannot harm A. In a child-with-parents package, simply validating parents individually first is sufficient to ensure this.
Rationale: As a principle, we want to avoid accidentally restricting policy in order to be backward-compatible for users and applications that rely on p2p transaction relay. Concretely, package validation should not prevent the acceptance of a transaction that would otherwise be policy-valid on its own. By always accepting a transaction that passes individual validation before trying package validation, we prevent any unintentional restriction of policy.
RPC Tools
RPCAuth
usage: rpcauth.py [-h] username [password]
Create login credentials for a JSON-RPC user
positional arguments:
username the username for authentication
password leave empty to generate a random password or specify "-" to
prompt for password
optional arguments:
-h, --help show this help message and exit
-j, --json output data in json format
ctaes
Simple C module for constant-time AES encryption and decryption.
Features:
- Simple, pure C code without any dependencies.
- No tables or data-dependent branches whatsoever, but using bit sliced approach from https://eprint.iacr.org/2009/129.pdf.
- Very small object code: slightly over 4k of executable code when compiled with -Os.
- Slower than implementations based on precomputed tables or specialized instructions, but can do ~15 MB/s on modern CPUs.
Performance
Compiled with GCC 5.3.1 with -O3, on an Intel(R) Core(TM) i7-4800MQ CPU, numbers in CPU cycles:
| Algorithm | Key schedule | Encryption per byte | Decryption per byte |
|---|---|---|---|
| AES-128 | 2.8k | 154 | 161 |
| AES-192 | 3.1k | 169 | 181 |
| AES-256 | 4.0k | 191 | 203 |
Build steps
Object code:
$ gcc -O3 ctaes.c -c -o ctaes.o
Tests:
$ gcc -O3 ctaes.c test.c -o test
Benchmark:
$ gcc -O3 ctaes.c bench.c -o bench
Review
Results of a formal review of the code can be found in http://bitcoin.sipa.be/ctaes/review.zip
Internal c++ interfaces
The following interfaces are defined here:
-
Chain— used by wallet to access blockchain and mempool state. Added in #14437, #14711, #15288, and #10973. -
ChainClient— used by node to start & stopChainclients. Added in #14437. -
Node— used by GUI to start & stop bitcoin node. Added in #10244. -
Handler— returned byhandleEventmethods on interfaces above and used to manage lifetimes of event handlers. -
Init— used by multiprocess code to access interfaces above on startup. Added in #19160. -
Ipc— used by multiprocess code to accessInitinterface across processes. Added in #19160.
The interfaces above define boundaries between major components of bitcoin code (node, wallet, and gui), making it possible for them to run in different processes, and be tested, developed, and understood independently. These interfaces are not currently designed to be stable or to be used externally.
src/node/
The src/node/ directory contains code that needs to access node state
(state in CChain, CBlockIndex, CCoinsView, CTxMemPool, and similar
classes).
Code in src/node/ is meant to be segregated from code in
src/wallet/ and src/qt/, to ensure wallet and GUI
code changes don't interfere with node operation, to allow wallet and GUI code
to run in separate processes, and to perhaps eventually allow wallet and GUI
code to be maintained in separate source repositories.
As a rule of thumb, code in one of the src/node/,
src/wallet/, or src/qt/ directories should avoid
calling code in the other directories directly, and only invoke it indirectly
through the more limited src/interfaces/ classes.
This directory is at the moment
sparsely populated. Eventually more substantial files like
src/validation.cpp and
src/txmempool.cpp might be moved there.
This directory contains the source code for the Bitcoin Core graphical user interface (GUI). It uses the Qt cross-platform framework.
The current precise version for Qt 5 is specified in qt.mk.
Compile and run
See build instructions: Unix, macOS, Windows, FreeBSD, NetBSD, OpenBSD
When following your systems build instructions, make sure to install the Qt dependencies.
To run:
./build/src/qt/bitcoin-qt
Files and Directories
forms/
- A directory that contains Designer UI files. These files specify the characteristics of form elements in XML. Qt UI files can be edited with Qt Creator or using any text editor.
locale/
- Contains translations. They are periodically updated and an effort is made to support as many languages as possible. The process of contributing translations is described in doc/translation_process.md.
res/
- Contains graphical resources used to enhance the UI experience.
test/
- Functional tests used to ensure proper functionality of the GUI. Significant changes to the GUI code normally require new or updated tests.
bitcoingui.(h/cpp)
- Represents the main window of the Bitcoin UI.
*model.(h/cpp)
- The model. When it has a corresponding controller, it generally inherits from QAbstractTableModel. Models that are used by controllers as helpers inherit from other Qt classes like QValidator.
- ClientModel is used by the main application
bitcoinguiand several models likepeertablemodel.
*page.(h/cpp)
- A controller.
:NAMEpage.cppgenerally includes:NAMEmodel.handforms/:NAME.page.uiwith a similar:NAME.
*dialog.(h/cpp)
- Various dialogs, e.g. to open a URL. Inherit from QDialog.
paymentserver.(h/cpp)
- (Deprecated) Used to process BIP21 payment URI requests. Also handles URI-based application switching (e.g. when following a bitcoin:... link from a browser).
walletview.(h/cpp)
- Represents the view to a single wallet.
Other .h/cpp files
- UI elements like BitcoinAmountField, which inherit from QWidget.
bitcoinstrings.cpp: automatically generatedbitcoinunits.(h/cpp): BTC / mBTC / etc. handlingcallback.hguiconstants.h: UI colors, app name, etc.guiutil.h: several helper functionsmacdockiconhandler.(h/mm): macOS dock icon handlermacnotificationhandler.(h/mm): display notifications in macOS
Contribute
See CONTRIBUTING.md for general guidelines.
Note: Do not change local/bitcoin_en.ts. It is updated automatically.
Using Qt Creator as an IDE
Qt Creator is a powerful tool which packages a UI designer tool (Qt Designer) and a C++ IDE into one application. This is especially useful if you want to change the UI layout.
Download Qt Creator
On Unix and macOS, Qt Creator can be installed through your package manager. Alternatively, you can download a binary from the Qt Website.
Note: If installing from a binary grabbed from the Qt Website: During the installation process, uncheck everything except for Qt Creator.
macOS
brew install qt-creator
Ubuntu & Debian
sudo apt-get install qtcreator
Setup Qt Creator
- Make sure you've installed all dependencies specified in your systems build instructions
- Follow the compile instructions for your system, adding the
-DCMAKE_BUILD_TYPE=Debugbuild flag - Start Qt Creator. At the start page, do:
New->Import Project->Import Existing Project - Enter
bitcoin-qtas the Project Name and enter the absolute path tosrc/qtas Location - Check over the file selection, you may need to select the
formsdirectory (necessary if you intend to edit *.ui files) - Confirm the
Summarypage - In the
Projectstab, selectManage Kits...
macOS
- Under
Kits: select the default "Desktop" kit - Under
Compilers: select"Clang (x86 64bit in /usr/bin)" - Under
Debuggers: select"LLDB"as debugger (you might need to set the path to your LLDB installation)
Ubuntu & Debian
Note: Some of these options may already be set
- Under
Kits: select the default "Desktop" kit - Under
Compilers: select"GCC (x86 64bit in /usr/bin)" - Under
Debuggers: select"GDB"as debugger
- While in the
Projectstab, ensure that you have thebitcoin-qtexecutable specified underRun
- If the executable is not specified: click
"Choose...", navigate tosrc/qt, and selectbitcoin-qt
- You're all set! Start developing, building, and debugging the Bitcoin Core GUI
Unit tests
The sources in this directory are unit test cases. Boost includes a unit testing framework, and since Bitcoin Core already uses Boost, it makes sense to simply use this framework rather than require developers to configure some other framework (we want as few impediments to creating unit tests as possible).
The build system is set up to compile an executable called test_bitcoin
that runs all of the unit tests. The main source file for the test library is found in
util/setup_common.cpp.
The examples in this document assume the build directory is named
build. You'll need to adapt them if you named it differently.
Compiling/running unit tests
Unit tests will be automatically compiled if dependencies were met during the generation of the Bitcoin Core build system and tests weren't explicitly disabled.
The unit tests can be run with ctest --test-dir build, which includes unit
tests from subtrees.
Run test_bitcoin --list_content for the full list of tests.
To run the unit tests manually, launch build/src/test/test_bitcoin. To recompile
after a test file was modified, run cmake --build build and then run the test again. If you
modify a non-test file, use cmake --build build --target test_bitcoin to recompile only what's needed
to run the unit tests.
To add more unit tests, add BOOST_AUTO_TEST_CASE functions to the existing
.cpp files in the test/ directory or add new .cpp files that
implement new BOOST_AUTO_TEST_SUITE sections.
To run the GUI unit tests manually, launch build/src/qt/test/test_bitcoin-qt
To add more GUI unit tests, add them to the src/qt/test/ directory and
the src/qt/test/test_main.cpp file.
Running individual tests
The test_bitcoin runner accepts command line arguments from the Boost
framework. To see the list of arguments that may be passed, run:
test_bitcoin --help
For example, to run only the tests in the getarg_tests file, with full logging:
build/src/test/test_bitcoin --log_level=all --run_test=getarg_tests
or
build/src/test/test_bitcoin -l all -t getarg_tests
or to run only the doubledash test in getarg_tests
build/src/test/test_bitcoin --run_test=getarg_tests/doubledash
The --log_level= (or -l) argument controls the verbosity of the test output.
The test_bitcoin runner also accepts some of the command line arguments accepted by
bitcoind. Use -- to separate these sets of arguments:
build/src/test/test_bitcoin --log_level=all --run_test=getarg_tests -- -printtoconsole=1
The -printtoconsole=1 after the two dashes sends debug logging, which
normally goes only to debug.log within the data directory, to the
standard terminal output as well.
Running test_bitcoin creates a temporary working (data) directory with a randomly
generated pathname within test_common bitcoin/, which in turn is within
the system's temporary directory (see
temp_directory_path).
This data directory looks like a simplified form of the standard bitcoind data
directory. Its content will vary depending on the test, but it will always
have a debug.log file, for example.
The location of the temporary data directory can be specified with the
-testdatadir option. This can make debugging easier. The directory
path used is the argument path appended with
/test_common bitcoin/<test-name>/datadir.
The directory path is created if necessary.
Specifying this argument also causes the data directory
not to be removed after the last test. This is useful for looking at
what the test wrote to debug.log after it completes, for example.
(The directory is removed at the start of the next test run,
so no leftover state is used.)
$ build/src/test/test_bitcoin --run_test=getarg_tests/doubledash -- -testdatadir=/somewhere/mydatadir
Test directory (will not be deleted): "/somewhere/mydatadir/test_common bitcoin/getarg_tests/doubledash/datadir"
Running 1 test case...
*** No errors detected
$ ls -l '/somewhere/mydatadir/test_common bitcoin/getarg_tests/doubledash/datadir'
total 8
drwxrwxr-x 2 admin admin 4096 Nov 27 22:45 blocks
-rw-rw-r-- 1 admin admin 1003 Nov 27 22:45 debug.log
If you run an entire test suite, such as --run_test=getarg_tests, or all the test suites
(by not specifying --run_test), a separate directory
will be created for each individual test.
Adding test cases
To add a new unit test file to our test suite, you need
to add the file to either src/test/CMakeLists.txt or
src/wallet/test/CMakeLists.txt for wallet-related tests. The pattern is to create
one test file for each class or source file for which you want to create
unit tests. The file naming convention is <source_filename>_tests.cpp
and such files should wrap their tests in a test suite
called <source_filename>_tests. For an example of this pattern,
see uint256_tests.cpp.
Logging and debugging in unit tests
ctest --test-dir build will write to the log file build/Testing/Temporary/LastTest.log. You can
additionally use the --output-on-failure option to display logs of the failed tests automatically
on failure. For running individual tests verbosely, refer to the section
above.
To write to logs from unit tests you need to use specific message methods
provided by Boost. The simplest is BOOST_TEST_MESSAGE.
For debugging you can launch the test_bitcoin executable with gdb or lldb and
start debugging, just like you would with any other program:
gdb build/src/test/test_bitcoin
Segmentation faults
If you hit a segmentation fault during a test run, you can diagnose where the fault
is happening by running gdb ./build/src/test/test_bitcoin and then using the bt command
within gdb.
Another tool that can be used to resolve segmentation faults is valgrind.
If for whatever reason you want to produce a core dump file for this fault, you can do
that as well. By default, the boost test runner will intercept system errors and not
produce a core file. To bypass this, add --catch_system_errors=no to the
test_bitcoin arguments and ensure that your ulimits are set properly (e.g. ulimit -c unlimited).
Running the tests and hitting a segmentation fault should now produce a file called core
(on Linux platforms, the file name will likely depend on the contents of
/proc/sys/kernel/core_pattern).
You can then explore the core dump using
gdb build/src/test/test_bitcoin core
(gdb) bt # produce a backtrace for where a segfault occurred
Description
This directory contains data-driven tests for various aspects of Bitcoin.
License
The data files in this directory are distributed under the MIT software license, see the accompanying file COPYING or https://www.opensource.org/licenses/mit-license.php.
Test library
This contains files for the test library, which is used by the test binaries (unit tests, benchmarks, fuzzers, gui tests).
Generally, the files in this folder should be well-separated modules. New code should be added to existing modules or (when in doubt) a new module should be created.
The utilities in here are compiled into a library, which does not hold any state. However, the main file setup_common
defines the common test setup for all test binaries. The test binaries will handle the global state when they
instantiate the BasicTestingSetup (or one of its derived classes).
This directory contains integration tests that test bitcoind and its utilities in their entirety. It does not contain unit tests, which can be found in /src/test, /src/wallet/test, etc.
This directory contains the following sets of tests:
- fuzz A runner to execute all fuzz targets from /src/test/fuzz.
- functional which test the functionality of bitcoind and bitcoin-qt by interacting with them through the RPC and P2P interfaces.
- util which tests the utilities (bitcoin-util, bitcoin-tx, ...).
- lint which perform various static analysis checks.
The util tests are run as part of ctest invocation. The fuzz tests, functional
tests and lint scripts can be run as explained in the sections below.
Running tests locally
Before tests can be run locally, Bitcoin Core must be built. See the building instructions for help.
The following examples assume that the build directory is named build.
Fuzz tests
See /doc/fuzzing.md
Functional tests
Dependencies and prerequisites
The ZMQ functional test requires a python ZMQ library. To install it:
- on Unix, run
sudo apt-get install python3-zmq - on mac OS, run
pip3 install pyzmq
On Windows the PYTHONUTF8 environment variable must be set to 1:
set PYTHONUTF8=1
Running the tests
Individual tests can be run by directly calling the test script, e.g.:
build/test/functional/feature_rbf.py
or can be run through the test_runner harness, eg:
build/test/functional/test_runner.py feature_rbf.py
You can run any combination (incl. duplicates) of tests by calling:
build/test/functional/test_runner.py <testname1> <testname2> <testname3> ...
Wildcard test names can be passed, if the paths are coherent and the test runner
is called from a bash shell or similar that does the globbing. For example,
to run all the wallet tests:
build/test/functional/test_runner.py test/functional/wallet*
functional/test_runner.py functional/wallet* # (called from the build/test/ directory)
test_runner.py wallet* # (called from the build/test/functional/ directory)
but not
build/test/functional/test_runner.py wallet*
Combinations of wildcards can be passed:
build/test/functional/test_runner.py ./test/functional/tool* test/functional/mempool*
test_runner.py tool* mempool*
Run the regression test suite with:
build/test/functional/test_runner.py
Run all possible tests with
build/test/functional/test_runner.py --extended
In order to run backwards compatibility tests, first run:
test/get_previous_releases.py -b
to download the necessary previous release binaries.
By default, up to 4 tests will be run in parallel by test_runner. To specify
how many jobs to run, append --jobs=n
The individual tests and the test_runner harness have many command-line
options. Run build/test/functional/test_runner.py -h to see them all.
Speed up test runs with a RAM disk
If you have available RAM on your system you can create a RAM disk to use as the cache and tmp directories for the functional tests in order to speed them up.
Speed-up amount varies on each system (and according to your RAM speed and other variables), but a 2-3x speed-up is not uncommon.
Linux
To create a 4 GiB RAM disk at /mnt/tmp/:
sudo mkdir -p /mnt/tmp
sudo mount -t tmpfs -o size=4g tmpfs /mnt/tmp/
Configure the size of the RAM disk using the size= option.
The size of the RAM disk needed is relative to the number of concurrent jobs the test suite runs.
For example running the test suite with --jobs=100 might need a 4 GiB RAM disk, but running with --jobs=32 will only need a 2.5 GiB RAM disk.
To use, run the test suite specifying the RAM disk as the cachedir and tmpdir:
build/test/functional/test_runner.py --cachedir=/mnt/tmp/cache --tmpdir=/mnt/tmp
Once finished with the tests and the disk, and to free the RAM, simply unmount the disk:
sudo umount /mnt/tmp
macOS
To create a 4 GiB RAM disk named "ramdisk" at /Volumes/ramdisk/:
diskutil erasevolume HFS+ ramdisk $(hdiutil attach -nomount ram://8388608)
Configure the RAM disk size, expressed as the number of blocks, at the end of the command
(4096 MiB * 2048 blocks/MiB = 8388608 blocks for 4 GiB). To run the tests using the RAM disk:
build/test/functional/test_runner.py --cachedir=/Volumes/ramdisk/cache --tmpdir=/Volumes/ramdisk/tmp
To unmount:
umount /Volumes/ramdisk
Troubleshooting and debugging test failures
Resource contention
The P2P and RPC ports used by the bitcoind nodes-under-test are chosen to make conflicts with other processes unlikely. However, if there is another bitcoind process running on the system (perhaps from a previous test which hasn't successfully killed all its bitcoind nodes), then there may be a port conflict which will cause the test to fail. It is recommended that you run the tests on a system where no other bitcoind processes are running.
On linux, the test framework will warn if there is another bitcoind process running when the tests are started.
If there are zombie bitcoind processes after test failure, you can kill them by running the following commands. Note that these commands will kill all bitcoind processes running on the system, so should not be used if any non-test bitcoind processes are being run.
killall bitcoind
or
pkill -9 bitcoind
Data directory cache
A pre-mined blockchain with 200 blocks is generated the first time a functional test is run and is stored in build/test/cache. This speeds up test startup times since new blockchains don't need to be generated for each test. However, the cache may get into a bad state, in which case tests will fail. If this happens, remove the cache directory (and make sure bitcoind processes are stopped as above):
rm -rf build/test/cache
killall bitcoind
Test logging
The tests contain logging at five different levels (DEBUG, INFO, WARNING, ERROR
and CRITICAL). From within your functional tests you can log to these different
levels using the logger included in the test_framework, e.g.
self.log.debug(object). By default:
- when run through the test_runner harness, all logs are written to
test_framework.logand no logs are output to the console. - when run directly, all logs are written to
test_framework.logand INFO level and above are output to the console. - when run by our CI (Continuous Integration), no logs are output to the console. However, if a test
fails, the
test_framework.logand bitcoinddebug.logs will all be dumped to the console to help troubleshooting.
These log files can be located under the test data directory (which is always printed in the first line of test output):
<test data directory>/test_framework.log<test data directory>/node<node number>/regtest/debug.log.
The node number identifies the relevant test node, starting from node0, which
corresponds to its position in the nodes list of the specific test,
e.g. self.nodes[0].
To change the level of logs output to the console, use the -l command line
argument.
test_framework.log and bitcoind debug.logs can be combined into a single
aggregate log by running the combine_logs.py script. The output can be plain
text, colorized text or html. For example:
build/test/functional/combine_logs.py -c <test data directory> | less -r
will pipe the colorized logs from the test into less.
Use --tracerpc to trace out all the RPC calls and responses to the console. For
some tests (eg any that use submitblock to submit a full block over RPC),
this can result in a lot of screen output.
By default, the test data directory will be deleted after a successful run.
Use --nocleanup to leave the test data directory intact. The test data
directory is never deleted after a failed test.
Attaching a debugger
A python debugger can be attached to tests at any point. Just add the line:
import pdb; pdb.set_trace()
anywhere in the test. You will then be able to inspect variables, as well as call methods that interact with the bitcoind nodes-under-test.
If further introspection of the bitcoind instances themselves becomes
necessary, this can be accomplished by first setting a pdb breakpoint
at an appropriate location, running the test to that point, then using
gdb (or lldb on macOS) to attach to the process and debug.
For instance, to attach to self.node[1] during a run you can get
the pid of the node within pdb.
(pdb) self.node[1].process.pid
Alternatively, you can find the pid by inspecting the temp folder for the specific test you are running. The path to that folder is printed at the beginning of every test run:
2017-06-27 14:13:56.686000 TestFramework (INFO): Initializing test directory /tmp/user/1000/testo9vsdjo3
Use the path to find the pid file in the temp folder:
cat /tmp/user/1000/testo9vsdjo3/node1/regtest/bitcoind.pid
Then you can use the pid to start gdb:
gdb /home/example/bitcoind <pid>
Note: gdb attach step may require ptrace_scope to be modified, or sudo preceding the gdb.
See this link for considerations: https://www.kernel.org/doc/Documentation/security/Yama.txt
Often while debugging RPC calls in functional tests, the test might time out before the
process can return a response. Use --timeout-factor 0 to disable all RPC timeouts for that particular
functional test. Ex: build/test/functional/wallet_hd.py --timeout-factor 0.
Profiling
An easy way to profile node performance during functional tests is provided
for Linux platforms using perf.
Perf will sample the running node and will generate profile data in the node's
datadir. The profile data can then be presented using perf report or a graphical
tool like hotspot.
To generate a profile during test suite runs, use the --perf flag.
To see render the output to text, run
perf report -i /path/to/datadir/send-big-msgs.perf.data.xxxx --stdio | c++filt | less
For ways to generate more granular profiles, see the README in test/functional.
Util tests
Util tests can be run locally by running build/test/util/test_runner.py.
Use the -v option for verbose output.
Lint tests
See the README in test/lint.
Writing functional tests
You are encouraged to write functional tests for new or existing features. Further information about the functional test framework and individual tests is found in test/functional.
Functional tests
Writing Functional Tests
Example test
The file test/functional/example_test.py is a heavily commented example of a test case that uses both the RPC and P2P interfaces. If you are writing your first test, copy that file and modify to fit your needs.
Coverage
Assuming the build directory is build,
running build/test/functional/test_runner.py with the --coverage argument tracks which RPCs are
called by the tests and prints a report of uncovered RPCs in the summary. This
can be used (along with the --extended argument) to find out which RPCs we
don't have test cases for.
Style guidelines
- Where possible, try to adhere to PEP-8 guidelines
- Use a python linter like flake8 before submitting PRs to catch common style nits (eg trailing whitespace, unused imports, etc)
- The oldest supported Python version is specified in doc/dependencies.md. Consider using pyenv, which checks .python-version, to prevent accidentally introducing modern syntax from an unsupported Python version. The CI linter job also checks this, but possibly not in all cases.
- See the python lint script that checks for violations that could lead to bugs and issues in the test code.
- Use type hints in your code to improve code readability and to detect possible bugs earlier.
- Avoid wildcard imports.
- If more than one name from a module is needed, use lexicographically sorted multi-line imports in order to reduce the possibility of potential merge conflicts.
- Use a module-level docstring to describe what the test is testing, and how it is testing it.
- When subclassing the BitcoinTestFramework, place overrides for the
set_test_params(),add_options()andsetup_xxxx()methods at the top of the subclass, then locally-defined helper methods, then therun_test()method. - Use
f'{x}'for string formatting in preference to'{}'.format(x)or'%s' % x. - Use
platform.system()for detecting the running operating system andos.nameto check whether it's a POSIX system (see also theskip_if_platform_not_{linux,posix}methods in theBitcoinTestFrameworkclass, which can be used to skip a whole test depending on the platform).
Naming guidelines
- Name the test
<area>_test.py, where area can be one of the following:featurefor tests for full features that aren't wallet/mining/mempool, egfeature_rbf.pyinterfacefor tests for other interfaces (REST, ZMQ, etc), eginterface_rest.pymempoolfor tests for mempool behaviour, egmempool_reorg.pyminingfor tests for mining features, egmining_prioritisetransaction.pyp2pfor tests that explicitly test the p2p interface, egp2p_disconnect_ban.pyrpcfor tests for individual RPC methods or features, egrpc_listtransactions.pytoolfor tests for tools, egtool_wallet.pywalletfor tests for wallet features, egwallet_keypool.py
- Use an underscore to separate words
- exception: for tests for specific RPCs or command line options which don't include underscores, name the test after the exact RPC or argument name, eg
rpc_decodescript.py, notrpc_decode_script.py
- exception: for tests for specific RPCs or command line options which don't include underscores, name the test after the exact RPC or argument name, eg
- Don't use the redundant word
testin the name, eginterface_zmq.py, notinterface_zmq_test.py
General test-writing advice
- Instead of inline comments or no test documentation at all, log the comments to the test log, e.g.
self.log.info('Create enough transactions to fill a block'). Logs make the test code easier to read and the test logic easier to debug. - Set
self.num_nodesto the minimum number of nodes necessary for the test. Having additional unrequired nodes adds to the execution time of the test as well as memory/CPU/disk requirements (which is important when running tests in parallel). - Avoid stop-starting the nodes multiple times during the test if possible. A stop-start takes several seconds, so doing it several times blows up the runtime of the test.
- Set the
self.setup_clean_chainvariable inset_test_params()toTrueto initialize an empty blockchain and start from the Genesis block, rather than load a premined blockchain from cache with the default value ofFalse. The cached data directories contain a 200-block pre-mined blockchain with the spendable mining rewards being split between four nodes. Each node has 25 mature block subsidies (25x50=1250 BTC) in its wallet. Using them is much more efficient than mining blocks in your test. - When calling RPCs with lots of arguments, consider using named keyword arguments instead of positional arguments to make the intent of the call clear to readers.
- Many of the core test framework classes such as
CBlockandCTransactiondon't allow new attributes to be added to their objects at runtime like typical Python objects allow. This helps prevent unpredictable side effects from typographical errors or usage of the objects outside of their intended purpose.
RPC and P2P definitions
Test writers may find it helpful to refer to the definitions for the RPC and P2P messages. These can be found in the following source files:
/src/rpc/*for RPCs/src/wallet/rpc*for wallet RPCsProcessMessage()in/src/net_processing.cppfor parsing P2P messages
Using the P2P interface
-
P2Ps can be used to test specific P2P protocol behavior. p2p.py contains test framework p2p objects and messages.py contains all the definitions for objects passed over the network (CBlock,CTransaction, etc, along with the network-level wrappers for them,msg_block,msg_tx, etc). -
P2P tests have two threads. One thread handles all network communication with the bitcoind(s) being tested in a callback-based event loop; the other implements the test logic.
-
P2PConnectionis the class used to connect to a bitcoind.P2PInterfacecontains the higher level logic for processing P2P payloads and connecting to the Bitcoin Core node application logic. For custom behaviour, subclass the P2PInterface object and override the callback methods.
P2PConnections can be used as such:
p2p_conn = node.add_p2p_connection(P2PInterface())
p2p_conn.send_and_ping(msg)
They can also be referenced by indexing into a TestNode's p2ps list, which
contains the list of test framework p2p objects connected to itself
(it does not include any TestNodes):
node.p2ps[0].sync_with_ping()
More examples can be found in p2p_unrequested_blocks.py, p2p_compactblocks.py.
Prototyping tests
The TestShell class exposes the BitcoinTestFramework
functionality to interactive Python3 environments and can be used to prototype
tests. This may be especially useful in a REPL environment with session logging
utilities, such as
IPython.
The logs of such interactive sessions can later be adapted into permanent test
cases.
Test framework modules
The following are useful modules for test developers. They are located in test/functional/test_framework/.
authproxy.py
Taken from the python-bitcoinrpc repository.
test_framework.py
Base class for functional tests.
util.py
Generally useful functions.
p2p.py
Test objects for interacting with a bitcoind node over the p2p interface.
script.py
Utilities for manipulating transaction scripts (originally from python-bitcoinlib)
key.py
Test-only secp256k1 elliptic curve implementation
blocktools.py
Helper functions for creating blocks and transactions.
Benchmarking with perf
An easy way to profile node performance during functional tests is provided
for Linux platforms using perf.
Perf will sample the running node and will generate profile data in the node's
datadir. The profile data can then be presented using perf report or a graphical
tool like hotspot.
There are two ways of invoking perf: one is to use the --perf flag when
running tests, which will profile each node during the entire test run: perf
begins to profile when the node starts and ends when it shuts down. The other
way is the use the profile_with_perf context manager, e.g.
with node.profile_with_perf("send-big-msgs"):
# Perform activity on the node you're interested in profiling, e.g.:
for _ in range(10000):
node.p2ps[0].send_message(some_large_message)
To see useful textual output, run
perf report -i /path/to/datadir/send-big-msgs.perf.data.xxxx --stdio | c++filt | less
See also:
- Installing perf
- Perf examples
- Hotspot: a GUI for perf output analysis
Test Shell for Interactive Environments
This document describes how to use the TestShell submodule in the functional
test suite.
The TestShell submodule extends the BitcoinTestFramework functionality to
external interactive environments for prototyping and educational purposes. Just
like BitcoinTestFramework, the TestShell allows the user to:
- Manage regtest bitcoind subprocesses.
- Access RPC interfaces of the underlying bitcoind instances.
- Log events to the functional test logging utility.
The TestShell can be useful in interactive environments where it is necessary
to extend the object lifetime of the underlying BitcoinTestFramework between
user inputs. Such environments include the Python3 command line interpreter or
Jupyter notebooks running a Python3 kernel.
1. Requirements
- Python3
bitcoindbuilt in the same repository as theTestShell.
2. Importing TestShell from the Bitcoin Core repository
We can import the TestShell by adding the path of the Bitcoin Core
test_framework module to the beginning of the PATH variable, and then
importing the TestShell class from the test_shell sub-package.
>>> import sys
>>> sys.path.insert(0, "/path/to/bitcoin/test/functional")
>>> from test_framework.test_shell import TestShell
The following TestShell methods manage the lifetime of the underlying bitcoind
processes and logging utilities.
TestShell().setup()TestShell().shutdown()
The TestShell inherits all BitcoinTestFramework members and methods, such
as:
TestShell().nodes[index].rpc_method()TestShell().log.info("Custom log message")
The following sections demonstrate how to initialize, run, and shut down a
TestShell object.
3. Initializing a TestShell object
>>> test = TestShell().setup(num_nodes=2, setup_clean_chain=True)
20XX-XX-XXTXX:XX:XX.XXXXXXX TestFramework (INFO): Initializing test directory /path/to/bitcoin_func_test_XXXXXXX
The TestShell forwards all functional test parameters of the parent
BitcoinTestFramework object. The full set of argument keywords which can be
used to initialize the TestShell can be found in section
#6 of this document.
Note: Running multiple instances of TestShell is not allowed. Running a
single process also ensures that logging remains consolidated in the same
temporary folder. If you need more bitcoind nodes than set by default (1),
simply increase the num_nodes parameter during setup.
>>> test2 = TestShell().setup()
TestShell is already running!
4. Interacting with the TestShell
Unlike the BitcoinTestFramework class, the TestShell keeps the underlying
Bitcoind subprocesses (nodes) and logging utilities running until the user
explicitly shuts down the TestShell object.
During the time between the setup and shutdown calls, all bitcoind node
processes and BitcoinTestFramework convenience methods can be accessed
interactively.
Example: Mining a regtest chain
By default, the TestShell nodes are initialized with a clean chain. This means
that each node of the TestShell is initialized with a block height of 0.
>>> test.nodes[0].getblockchaininfo()["blocks"]
0
We now let the first node generate 101 regtest blocks, and direct the coinbase rewards to a wallet address owned by the mining node.
>>> test.nodes[0].createwallet('default')
{'name': 'default', 'warning': 'Empty string given as passphrase, wallet will not be encrypted.'}
>>> address = test.nodes[0].getnewaddress()
>>> test.generatetoaddress(test.nodes[0], 101, address)
['2b98dd0044aae6f1cca7f88a0acf366a4bfe053c7f7b00da3c0d115f03d67efb', ...
Since the two nodes are both initialized by default to establish an outbound
connection to each other during setup, the second node's chain will include
the mined blocks as soon as they propagate.
>>> test.nodes[1].getblockchaininfo()["blocks"]
101
The block rewards from the first block are now spendable by the wallet of the first node.
>>> test.nodes[0].getbalance()
Decimal('50.00000000')
We can also log custom events to the logger.
>>> test.nodes[0].log.info("Successfully mined regtest chain!")
20XX-XX-XXTXX:XX:XX.XXXXXXX TestFramework.node0 (INFO): Successfully mined regtest chain!
Note: Please also consider the functional test
readme, which provides an overview of the
test-framework. Modules such as
key.py,
script.py and
messages.py are particularly
useful in constructing objects which can be passed to the bitcoind nodes managed
by a running TestShell object.
5. Shutting the TestShell down
Shutting down the TestShell will safely tear down all running bitcoind
instances and remove all temporary data and logging directories.
>>> test.shutdown()
20XX-XX-XXTXX:XX:XX.XXXXXXX TestFramework (INFO): Stopping nodes
20XX-XX-XXTXX:XX:XX.XXXXXXX TestFramework (INFO): Cleaning up /path/to/bitcoin_func_test_XXXXXXX on exit
20XX-XX-XXTXX:XX:XX.XXXXXXX TestFramework (INFO): Tests successful
To prevent the logs from being removed after a shutdown, simply set the
TestShell().options.nocleanup member to True.
>>> test.options.nocleanup = True
>>> test.shutdown()
20XX-XX-XXTXX:XX:XX.XXXXXXX TestFramework (INFO): Stopping nodes
20XX-XX-XXTXX:XX:XX.XXXXXXX TestFramework (INFO): Not cleaning up dir /path/to/bitcoin_func_test_XXXXXXX on exit
20XX-XX-XXTXX:XX:XX.XXXXXXX TestFramework (INFO): Tests successful
The following utility consolidates logs from the bitcoind nodes and the
underlying BitcoinTestFramework:
/path/to/bitcoin/test/functional/combine_logs.py '/path/to/bitcoin_func_test_XXXXXXX'
6. Custom TestShell parameters
The TestShell object initializes with the default settings inherited from the
BitcoinTestFramework class. The user can override these in
TestShell().setup(key=value).
Note: TestShell().reset() will reset test parameters to default values and
can be called after the TestShell is shut down.
| Test parameter key | Default Value | Description |
|---|---|---|
bind_to_localhost_only | True | Binds bitcoind P2P services to 127.0.0.1 if set to True. |
cachedir | "/path/to/bitcoin/test/cache" | Sets the bitcoind datadir directory. |
chain | "regtest" | Sets the chain-type for the underlying test bitcoind processes. |
configfile | "/path/to/bitcoin/test/config.ini" | Sets the location of the test framework config file. |
coveragedir | None | Records bitcoind RPC test coverage into this directory if set. |
loglevel | INFO | Logs events at this level and higher. Can be set to DEBUG, INFO, WARNING, ERROR or CRITICAL. |
nocleanup | False | Cleans up temporary test directory if set to True during shutdown. |
noshutdown | False | Does not stop bitcoind instances after shutdown if set to True. |
num_nodes | 1 | Sets the number of initialized bitcoind processes. |
perf | False | Profiles running nodes with perf for the duration of the test if set to True. |
rpc_timeout | 60 | Sets the RPC server timeout for the underlying bitcoind processes. |
setup_clean_chain | False | A 200-block-long chain is initialized from cache by default. Instead, setup_clean_chain initializes an empty blockchain if set to True. |
randomseed | Random Integer | TestShell().options.randomseed is a member of TestShell which can be accessed during a test to seed a random generator. User can override default with a constant value for reproducible test runs. |
supports_cli | False | Whether the bitcoin-cli utility is compiled and available for the test. |
tmpdir | "/var/folders/.../" | Sets directory for test logs. Will be deleted upon a successful test run unless nocleanup is set to True |
trace_rpc | False | Logs all RPC calls if set to True. |
usecli | False | Uses the bitcoin-cli interface for all bitcoind commands instead of directly calling the RPC server. Requires supports_cli. |
This folder contains lint scripts.
Running locally
To run linters locally with the same versions as the CI environment, use the included Dockerfile:
DOCKER_BUILDKIT=1 docker build -t bitcoin-linter --file "./ci/lint_imagefile" ./ && docker run --rm -v $(pwd):/bitcoin -it bitcoin-linter
Building the container can be done every time, because it is fast when the result is cached and it prevents issues when the image changes.
test runner
To run all the lint checks in the test runner outside the docker you first need to install the rust toolchain using your package manager of choice or rustup.
Then you can use:
( cd ./test/lint/test_runner/ && cargo fmt && cargo clippy && RUST_BACKTRACE=1 cargo run )
If you wish to run individual lint checks, run the test_runner with
--lint=TEST_TO_RUN arguments. If running with cargo run, arguments after
-- are passed to the binary you are running e.g.:
( cd ./test/lint/test_runner/ && RUST_BACKTRACE=1 cargo run -- --lint=doc --lint=trailing_whitespace )
To see a list of all individual lint checks available in test_runner, use -h
or --help:
( cd ./test/lint/test_runner/ && RUST_BACKTRACE=1 cargo run -- --help )
Dependencies
| Lint test | Dependency |
|---|---|
lint-python.py | lief |
lint-python.py | mypy |
lint-python.py | pyzmq |
lint-python-dead-code.py | vulture |
lint-shell.py | ShellCheck |
lint-spelling.py | codespell |
py_lint | ruff |
| markdown link check | mlc |
In use versions and install instructions are available in the CI setup.
Please be aware that on Linux distributions all dependencies are usually available as packages, but could be outdated.
Running the tests
Individual tests can be run by directly calling the test script, e.g.:
test/lint/lint-files.py
check-doc.py
Check for missing documentation of command line options.
commit-script-check.sh
Verification of scripted diffs. Scripted diffs are only assumed to run on the latest LTS release of Ubuntu. Running them on other operating systems might require installing GNU tools, such as GNU sed.
git-subtree-check.sh
Run this script from the root of the repository to verify that a subtree matches the contents of the commit it claims to have been updated to.
Usage: test/lint/git-subtree-check.sh [-r] DIR [COMMIT]
test/lint/git-subtree-check.sh -?
DIRis the prefix within the repository to check.COMMITis the commit to check, if it is not provided, HEAD will be used.-rchecks that subtree commit is present in repository.
To do a full check with -r, make sure that you have fetched the upstream repository branch in which the subtree is
maintained:
- for
src/secp256k1: https://github.com/bitcoin-core/secp256k1.git (branch master) - for
src/leveldb: https://github.com/bitcoin-core/leveldb-subtree.git (branch bitcoin-fork) - for
src/crypto/ctaes: https://github.com/bitcoin-core/ctaes.git (branch master) - for
src/crc32c: https://github.com/bitcoin-core/crc32c-subtree.git (branch bitcoin-fork) - for
src/minisketch: https://github.com/sipa/minisketch.git (branch master)
To do so, add the upstream repository as remote:
git remote add --fetch secp256k1 https://github.com/bitcoin-core/secp256k1.git
lint_ignore_dirs.py
Add list of common directories to ignore when running tests